How Will OpenAI Whisper Impact Current Commercial ASR Solutions?
Here I consider implications for commercial ASR’s, English accuracy of Whisper and minor language precision.

Does Whisper Spell The End For Current Commercial ASR’s?
Whisper is immensely impressive in zero-shot transcription of audio to text with high accuracy; and it’s open-sourced…but…
Does Whisper spell the end for Current Commercial ASR’s?
The short answer to this question is…no.
And I say this for good reason…
Whisper is focussed on zero-shot asynchronous transcription.
One of the key implementations of ASR is a realtime synchronous voicebot, where latency needs to be < 500 milliseconds and any silence on the call amounts to a poor customer experience. Whisper is focussed on asynchronous implementations and will most probably be used in an offline capacity to process recordings after the fact.
Real-time synchronous transcription is not a focus area of Whisper, for now…
Another consideration is that Whisper is focussed on zero-shot transcription (speech to text) without any option to make use of fine-tuning or acoustic models. I have written extensively in the past on the importance of fine-tuning ASR by adding an acoustic model to address areas like speaker age, gender, ethnicity, accents, slang, product names, service descriptions and more…
Hence any commercial ASR focussing on latency, local installations and fine-tuning will be sure to pip Whisper at the post.
Most corporates ask for private cloud installations, or at least regional/geographic presence. Though Whisper is open-sourced, cost will always be a consideration. The cost per API call when using a hosted / inference API, or hosting and processing costs when self-hosting…add to self-hosting the technical expertise required.
When compared to humans, the models approach their accuracy and robustness.
~ OpenAI

* In this article the terms Automatic Speech Recognition (ASR) & Speech-To-Text (STT) are used interchangeably.
Please follow me on LinkedIn for the latest updates on Conversational AI. 🙂
ASR, Voicebots & NLU Design
I recently wrote about the idea of NLU Design.
If I had to describe NLU Design in one sentence, I would say:
NLU Design is an end-to-end methodology to transform unstructured data into highly accurate and custom NLU.
I have learned a few valuable lessons from launching a voicebot…
The one thing I learned the hard way is that ASR transcriptions which are inaccurate makes NLU Design very hard. If there are too many variations in transcription for the same words or phrases it becomes difficult to manage intent overlaps.
The initial approach was to not fine-tune the ASR and absorb the transcription variations within the NLU Design process…Eventually I found the variations too big. The unstructured conversational data must be at least somewhat semantically similar to the intent of the caller.
So we resorted to implementing fine-tuning via acoustic models. A daily cadence was implemented to manage and improve the WER and ensure those gains are incorporated into our NLU Design cadence.

