
Analysis Of The Co:here and HumanFirst Integration
And How LLMs Can Be Leveraged In NLU Work-Streams

Introduction
HumanFirst has built a POC last week, which replaces the HumanFirst NLU embeddings with Co:here embeddings.
After prototyping and testing with two datasets…the following was evident:
- Co:here tends to have a limited number of matching intents with a definite single high-confidence intent. HumanFirst NLU had a number of false positives, yet still matching Co:here in relevant intents.
- The small Co:here model was used, speeds were comparable, with no noticeable degradation in performance on the HumanFirst Studio.

- Within HumanFirst Studio, the integration is seamless and unnoticeable from a user perspective. This speaks to the current notion to manage complexity under the hood and surface simplicity.
- The HumanFirst Studio is exceptional in managing NLU training data, at scale.
- Many ask about Large Language Model (LLMs) use-cases and implementation in the real-world, this combination of Co:here and HumanFirst is a case in point.
- Co:here has higher confidence percentages than HumanFirst NLU in queries.
- HumanFirst NLU has a wider distribution of confidence over other relevant intents, hence more false positives. But these are still very useful, as I will explain later…
- Where training data is sparse, Co:here can be well leveraged for more accurate results.
- This is a good implementation and use case of embeddings and intent detection at scale, semantic search and clustering.
- HumanFirst shows it versatility in being a connection between LLM’s and Conversational AI frameworks.
NLU API Testing
For this test I made use of customer care example data (user utterances) which has 1,000 customer utterances, from which I created five intents. The same process was performed for the Co:here and HumanFirst NLU workspaces.
The HumanFirst Studio has a section where the NLU API can be queried in a GUI and the API request copied out for use in a Notebook or something like Postman.

Having trained the NLU for both the Co:here and HumanFirst NLU workspaces, the same slightly ambiguous sentence is submitted to both NLU endpoints within the HumanFirst Studio.
The same trend continues where Co:here has a high confidence and HumanFirst have slightly lower confidence, and bringing two other intents into play (false positives).
The other two intents have low confidences, but are highly relevant.
NLU API Results From The Banking Example
Here, to test accuracy on a larger set of data, I created a workspace with a HuggingFace dataset of 3,083 customer service queries, labeled with 77 intents.
This data was uploaded and a NLU endpoint was trained on both Co:here and HumanFirst NLU.
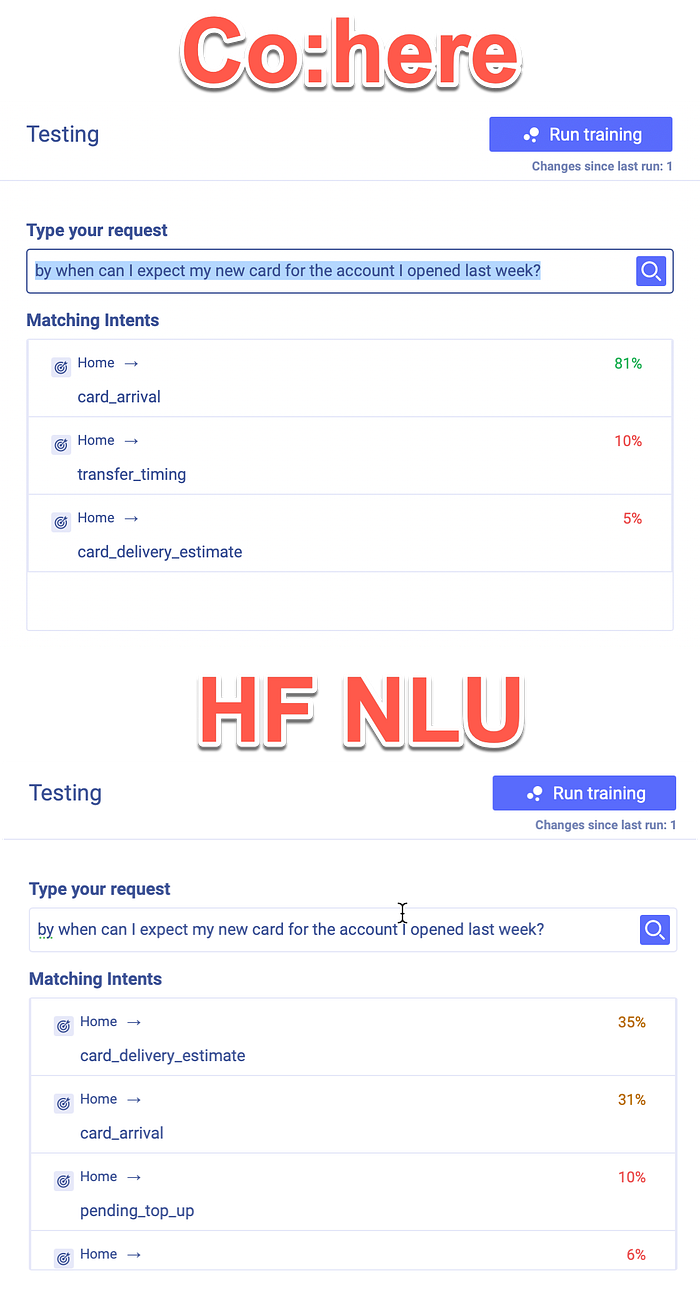
Again I made use of a highly ambiguous utterance asking about expected delivery time and having opened an account.
