Large Language Models Are Being Open-Sourced
And The Cost Of Hosted Solutions Are Coming Down

Introduction
Large Language Models (LLM’s) have received much attention of late, with Co:here, OpenAI and AI21Labs being the big commercial offerings.
There are also solutions like Botpress’ OpenBook that leverages large language models in order to bootstrap a chatbot implementation.
And recently I have written about and shared an architecture for bootstrapping a chatbot with LLM’s.
But what are the advantages of LLM’s?
Why Use A Large Language Model?
The unique differentiators of Large language Models (LLM’s) are:
- Fine-tuned models allow for LLM’s to be customised to some degree to specific user data. This isn’t specific to LLM’s, but the LLM providers make it easier to use than fine tuning your own models locally.
- These LLM’s focus on keeping complexity under the hood, and surface functionality in a very simplistic way.
- Playgrounds are available with example use-cases to get users off to a running start.
- Zero-shot learning is employed to make accurate predictions and analysis without any prior training. This in of itself is astounding in question answering, general chatbots, sentence completion, summarisation, key word extraction and most of all Natural Language Generation.
- Few-shot learning is available where a very small number of examples or a short description is given as training data.
- Flexibility is available via fine-tuning functionality. Read more about OpenAI Language API fine-tuning here. Co:here also has fine-tuning capability, the NLG fine-tuning in specific is impressive. Text classification fine-tuning is also available.
- LLM’s can be used in the process of creating the chatbot, supporting good copy writing, summarising bot responses in a knowledge base scenario, etc.
- There is so much information embedded in LLM’s, that it can be used to search, and find information instead of traditional search engines.
Language Models & Large Language Models
Position language models with regard to large language models…
Language modelling usually refers to the type of supervision objective used during training.
In a masked language model, the algorithm tries to predict words that have been removed from a sentence (BERT and its variants use this technique).
In a causal language model (like GPT3 and other LLM’s) it always tries to predict the next token given the previous context — this makes them good candidates for generating text.
Fine tuning refers to taking an existing model and training it further based on a (potentially) different objective. It can be a mix of causal language modelling and classification, for example.
This is one of Huggingface’s biggest value propositions, you can take existing models, fine tune them with your data and publish them for other people to use.
It allows for specialising a general purpose model into something domain-specific. LegalBERT, for example, is a BERT model trained on legal documents.
Open-Source LLM’s
A number of LLM’s have been open-sourced, and this begs the question…
Is it becoming easier and viable for more competitors to enter into the LLM services space? Where open-source LLM’s are leveraged, by hosting the models and making it available as a service?
And how sustainable are some of the current, more expensive LLM offerings? Are the differentiators worth the expense?
Goose AI
Take Goose AI as a case in point, with their fully managed NLP-as-a-Service delivered via API…all at 30% of the cost, according to Goose AI.
Goose AI’s commercial offering backed by Eleuther.AI which is a group of researchers working on LLM’s, which also release their models publicly.
They see themselves comparable to OpenAI in some regards and makes migration easy.
Below you see the models available and the cost per model…
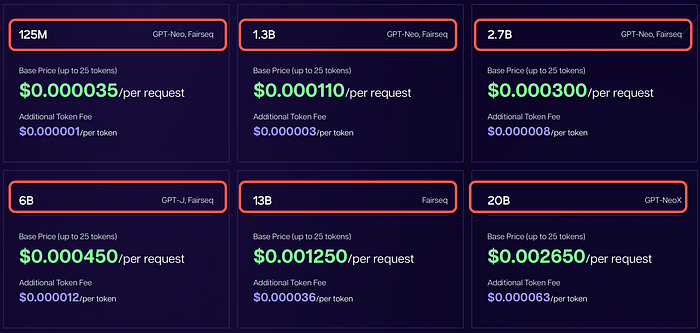
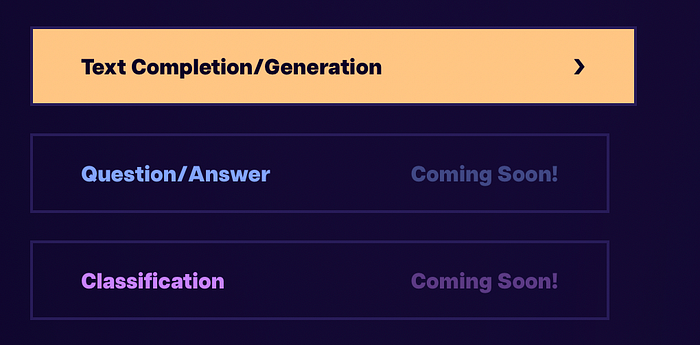
Currently only Text Completion / Generation is available, and can be accessed via the Goose AI playground as seen below. This example shows a list of facts submitted to Goose AI’s generation model, with a question. The answer to the question is generated contextually based on the facts supplied.

Features to follow are Question and Answer, with Classification, as seen below.
In Conclusion
Considering LLM’s the approach currently is to have a playground, and from here launch into Python notebooks.
There is a definite and dire need for a no-code studio approach. Where a user can connect to LLM’s from a GUI, and leverage these large language models to perform tasks like…
- Clustering for intent detection and improvements
- Defining and extracting entities
- And semantic search
A kind of a no-code orchestration layer, from where an NLU API can be created with easy management.
