
Microsoft Is Going Global With Speech Enablement
Voicebots have received significant attention of late due to the desire to automate customer voice calls to call centres. This article discusses the two components required for speech enablement, STT and TTS, together with other emerging technologies.
Introduction
There seems to be renewed focus on voicebots which are not associated with a dedicated device like Alexa, Google Home, etc. There is a need from organisations to have their customers access voicebots via a phone call they place to a number.
In terms of customer care, incoming calls to a call centre is the preferred medium of communication of most customers, and the most expensive to field by companies. Automation has succeeded in other areas of Conversational AI, but voice calls are still lagging…for now.
Speech interfaces will eventually become ubiquitous, and the existing impediments are being eradicated slowly but surely. One such impediment is niche or minority languages which are being addressed as seen below.
Other areas which require work are handling background noise, turn taking, interruption, barge-in, digression, etc.
There are a few companies doing stellar work in terms of speech, a few of these are SoundHound, Deepgram, Resemble, Respeecher, etc. These speech focused companies are forming part of the Seven Vertical Vectors which are addressing these niche vectors. There are also new methods available like speech to meaning (SoundHound) and speech to speech (Respeecher).
Some of these companies have innovative and new ideas to address the challenges of voice enablement.
The large technology companies are also working on these problems, like IBM, Nuance Mix, Amazon Lex, etc.
Can You Simply Convert A Chatbot To A Voicebot?
Please read this before converting your chatbot to a voicebot…🙂
There are definitely a few design considerations when voice enabling a chatbot.

The image above is a very basic but accurate representation of a voicebot, and how a voicebot, in theory, can be extended or “voice enabled” by adding speech components to the chatbot. These speech components are:
1️⃣ Text to Speech (TTS, Speech Synthesis). This is the process of converting text into a synthesised, audible voice.
This can be done off-line and the audio stored somewhere. Or it can be performed on the fly, in real-time while the caller is on the call. It makes sense to cache voice segments for re-use, to optimise for processing, possible latency, etc.
Synthetic voices can also be trained on a number of studio voice recordings from a voice artist. Microsoft’s Speech Studio turns the creating and training of a neural voice into an administrative task.
2️⃣ Speech To Text (STT, ASR, Automatic Speech Recognition) is the process of converting speech audio into text.
This text is in turn passed to the NLU engine. Microsoft does provide a base language pack, which performs quite well, but again with a limited amount of training data, great strides in ASR accuracy is possible.
It needs to be mentioned that Microsoft’s fine-tuning tooling for both TTS and STT is comprehensive.
“In theory, theory and practice are the same. In practice, they are not.”
~ Albert Einstein
Generally, existing chatbot elements which can be reused are:
- The existing API abstraction layer and integration can be reused for the voicebot.
- Chatbot dialog flows and customer journeys can be adapted for a voicebot.
- Scripts and bot messages can also be reused, but require quite a bit of design consideration for voice.
- The chatbot development framework can be reused in terms of dialog development and management, NLU/NLP, etc.
- Some argue that the same NLU engine can be used for both voice and chat. In my experience the chatbot NLU engine is a good starting point, but I would elect to create a new NLU engine for the voicebot. I say this for a number of reasons:
- User utterances for chatbots are often menu or single word, or button driven and less verbose.
- User utterances for voice is more verbose, background noise and sounds like “uh, ahm, ok”, etc need to be catered for in the NLU. Also users correcting themselves in the same sentence, etc.
- As we will see later, there are a percentage of errors which will come through on the ASR, even with a trained fine-tuned acoustic model for the ASR.
- These errors (or you can think of it as aberrations) need to be absorbed somewhere, and the only feasible place is in the NLU engine.
Read more on design here…
Microsoft TTS & STT Languages
Microsoft has extended their reach in terms of languages considerably, as seen below. Even though there are a few exceptions, but what is great is the STT and TTS pairings of voice capability per language. In the vast majority of implementations, you would require both TTS and STT.
With this collection of language support, Microsoft is solving for a very big problem in voice enablement and access.

