What’s Wrong With Using Synthetic Data For Conversational AI Training?
There are a few Digital Assistant development frameworks which generate synthetic training data, but how sustainable is this approach?

Introduction
A Digital Assistant (aka chatbots, voicebots, Conversational UI) has three main components which needs to be developed (apart from integration, hosting, etc).
1️⃣ NLU Design
2️⃣ Conversation State Management
3️⃣ Response Management
Response Management and Conversation Design have both received much attention.
The discipline of conversation design is well established for various modalities, be it voice or text based.
Response Management is addressed by the availability of conversational components and design affordances. There has been much emphasis placed on UX design for web chat, Messenger and other graphic rich conversational interfaces.
However, NLU Design is the one area where Conversational AI is lagging currently. And by lagging I mean the absence of astute data practice and following a data-centric approach to training the NLU Model.
To learn more about a data centric approach to NLU Design, read more about it here ⬇️
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
So What Is Synthetic Data?
Instead of making use of existing customer conversations and following good data practice, organisations are often creating synthetic data.
The advent and availability of Large Language Models (LLMs) has made it easy to create different variations of a described intent.
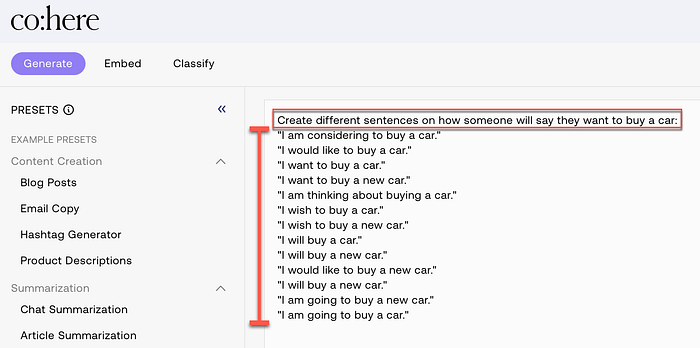
To illustrate the creation of synthetic data, consider the example below from the Cohere playground.
A generative description is given on which the generated data is premised, as seen below:
Create different sentences on how someone will say they want to buy a car:I submitted the generative prompt to the Cohere LLM, which generated the following sentences:
"I am considering to buy a car."
"I would like to buy a car."
"I want to buy a car."
"I want to buy a new car."
"I am thinking about buying a car."
"I wish to buy a car."
"I wish to buy a new car."
"I will buy a car."
"I will buy a new car."
"I would like to buy a new car."
"I will buy a new car."
"I am going to buy a new car."
"I am going to buy a car."Below you see a screen-print from the cohere playground with the description (generative prompt) and the result generated.
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
The same LLM principles are used and implemented by a system like Amelia AI, where the training data is synthetically generated from the intent description / user utterance entered on the left at design time. As seen below…

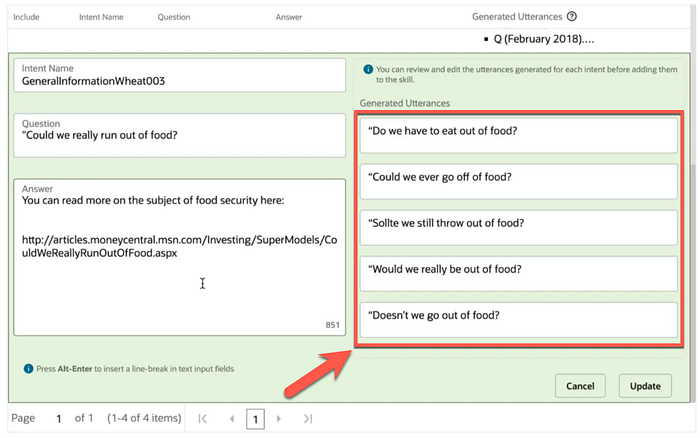
Oracle Digital Assistant has a few options to bootstrap a chatbot with uploading documents. From which intent names and generated utterances are created.
The generated utterances has a Large Language Model feel to it, and it will be interesting to know how this is performed under the hood.
Read more about it here.
The article below lends more insight into the Yellow AI approach and use of synthetic data:
In Conclusion
In the absence of any available customer conversational data, synthetic data can serve as an avenue to bootstrap a chatbot. However, soon after launch developed intents need to be based on actual user conversational data.
Intents also needs to be ground-truthed…ensuring that developed intents are aligned with existing user intents…and addressing the long tail of intent distribution.
A Human-In-The-Loop approach to labelling of intents from actual customer conversations are key to helping the algorithm improve and fix vulnerabilities and ultimately improve the model’s overall performance.

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.