Using OpenAI Embeddings For Search & Clustering
Here Are A Few Practical Implementations For Chatbots

Introduction
Companies building Large Language Models are exploring avenues to find their way into practical production implementations.
The OpenAI playground does well to demonstrate OpenAI’s capability in numerous language related tasks, of which I have written extensively in the recent past.
Apart from their Playground, OpenAI has four suggested areas for building an application using their Large Language Models, as seen below…

- Code Completion: I have prototyped and written extensively on Codex and how it can be implemented in applications and real-world scenarios.
- Fine-tuning: On 13 July 2021 OpenAI enabled fine-tuning.
- Text completion: Recently I wrote on bootstrapping a chatbot with text completion and generative models.
- Embeddings: In this article I am focussing on Embeddings with two practical implementation use-cases.
More On Embeddings
Embeddings are extremely useful for chatbot implementations, and in particular search and topic clustering.
The concept of Embeddings can be abstract, but suffice to say an embedding is an information dense representation of the semantic meaning of a piece of text.
Considering the five Conversational AI technologies which are part of the Garner Hype Cycle, Semantic Search is the most advanced in the cycle.
Also, Semantic Search finds itself at the inception of the slope of enlightenment on the Gartner Hype Cycle for AI.

Above marked in red are two embeddings which are probably the most applicable to Conversational AI and chatbots. These are clustering and semantic search.
Semantic Search
What makes Semantic Search different and valuable from a chatbot perspective, is that semantic search leverages the intent and contextual meaning of words.
This is obviously more effective than searching for literal matches of a word, or multiple words or variations of the word; and not taking into consideration the overall meaning of the query.
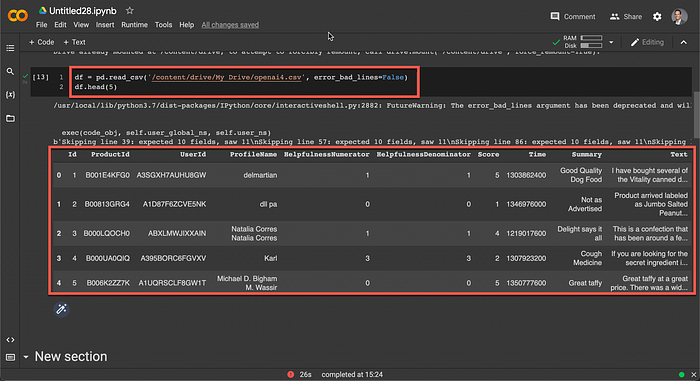
In the notebook example below, a CSV file with 1,000 records of product reviews are used. In the image below you can see the fields of the CSV file, with most importantly the summary and text of the product review.
We can search through all the reviews semantically in a very efficient manner and at very low cost, by simply embedding the search query, and then finding the most similar reviews.
After the embeddings are created and saved for future use, it can be used to perform semantic searches on our CSV file with product reviews.
Below is a very applicable example, when searching for “pet food” with the command:
res = search_reviews(df, 'pet food', n=2)The reviews returned are pet food related, containing the intent of pet food. But the phrase “pet food” does not exist in the text searched.
Good food: The only dry food my queen cat will eat. Helps prevent hair balls. Good packaging. Arrives promptly. Recommended by a friend who sells pet food.
A great deal on Greenies: Paid only $22 with free shipping for 96 teenies compared to about $35 at the pet store. How can you go wrong with a deal like that? The dog begs for his daily Greenie.The advantages of semantic search for Conversational AI is obviously significant. There are a few approaches how Semantic Search can be implemented in chatbots.
The first approach is by taking a body of knowledge, very much like the product review CSV file examples, and breaking the information down into a few sentence or utterances which are related. When a user enters a sentence, the grouping of utterances/paragraphs are searched and the utterance which is semantically most correct is returned.
Clustering
Clustering is used to discover valuable, hidden groupings of semantically similar sentences within bodies of data.
Imagine you have thousands of user utterances or long lists of facts. By making use of clusters, this data can be grouped with varying granularity and sizes, into clusters/groupings which are semantically similar.
Clusters can be shown in text, but clustering also lends itself well to be visually represented.
Below you can see four random clusters, each containing a theme or description with the relevant cluster/grouping of user utterances or sentences.
It is obvious that these themes are in essence intents and the clustering of sentences are analogous to training examples for intents.
Cluster 0 Theme: All of the customer reviews mention the great flavor of the product.
5, French Vanilla Cappuccino: Great price. Really love the the flavor. No need to add anything to 5, great coffee: A bit pricey once you add the S & H but this is one of the best flavor5, Love It: First let me say I'm new to drinking tea. So you're not getting a well
--------------------------------------------------------------------
Cluster 1 Theme: All three reviews mention the quality of the product.
5, Beautiful: I don't plan to grind these, have plenty other peppers for that. I go
5, Awesome: I can't find this in the stores and thought I would like it. So I bou
5, Came as expected: It was tasty and fresh. The other one I bought was old and tasted mold
----------------------------------------------------------------------------------------------------
Cluster 2 Theme: All reviews are about customer's disappointment.
1, Disappointed...: I should read the fine print, I guess. I mostly went by the picture a
5, Excellent but Price?: I first heard about this on America's Test Kitchen where it won a blin
1, Disappointed: I received the offer from Amazon and had never tried this brand before
----------------------------------------------------------------------------------------------------
Cluster 3 Theme: The reviews for these products have in common that the customers' dogs love them.
5, My Dog's Favorite Snack!: I was first introduced to this snack at my dog's training classes at p
4, Fruitables Crunchy Dog Treats: My lab goes wild for these and I am almost tempted to have a go at som
5, Happy with the product: My dog was suffering with itchy skin. He had been eating Natural Choi
----------------------------------------------------------------------------------------------------
Clustering can be used as an avenue to reverse-engineer the creation of intents and organising training data.
Via clustering, Intents can be derived from sentences, user utterances, facts or any other text data.
And Lastly
When people consider technologies like chatbot frameworks versus LLM’s versus NLP versus Knowledge Bases, it is often a one-or-the-other approach.
It is evident that there is an overlap of these technologies already. For instance, auto-completion is a form of generation, intent overlap detection, or intent suggestions based on imported user utterances is another example clustering and unsupervised learning.
And I foresee that there will be a proliferation of the overlapping technologies.
In conclusion, there are other avenues to explore datasets using semantic search and clustering without having to write code and manage a highly technical Python environment. A no-code tool like HumanFirst is much faster and more powerful.
Currently HumanFirst has integration to the Co:here Large Language Model (LLM) embeddings, hence the Co:here embeddings can be managed and fully leveraged via HumanFirst.
It does seem as if integration between OpenAI and HumanFirst will be available soon.