As expected, Co:here gave the highest score to a single intent card_arrival, which is not wrong.
But the intent card_delivery_estimate feels more accurate to the utterance.
From here the same trend continues with HumanFirst having the confidence spread out over more intents; false positives.
Within HumanFirst Studio, the results from the NLU endpoint can be selected and the interface moves its focus to the intent management section, where the training data can be reviewed.
The HumanFirst Studio
All work was performed within the HumanFirst Studio. The utterances can be imported in a single line text format, clustering is virtually instant for both Co:here and HumanFirst NLU.
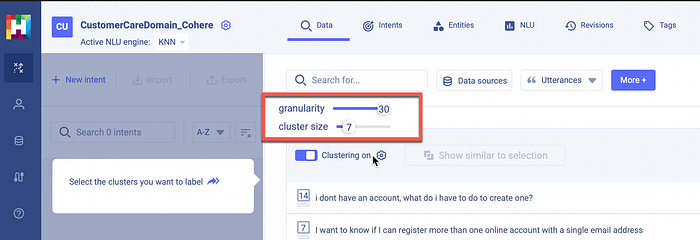
For both workspaces I imported the exact same 1,000 customer utterances. Also, both workspaces were set to a granularity of 30 and cluster size of 7, as seen above. The granularity and cluster size can be dialled up or down and the data rapidly rearranges accordingly.
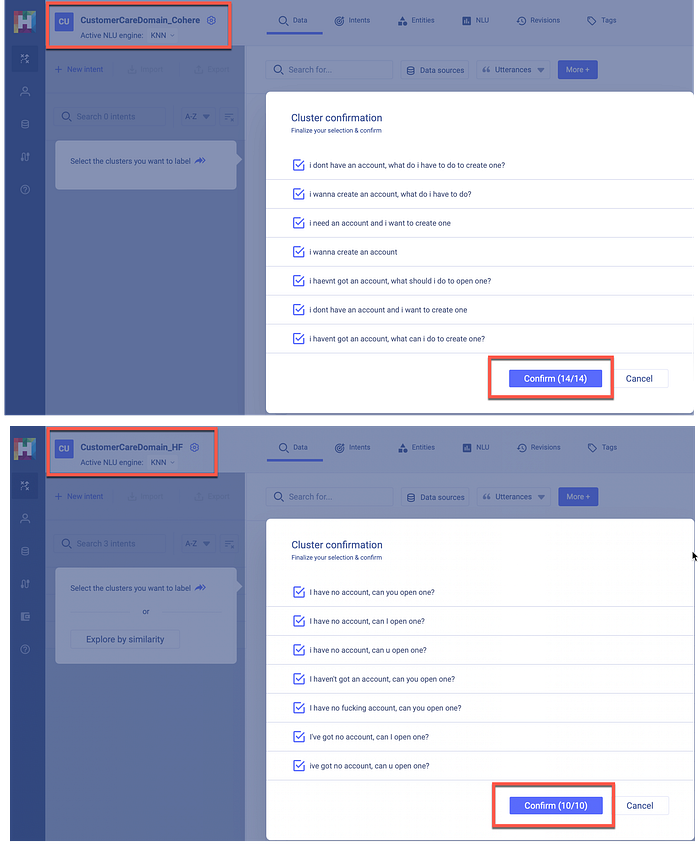
As seen above, on average the cluster sizes of the Co:here workspace were bigger than those of the HumanFirst NLU workspace . It seemed as if the HumanFirst NLU was slightly more granular than the co:here small model.
The Co:here based instance has bigger clusters and the accuracy from studying the data seems good. This could point to less work in cleaning up loose ends towards the end.
Intent Prediction — Utterance Clustering
The following few examples look at intent prediction, where a set of user utterances, which the models clustered, are selected. A list of intents are subsequently given, with confidence scores for each intent, the next step is to assign the utterances to an existing intent. Or create a new intent or nested intent for assignment.

As seen above, during the process of selecting utterances both Co:here and HumanFirst NLU suggested the same and closest existing intent.
In this case above, the more accurate intent would be CreateNewOnlineAccount Intent, which I subsequently created.
But a trend is evident here where Co:here is very confident in its prediction, with a very high score for the best match. So in this instance one could argue Co:here is more accurate, but I like the spread of relevant intents (false positives)from HumanFirst NLU which quite useful in conversation design.
