
Bootstrapping A Chatbot With A Large Language Model
How To Harness The Power Of OpenAI In Creating A Chatbot From Scratch

Introduction
In this article I cover a practical approach on how to create a chatbot from scratch, using Large Language Models. I will be illustrating this method with step-by-step examples while leveraging OpenAI and a new concept I like to call intent-documents.
This as an approach I have conceptualised over the last few weeks while focusing on Large Language Models (LLM). I believe this is a feasible and practical methodology to combine LLM features to create a chatbot by orchestrating clustering, semantic search and Generation (NLG).
The unstructured data used for creating the chatbot is a list of facts pertaining to the continent of Africa. Hence the purpose of this chatbot is to answer questions related to the African continent, while maintaining state and contextual awareness.
The conventional approach is NLU training using user utterances, in this approach the bot utterances (facts) are used to create and train the bot. Hence the process is inverted to some degree, with the bot training performed using bot messages and content.
Recently I wrote about the HumanFirst and Co:here POC integration which was a good example on how to leverage LLM’s for real-world production implementations.
So, here is a practical example of how OpenAI can be leveraged to create a chatbot…
Architecture Overview
My approach is a chatbot implemented as a thin abstraction layer premised on the OpenAI LLM.
Below is a basic sequence diagram describing the steps involved and how these steps relate to each-other.

Step 1: Clustering & Intent Detection
The first step is to use OpenAI’s clustering to make sense of large volumes of unstructured text data.
As per the OpenAI documentation:
Clustering is one way of making sense of a large volume of textual data. Similarity embedding is useful for this task, as it is a semantically meaningful vector representation of each text. Thus, in an unsupervised way, clustering will uncover hidden groupings in our dataset.
With unsupervised training, clusters are created of sentences representing related facts. These groupings are given a theme name; these themes are in essence intents, used to create intent-documents.
Currently OpenAI does not cater for clustering within the Playground.
Clustering with OpenAI is detailed within a Notebook example and is a highly technical Python code based solution. For clustering the data (facts of Africa) it was much easier to again revert to the HumanFirst to ingest the unstructured and unlabelled data.
Unfortunately no integration exists between HumanFirst and OpenAI, like in the case of Co:here. For the intent-documents it is important to be able to organise the intent data, both for the inception of the bot and continuous maintenance.
Comparing clustering results of Co:here and OpenAI will be really interesting.
Back to the process…the first step is to take our training data and cluster the training data into intents. Each cluster, or intent, is named and contains a list of associated facts.
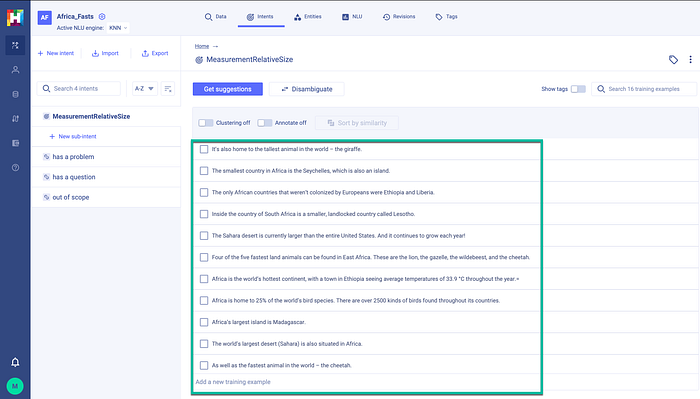
As seen above, within the HumanFirst, the first intent is defined, named MeasurementRelativeSize. The list of facts which constitutes this intent are marked with the green block.
This is a quick and easy way to cluster unlabelled facts in an unsupervised fashion.
The intent name and the list of facts are uploaded to OpenAI as an intent-document. These intent-documents will use for semantic search.
Step 2: Semantic Search
The next step is to capture and understand the user utterance…
During runtime, when the user sends a message to the chatbot, the utterance is assigned to an intent and a subsequent intent-document is retrieved.
This is done via zero shot training, semantic search. The OpenAI semantic search functionality allows for the user utterance to be matched to a cluster of training utterances (also referred to as a document), which denotes an intent.
Below is an example of the JSON payload returned by OpenAI, referencing the applicable intent-document.
{
"data": [
{
"document": 0,
"object": "search_result",
"score": 215.412
},
{
"document": 1,
"object": "search_result",
"score": 40.316
},
{
"document": 2,
"object": "search_result",
"score": 55.226
}
],
"object": "list"
}The intent-document approach described here is an efficient way of accessing and retrieving only a small portion of the training data/facts.
There are also other important reasons to organise training data in an automated fashion, hopefully I can expand on this in a later article.
This allows for the facts sent to the OpenAI Generation API be as short and concise as possible. Contributing to efficiency in cost, response times and very little to no aberrations in generated text.
You can read more of OpenAI document search and the fine-tuning process here.
Step 3: Generation
Once the correct intent-document is selected by semantic search…
The intent-document together with the entered user message are sent to OpenAI’s generation API.
The OpenAI generator returns an appropriate bot response to be presented to the user. The intent-document is used as few shot training data, basically this is used for on the fly bot prompt creation.
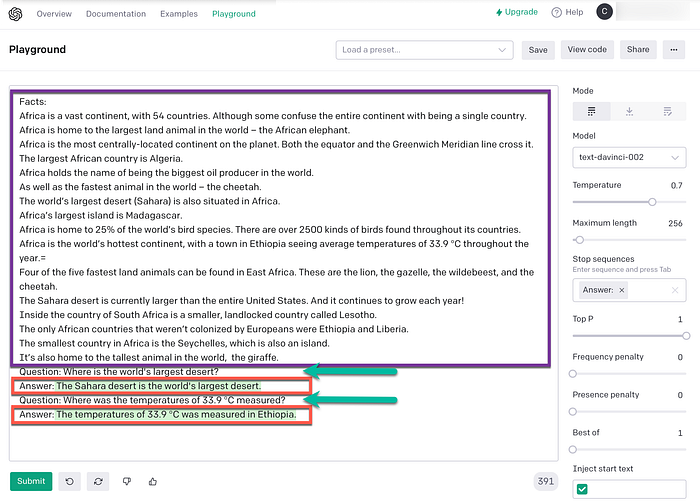
In the image below, the intent-document is marked by the purple block in the image below.
The question entered by the user is marked by the green arrow.
The OpenAI generated answer is marked by the red blocks.
You can see how well the NLG is formed by OpenAI and how contextually accurate the generated response is.
Below is the python code for the playground example shown and discussed prior.
Again, it is clear that the intent-documents need to be categorised and formed very accurately. All the while keeping the intent-document as succinct as possible, making the API calls more efficient and cutting down on overhead.
import os
import openaiopenai.api_key = os.getenv("OPENAI_API_KEY")response = openai.Completion.create(
model="text-davinci-002",
prompt="Facts:\nAfrica is a vast continent, with 54 countries. Although some confuse the entire continent with being a single country.\nAfrica is home to the largest land animal in the world – the African elephant.\nAfrica is the most centrally-located continent on the planet. Both the equator and the Greenwich Meridian line cross it.\nThe largest African country is Algeria.\nAfrica holds the name of being the biggest oil producer in the world.\nAs well as the fastest animal in the world – the cheetah.\nThe world’s largest desert (Sahara) is also situated in Africa.\nAfrica’s largest island is Madagascar.\nAfrica is home to 25% of the world’s bird species. There are over 2500 kinds of birds found throughout its countries.\nAfrica is the world’s hottest continent, with a town in Ethiopia seeing average temperatures of 33.9 °C throughout the year.=\nFour of the five fastest land animals can be found in East Africa. These are the lion, the gazelle, the wildebeest, and the cheetah.\nThe Sahara desert is currently larger than the entire United States. And it continues to grow each year!\nInside the country of South Africa is a smaller, landlocked country called Lesotho.\nThe only African countries that weren’t colonized by Europeans were Ethiopia and Liberia.\nThe smallest country in Africa is the Seychelles, which is also an island.\nIt’s also home to the tallest animal in the world, the giraffe.\nQuestion: Where is the world's largest desert?\nAnswer: The Sahara desert is the world's largest desert.\nQuestion: Where was the temperatures of 33.9 °C measured?\nAnswer: The temperatures of 33.9 °C was measured in Ethiopia.",
temperature=0.7,
max_tokens=256,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=["Answer:"]
)

