Analysis Of The New OpenBook NLU API
Botpress Recently Announced The Release Of OpenBook, A “Next-Generation NLU Engine”

In this article I cover how Openbook works, how will it be used and finally Analysis of the solution.
Introduction
I have been fortunate to have received early access to this new product from Botpress, called OpenBook. Botpress is positioning OpenBook as a knowledge based chatbot framework and not a Knowledge Base, per se.
I do get the impression that Openbook is a thin abstraction layer which sits on top of a LLM, but more about that later…
Openbook is still in development, and elements like entities will come to the fore soon.
In the words of Botpress…
Openbook aims to solve four elements in chatbots:
- Build faster & easier
- Predictability & control
- Scalability
- Creating conversations that feel authentically human
How does Openbook work?
- Openbook is sold as a Knowledge Based chatbot development framework, and not a Knowledge Base per se.
- But, Openbook has an API available which will see it mostly leveraged by existing Chatbot frameworks, seeing Openbook will not be bundled with the Botpress offering. Openbook will most likely be made available on a pay-per-use basis.
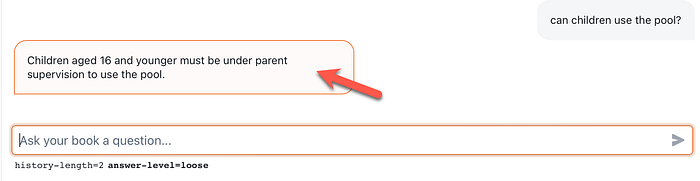
- Considering the image below, the test chat window has a strict and loose setting for Natural Language Generation (NLG). The strict version, returns verbatim the details of the training data.
- Also from the image below, history level reminds quite a bit of the conversation context management of OpenAI.

- Looking at the image below, the green bot response is generated from the strict answer-level, while the yellow response is from the loose answer-level. Strict is verbatim from the training data, whilst Loose is generated.

- The two most impressive features of Openbook is the NLG, and maintaining context within the conversation, for up to 5 dialog turns back into the conversation history. Below is an example where a question is asked about children, and the context of pool is maintained. This feature reminds quite a bit of context management within OpenAI.

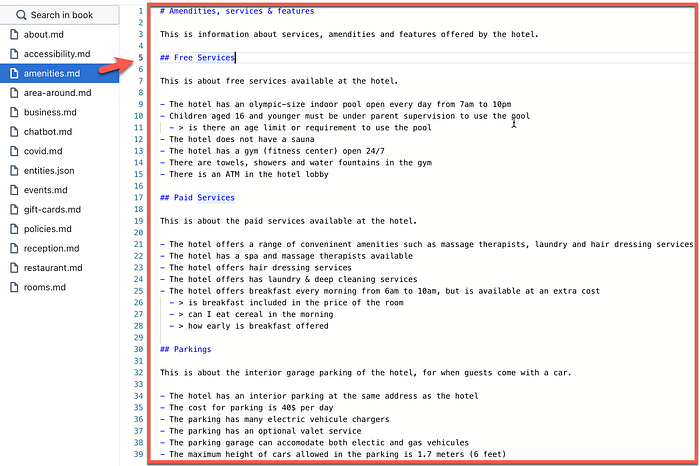
- Below, is the sum total of the user interface. An Openbook application is constituted by a set of MD files (purple), each file can be considered as sections of the conversation flow, or as skills within a larger Digital Assistant. Within the .md file, are labels (green) which is analogous to intents. Each label in turn has facts (red), and some facts can be supplemented with contextual questions (yellow).