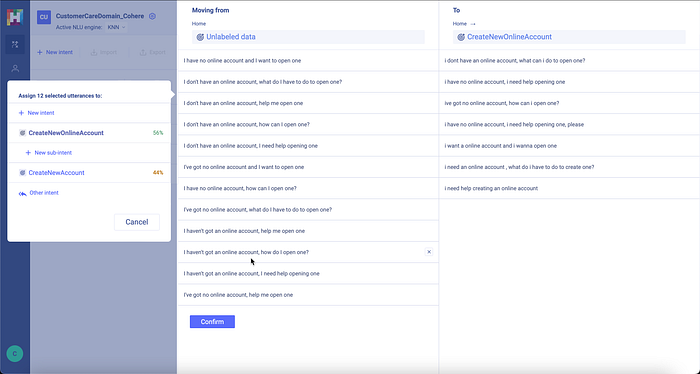
This is not related to the Co:here integration, but the feature of moving utterances to an existing intent gives a good overview of what data will be moved over to an existing intent.
Benchmarking
Within HumanFirst Studio, not only can the NLU API be queried within the GUI, but detailed evaluations can be run. Evaluations can be K-fold or a test data sample.
“K-Fold” randomly selects train and test sets from your data, each time using a single fold as the test set and the remainder as the train set.
For example, a 5-fold test performs 5 tests in which it each trains on 4/5 of the training data, and test on the remaining 1/5.This is the recommended approach for evaluating a model’s performance.
There will be instances where utterances need to be tagged for use during evaluation. This might be when a new product or service is launched, or the bot extends into a new department or field within an organisation.
Read more about Accuracy, Precision, Recall and F1 here…
Two K Fold evaluations were performed, on both the Co:here and HumanFirst NLU API. The results from both evaluations, which included all 77 intents from the HuggingFace dataset are exactly the same; for the averages.
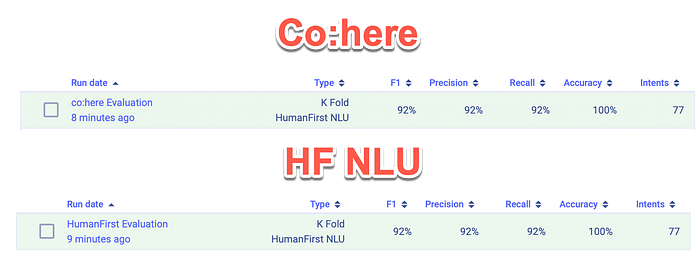
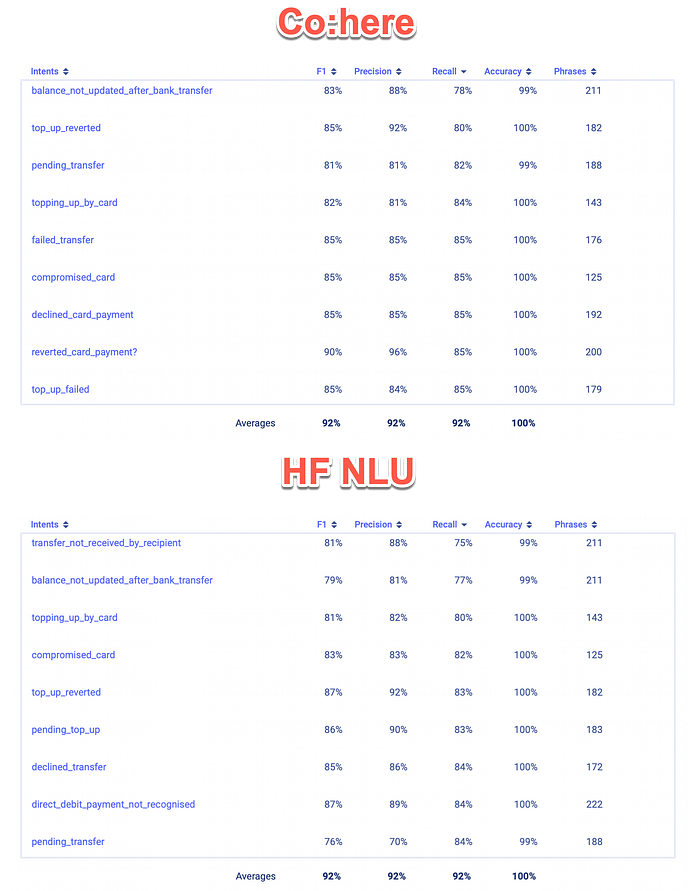
Looking at the score breakdown per intent, there is quite a difference in results, especially for Recall, F1 and Precision. It would make sense in a production environment to examine the intents and the training examples per intent, to understand how to improve the model.
Within HumanFirst different evaluations can also be compared to each-other.
Conclusion
The accuracy and confidence of the Co:here embeddings are more accurate in general, but there are instances where the HumanFirst NLU performs better.
The HumanFirst NLU has more false positives, but these less relevant intents can be used in conversation design for disambiguation, etc.
Training Dataset for chatbots/Virtual Assistants
Training your customer service chatbot
www.kaggle.com