The image above gives a synopsis of how WER is calculated…you can read more about the process here…
Voicebots are indeed a synchronous implementation, however, giving some consideration to asynchronous use-cases…
I would definitely want to try Whisper for conversational data exploration and subsequent semantic clustering. Using Whisper to bulk transcribe recordings into text, and subsequently explore that text via a data-centric latent space will yield interesting results. This means that other sources of audio can be leveraged to enrich any conversational AI implementation.
How Accurate Is The English Transcription?
It is accurate, very accurate!
The accuracy of Whisper can be determined in two ways…
The first is just by experimenting via one of the numerous 🤗HuggingFace spaces and judging the transcription quality. Spaces are a good playground for experimentation and to get a feel for where the accuracy is at.
OpenAI states that Whisper approaches human level of robustness and accuracy on English speech recognition. OpenAI makes it clear that they want Whisper to be judged on how well humans would have transcribed the audio…so from a usability standpoint, Whisper’s accuracy is astounding.
The second measure of accuracy is WER…
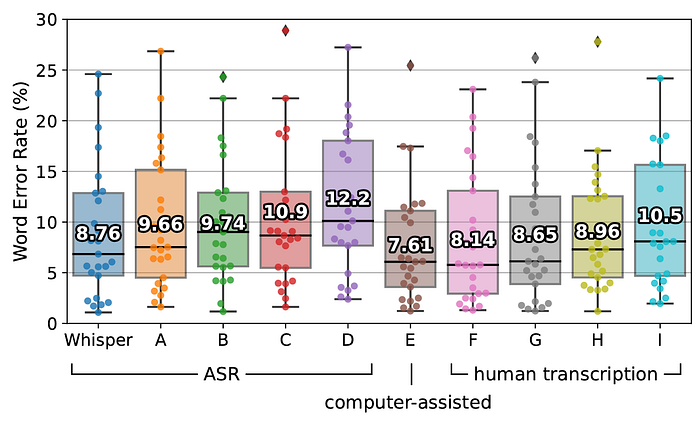
The diagram below shows the WER distributions of 25 recordings transcribed by Whisper, and 4 commercial ASR systems A to D. With one computer-assisted human transcription service (E) and 4 human transcription services (F to I).
The box plot is superimposed with dots indicating the WERs on individual recordings, and the aggregate WER over the 25 recordings are annotated on each box.
These results indicate that Whisper’s English ASR performance is not perfect but very close to human-level accuracy.
The goal of a speech recognition system should be to work reliably “out of the box” in a broad range of environments without requiring supervised fine-tuning of a decoder for every deployment distribution.
~ OpenAI
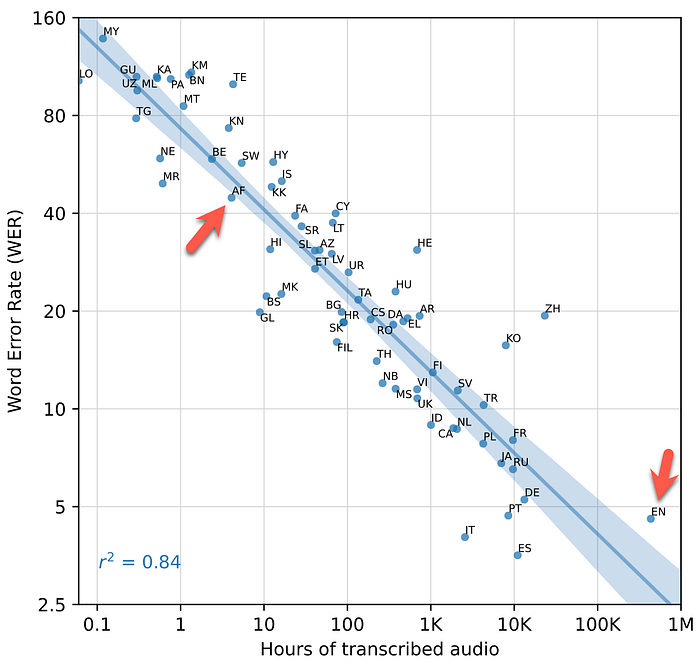
The image below shows clearly the correlation between the amount of training data and the recognition accuracy performance (WER).
Marked in the bottom right is the English langauge with < 5 WER which is truly exceptional.
Also marked is the Afrikaans language with much fewer training data, but a WER > 40. My personal view is that any WER which is > 20 will impact NLU design negatively.
Please follow me on LinkedIn for the latest updates on Conversational AI. 🙂
Minor Langauge Precision
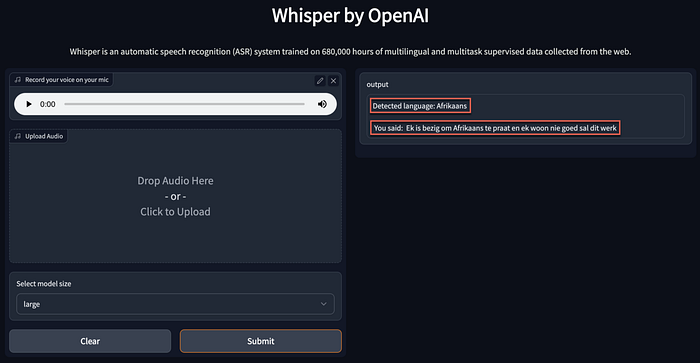
Below is a GUI from a 🤗HuggingFace Space where an Afrikaans sentence was recorded and transcribed. The language detection is accurate, but the translation leaves much to be desired.
The table below shows how the WER of Whisper for English and Multilingual models. It is clear that the Multilingual models lag behind the English model in terms of WER accuracy.
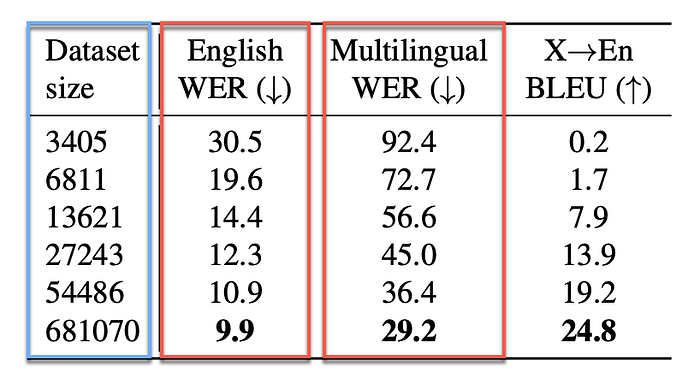
As I have stated before, if the WER exceeds 20, then it will become a challenge to implement those minor languages within a production environment.
Please follow me on LinkedIn for the latest updates on Conversational AI. 🙂
In Closing
The fact that Whisper has five languages with < 5 WER is impressive, with a sixth language in German right on the 5 WER border.
However, it is clear that OpenAI wants to steer away from a purely WER based assessment…as they feel WER penalises any difference between the model output and the reference human transcript.
And this means that systems that output transcripts that would be judged as correct by humans can still have a large WER due to minor formatting differences.
According to OpenAI, While this poses a problem for all transcribers, it is particularly acute for zero-shot models like Whisper, which do not observe any examples of specific datasets transcript formats.
In their paper on Whisper, OpenAI is questioning the validity of WER measurements in terms of the intelligibility of transcriptions, and that fine-tuning is not a requirement.
Interestingly enough, the paper ends with this caveat on fine-tuning:
While this is a crucial setting to study due to it being representative of general reliability, for many domains where high-quality supervised speech data does exist, it is likely that results can be improved further by fine-tuning. An additional benefit of studying fine-tuning is that it allows for direct comparisons with prior work since it is a much more common evaluation setting.
Please follow me on LinkedIn for the latest updates on Conversational AI. 🙂
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.
Read the Whisper Paper here.