Step 4: Contextual Generation
Lastly, conversation state and context can be managed by again leveraging OpenAI Generation, by merely resubmitting the previous dialog turns of the conversation to the generator.
The OpenAI generation API performs extremely well in detecting these contextual references and responding accurately. However, provided that this few shot training data is labeled in the following way:
- Facts: The contents of the applicable Intent-Document
- Question: User Message Input
- Answer: OpenAI Generated Bot Response
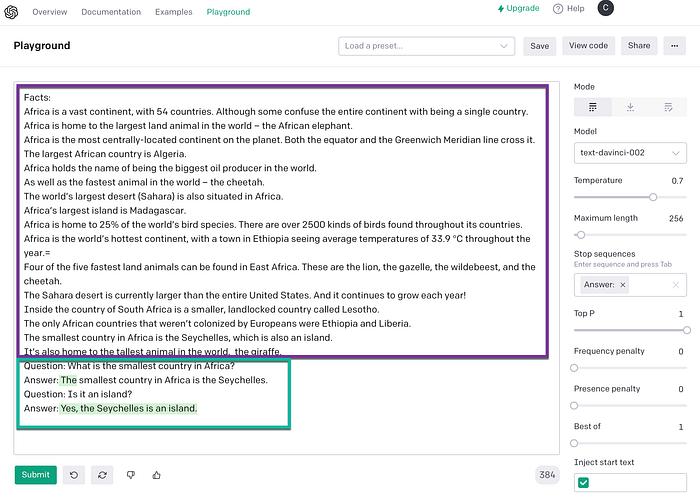
In the image below, you can see the intent-document marked in the purple block.
The green blow is the dialog turns with the user utterances.
You can notice the second question is ambiguous if considered in isolation.
However, if assessed in conjunction with the first question, the context is clear.
Question: What is the smallest country in Africa?
Answer: The smallest country in Africa is the Seychelles. Question: Is it an island?
Answer: Yes, the Seychelles is an island.
Below the extract from the OpenAI playground…
The responses of the OpenAI generation model can be rated, as useful or poor. This might not have a bearing on your chatbot directly, but can help OpenAI improve overall.

However, this task can be forwarded to the user, the results can also be captured within an abstraction layer for development and improvement of intent-documents. This where a data-centric tool like HumanFirst can be invaluable for a observeabiltty and identifying fine-tuning opportunities.
Conclusion
This prototype I developed illustrates a methodology of how a LLM like OpenAI can be leveraged, and how natural language generation is guided and augmented by using intent-documents.
Clustering can help discover valuable, hidden groupings within the data.
~ OpenAI
The HumanFirst and Co:here POC did well to illustrate how a granular approach can be followed for intent detection and management. Also, how the long tail of conversation design can be defined and planned for, with granular clustering.
The first part which is really important, is the creation of these intent-documents. It was extremely convenient and intuitive to create and manage these clusters with the HumanFirst and Co:here integration. I would have been really interesting to compare it to an integration between the HumanFirst and OpenAI.
Lastly, intent-documents has a purpose and relevance beyond this prototype example, hopefully I will write about this soon.
