BLOOM — BigScience Large Open-science Open-Access Multilingual Language Model
Here you will find an overview of the Large Language Model (LLM) called BLOOM. What practical implementations exist for BLOOM and the various ways you can access it and what it will cost you.

What is BLOOM?
BLOOM is a large language model, also referred to as a LLM, which can be defined as:
- Language models trained on a vast number of parameters, in the case of BLOOM, 176 billion parameters.
- Results can be achieved with zero-shot or few-shot learning. In other words, astounding results can be achieved with no learning/training, or just a few sentences of instruction.
- LLM’s are resource intensive in terms of hardware capacity, processing and storage.
- Fine-tuning is available, with varying degrees of complexity.
- LLM’s are generally used for generation (aka completion), summarisation, embeddings (clustering and visually representing data), Classification, semantic search and language translation.
Details On BLOOM
Bloom is the world’s largest open-science, open-access multilingual large language model (LLM), with 176 billion parameters, and was trained using the NVIDIA AI platform, with text generation in 46 languages.
BLOOM as a Large Language Model (LLM), is trained to continue and complete text from a prompt. Thus in essence the process of generating text.
Seemingly the words completion, generation and continue are being used interchangeably.
BLOOM is able to generate text in 46 languages and 13 programming languages. The model was trained on vast amounts of text data using industrial-scale computational resources.

How can I Use BLOOM?
Bloom is a generation engine and various options are available for casting tasks…as explained here.
BLOOM cannot be used for embeddings, semantic search or classification per se. However, the real power of BLOOM (apart from it being open sourced and freely available) is text generation in multiple languages.
Text generation can be used in a number of ways…
- Online content, adds, reviews, write-ups can be created via generation.
- BLOOM can be leveraged to perform text tasks it as not explicitly been trained for.
- This can be done by casting tasks as generation.
Here are a few examples of casting…
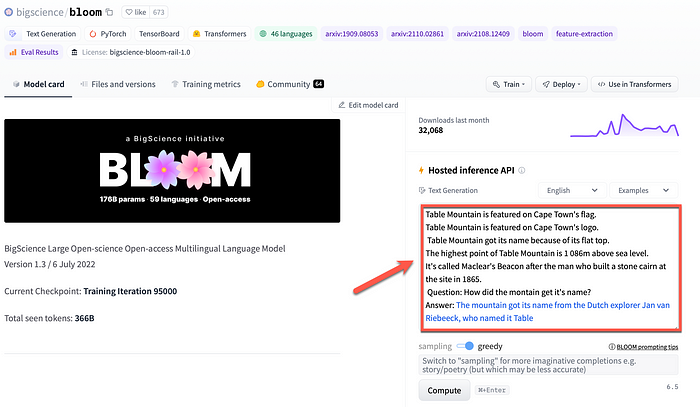
In the example below, BLOOM is used for a type of semantic search. The black text is user input, by which the LLM task is casted as search. The user input is given as context, and a question is asked. The few shot learning lines of input text are ended with the text “Answer:”. Completing the cast if you like.
The black text was entered by me, and the blue text was generated by BLOOM. This generation is premised on the context of the training data I supplied.
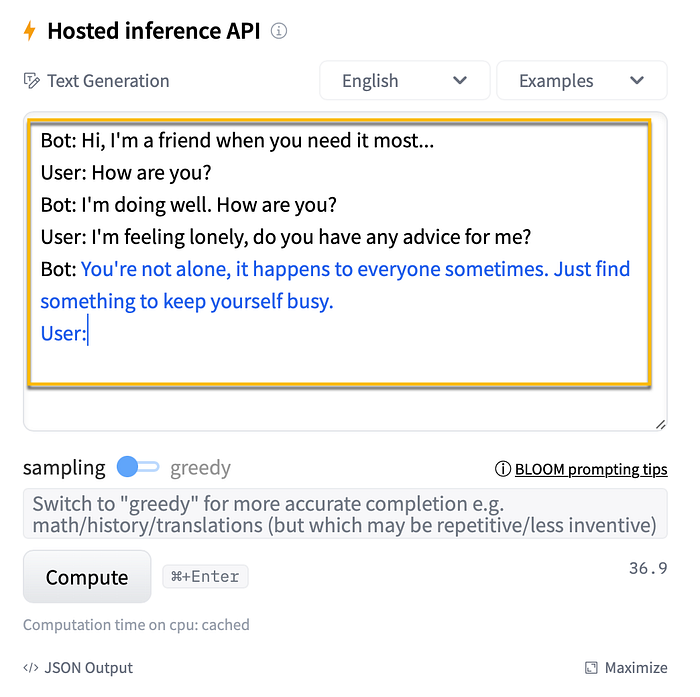
In the example below, a chatbot type of generation cast is performed. With few shot learning data, the text in black is emulating a conversation between a bot and a user. When prompted for a bot response, the bot returns in context, with the blue text.
How Can I Access BLOOM?
The easiest way to access BLOOM is via 🤗Hugging Face, as seen in the image above. You can set the langauge, there are pre-set examples to learn from, and the sampling can be set.
Followed by Spaces…
What are 🤗 Hugging Face spaces?
For AI disciplines like Computer Vision, Audio or in our case NLP (Including LLM’s), spaces are suited to quickly build a demo for a company, or to showcase your product or just to make people aware of your portfolio.
All Spaces are related to your user profile or organisation profile.
For instance, if you want to play with Meta AI’s NLLB model, you can access the model and use it via a space.
Below is a list of BLOOM spaces which are currently available.

Accessing Bloom Via The 🤗Hugging Face Inference API…
Making use of the 🤗Hugging Face inference API is a quick and easy way to move towards a more firm POC or MVP scenario…
The cost threshold is extremely low, you can try the Inference API for free with up to 30,000 input characters per month with community support.
The next step is the Pro Plan at USD 9 per month. Even for a South African this is low 🙂. You get community recognition for that, you can train models easily with AutoTrain, Accelerated Inference API, and most importantly, for Text input tasks:
- 1million free input characters per month
- Followed by $10 per month / 1 million characters on CPU.
- And $50 per month / 1 million characters on GPU
- Pin models for instant availability
- Community support
You can read about inference API’s here. The complete documentation can be found here.
In Conclusion
With Large Language Models (LLM’s) there are a few considerations:
- The demands of hosting and processing, this is a given. But edge installations will become more important and this will be an area of giant leaps in the near future.
- Fine tuning is still lagging. LLM’s do have a unique ability in the areas of zero and few shot learning. But there is a need for advanced no-code to low-code fine-tuning.
- Open source is good, but you will need hosting (disk space and processing), services, API’s, etc. These will cost money, no LLM is “free”.
- LLM’s will be used for generation (completion), embeddings (clustering), semantic search, entity extraction and more.
Current existing areas of differentiation available within the LLM space are:
- A no-code to low-code fine-tuning GUI environment to create custom models. You can see this as a third iteration, going from zero shot, to few shot, to fine-tuning.
- Somewhat related to point one, but a studio environment via which the LLM can be implemented and managed. The integration of HumanFirst Studio and Cohere is a vision of the future.
- Competing with Large Langauge Models are futile, the best is to seek out opportunities to leverage and add value with LLM’s.
- The is an opportunity for companies to host these open-source LLM’s and present them to users at really low costs.
- Services and products related to, and leveraging LLM’s. AI21labs is doing a good job in inventing use-cases and real-world applications.
- Geographic and regional dispersed availability zones seem to be a logical next step for LLM implementations in order to negate latency, etc.
