
Create Your Own Speech-To-Text Custom Language Model
Steps To Data Collection, Preparation & Training Your Model

Firstly…
With the creation of a text-based chatbot, much attention is given to the Natural Language Understanding (NLU) portion of the chatbot. Adding user utterances, linking those to intents and making sure entities are annotated within those user utterances.
Often the next step is to voice-enable the chatbot, allowing users to speak to the bot, effectively creating a voicebot.
Initially this seems like a straightforward process, but there are a few elements to consider…
The first element is conversation design considerations. These are covered in a previous article listed here above.
Another element to keep in mind is converting the user speech into text. Traditionally this was referred to as ASR (Automated Speech Recognition), currently the term STT (Speech-To-Text) is commonly used.
Hence a voicebot has more moving parts, and more complex from an architectural and implementation point of view.

For demo purposes the out-of-the-box STT usually works well, but in reality the STT engine will require training. In this story I want to look at a few considerations on how this problem may be approached.
For this example I will be using IBM’s STT service. There are two models which can be used to train the STT service.
The first being a language model, the second an acoustic model.
The acoustic model involves the collection of audio files to perform the training of the model. Considerations for when recording is user setting (busy street, office noise, studio recordings. Different genders, ages, accents, ethnicities etc. Different mediums; landline, mobile call etc.
The language model is a text based training approach, described below.
Domain Specific Language Models
But why train in the first place?
The out-of-the-box versions of STT has many words for general and every day conversations. However, most implementations are in industry specific organizations. These words are not used in everyday conversations, most often.
Hence the chatbot we are trying to convert to a voicebot is domain specific and these domain specific utterances need to be added to the STT vocabulary for accurate translation from voice to text.
Making use of a language model customization the vocabulary of the STT engine can be set to include domain-specific utterances.
With IBM Watson STT a corpus file can be used. This file contain words and sentences regularly used in customer conversations. This is a text file, and a more lightweight approach, as apposed to a acoustic model where recordings are used.
Training Data For The Language Model
For this article we will add domain specific data to the language model pertaining to mobile networks. First we create the data which will be used to train with.
Here is an extract from the file:
What Is a Mobile Network?
Mobile vs. Other Networks
A wireless network does not indicate a physical device.
Components of a Mobile Network
Public Switched Telephone NetworkThe full corpus file can be accessed here…
Sequence Of Events
Create A Model
With IBM STT the whole process can be managed via CURL commands. There are other ways also to interface with the STT environment.
To create a language model with a customization id, run this curl command.
The apikey and url are displayed when you create the service in the IBM Cloud console.
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx"
--header "Content-Type: application/json"
--data "
{\"name\": \"Mobile Networks\",
\"base_model_name\": \"en-US_BroadbandModel\",
\"description\": \"This is a custom language model for Mobile Networks\"}"
"https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations"The customization ID is returned. Save this value, as it will be used as a reference going forward.
{"customization_id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx"}List Customization Models
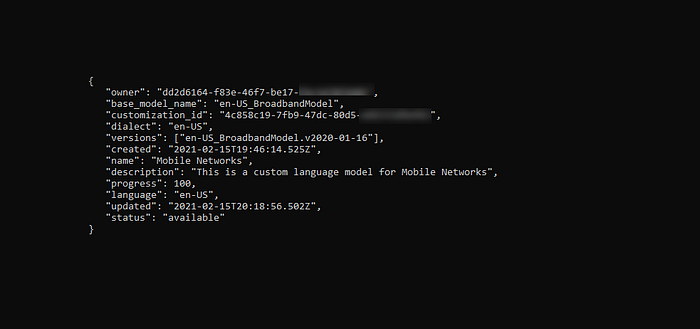
If you have multiple models, you can list them and view the meta data.
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx" "https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations"With each model shown as:
Upload Corpus File
Make sure you are in the directory where your corpus text file is located, and run this command. The customization ID is added to the URL as the reference.
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx" — data-binary @MobileNetworksCorpus.txt "https://stream.watsonplatform.net/speech-to-text/api/v1/customizations/xxxxxxxxxxxxxxxxxxxxxxxx/corpora/mobile"View The Status
Once the corpus file is uploaded, you can view the status of your upload:
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx" "https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations/xxxxxxxxxxxxxxxxxxxxxxxx/corpora/mobile"Again the customization ID we gleaned earlier in the story is part of the URL, marked by x’s.
Training The Language Model
The language model can now be trained and the out-of-vocabulary words will be added.
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx" "https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations/xxxxxxxxxxxxxxxxxxxxxxxx/train"View Training Results
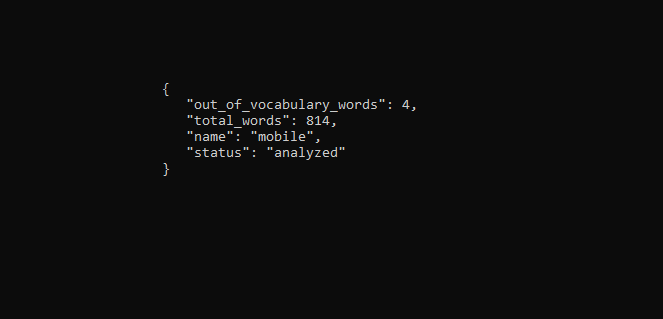
The training results can be viewed…
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx" "https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations/xxxxxxxxxxxxxxxxxxxxxxxx/words?sort=%2Balphabetical"And below you can see result from the training.

Adding Individual Words
A JSON file can be defined within the CURL command and data can be added to the language model in this way, without making use of a corpus file. With this option a word can be added, with tags for:
- Sounds Like (multiple options can be added)
- Display as
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx"
--header "Content-Type: application/json"
--data
"{\"words\":
[ {\"word\": \"PUK\",
\"sounds_like\":
[ \"phuk\", \"puck\", \"pike\"],
\"display_as\": \"PUK\"},
{\"word\": \"iPhone\",
\"sounds_like\": [\"I. phone\"]} ]}" "https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations/xxxxxxxxxxxxxxxxxxxxxxxx/corpora/mobile"
Using the same command as previously used, the result can be viewed:
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxx" "https://api.eu-gb.speech-to-text.watson.cloud.ibm.com/instances/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/v1/customizations/xxxxxxxxxxxxxxxxxxxxxxxx/words?sort=%2Balphabetical"Lastly…
Should the recordings based acoustic model or the text based language model be used?
You can improve speech recognition accuracy by using the custom language and custom acoustic models in parallel. You can use both types of model during training of your acoustic model, during speech recognition, or both.