According to Microsoft, they are confident to continuously expand language coverage to bring their speech capability to every corner of the world. From 2021, Microsoft continued to expand languages & language locales across Europe, Asia & Africa. This helps an additional 700+ million speakers to use speech ability.
Text formatting features include:
- ITN (Inverse Text Normalization),
- Capitalisation (if applicable),
- Implicit punctuation (automatically generate basic punctuations) to improve readability.
Here is a view of the TTS Testing Console:
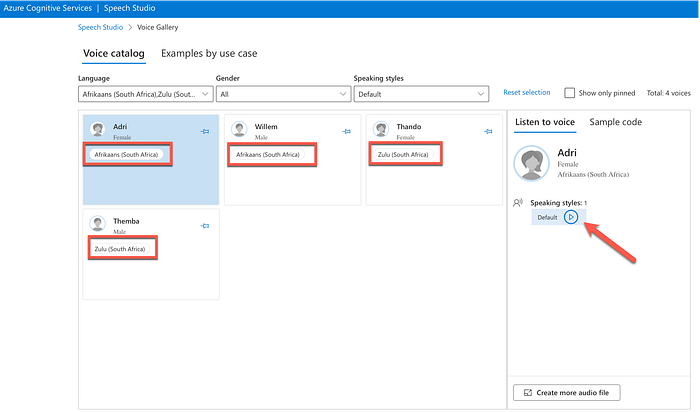
Microsoft Speech Studio
Text To Speech (TTS)
Microsoft Speech Studio allows for fine-tuning for both TTS and STT under Custom Speech and Custom Voice.
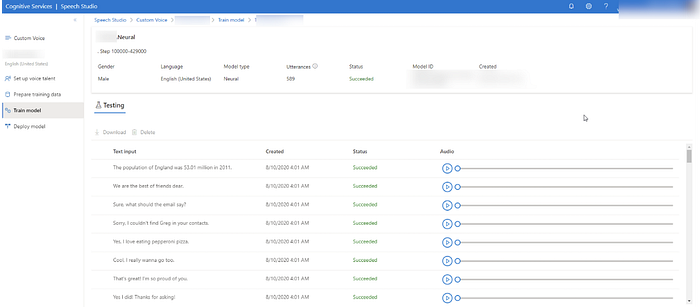
Most organisations will not want to use the standard voices available, hence a custom neural voice can be created. This is where the Microsoft TTS capability is fine-tuned with recorded utterances by the desired voice. These utterances used for training the custom/fine-tuned model can range from 20 to 50 utterances, up to 300 to 2000 utterances.
Below a screenshot of the imported voice recordings.
The verbatims or scripts of the recordings are also required, read more here.
Speech To Text (STT)
The Microsoft Speech Studio base model for STT is acceptable in terms of accuracy in converting speech to text. But a custom model can be used to fine-tune the base model, in order to improve recognition of domain-specific vocabulary.
Examples of domain-specific implementations are terminology and expressions specific to banking, mobile telecommunication, health-care, etc.
Text only data can be used for fine-tuning the STT engine. However, the best is to use audio recordings with matching transcript files to improve recognition. The recordings must be based on the specific audio conditions of the application’s users. For instance noisy environments, known background sounds, and inclusivity in terms of age, gender, ethnicity, regional accents, etc.
The accuracy of STT is measured in Word Error Rate (WER)…there are various claims to WER. In my experience a good WER for non-native speakers of a language is in the vicinity of 15% to 18%.
Some vendors claim WER percentages as low as 4%…here are a few considerations…
- This is most probably native speakers of the spoken language.
- The recordings are most probably clean (not noisy), well pronounced words in a studio setting.
- When voice is captured for WER measurement, using a telephone call where the sound is compressed and normal background noise will detract the WER rate, but is more representative.
- The extend to which industry specific words, regional expressions and names are used will also detract to the WER percentage. These elements need to be present in a representative fashion.
- Again, ethnicity, gender, age, regional accents, etc all need to be represented proportionally.

Below an example of a word error calculation for non-native speakers of a langauge and where the recordings used for WER calculation were representative.

Conclusion
Launching a voicebot is an arduous process, and measures of success is often relative and very subjective. I recently wrote about how to measure chatbot and voicebot success. In some cases, there is a big difference between the ideal sold by vendors, and the realities faced by the implementors.
In an upcoming post I’ll lend some insight into unleashing a voicebot into the wild…