- Entities will be introduced shortly by Botpress. Below an example of the JSON format which will define an entity. From the JSON format entities will be fairly advanced with synonyms and patterns. The presence of the patterns element probably denotes defining context for the entities within utterances.
{
"lists": [
{
"name": "Montreal Hotel & Suites",
"synonyms": [
"MHS",
"Montreal Hotel"
]
}
],
"patterns": []
}How Will Openbook Be Used?
Openbook can be used in standalone mode for smaller implementations.
However, for larger enterprise-grade implementations which need to scale well, Openbook will be used as a supporting API.
The lack of entities and fine-tuning of the flow will make it difficult to implement Openbook for conversations which are longer with multiple dialog turns.
Openbook will also require a chatbot framework to orchestrate the conversation and in turn the framework will have to know when to call on Openbook.
Analysis
Knowledge Bases
Openbook is competing with established knowledge base platforms like IBM Watson Discovery, Oracle Digital Assistant and general QnA systems like NVIDIA Riva and other LLM offerings.
Botpress announced OpenBook as the “next-generation NLU engine”. A bold statement considering advances made by Co:here, OpenAI, AI21labs, etc.
Add to this the semantic search capability delivered by Pinecone, and it is clear that the competition is fierce.
That leads me to the following point, Large Language Models…
LLM’s
I always ask myself, what’s under the hood?
It really does seem like Openbook is built on top of a Large Language Model.
The elements constituting Openbook gives me this impression, for instance:
- The short training time
- The robust NLG element,
- and the way in which the dialog is presented and managed.
Allow me to illustrate this with a few examples…
Below is the knowledge file for the amenities skill within the Hotel Demo application. The knowledge file is used to train Openbook.
When Openbook is queried with the question, “can children use the pool?”
The results below yielded by Openbook is:
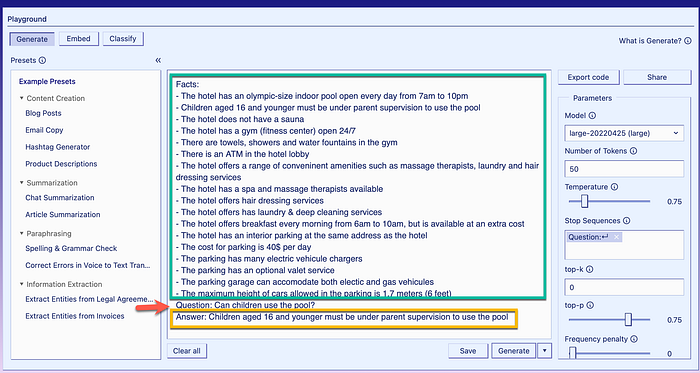
When the exact same training data is entered into the Co:here completion API, very much the same result is returned. And the level of verbosity and NLG creativity can be set.
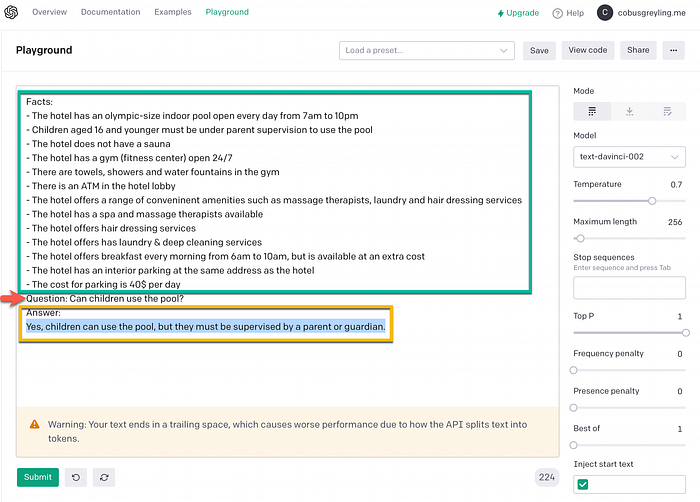
The same training data from amenities.md is entered into OpenAI, with comparable results. Again the NLG can be tweak in terms of creativity.
And AI21labs studio…

Lastly, keep in mind there are free open source AI initiatives like EleutherAI, shown below. Where the same approach is followed with good results. Deepset also has quite a few open source solutions available for semantic search, question answering and Conversational AI.

Conclusion
I do get the impression that Openbook is a thin abstraction layer which sits on top of a LLM.
The likely architecture is where the user input (step 1) is sent to a LLM zero shot Semantic search API, to determine in which MD file the query falls.
From here the contents of MD file is sent, with the user input, to a LLM Generation API (step 2) for the bot response generation. In instances where context needs to maintained, (step 3) previous user inputs are included for Generation.
Step 3 is for instances where the user asks something like, “can children use the hotel’s pool?”, followed by a question like “how big is it?”. LLM Generation does quite well in detecting this contextual reference (pool) and responding accurately, in the case of this example, with the size of the pool.

This is a logical conclusion considering the generated answers based on few-show training scenario and the short training time. Also the NLG and the ability to set the temperature on generated answers.
If this is the case, there are a few considerations…one is the possibility that Openbook is dependant on underlying licensed software and the value add of Openbook in the greater scheme of things.
Openbook has been quite mute on what lies under the hood, due to the time I’ve spent recently with LLMs, I’ve grown to understand how they can be used and could definitely see how this approach would work. I will be very interested in being proven right or wrong 🙂.
Read the Botpress OpenBook whitepaper.
