Microsoft Cognitive Services Can Now Detect & Redact PII In Conversations
Recently Microsoft added to their cognitive services the ability to detect and redact Personally Identifiable Information (PII) in conversational transcripts. This feature not only allows for PII compliance in chatbot & agent chat transcripts, but also for voicebots and customer/agent conversations. The API also enables redaction of audio segments which contains the PII information, by providing the audio timing information for those audio segments.

The TL;DR
- Gartner advises that existing customer conversation transcripts should be used for determining intents, and aligning the digital assistant with customer needs.
- These customer transcripts can be voicebot or chatbot conversation transcriptions, or other sources of customer conversations like live agent chats, email, etc.
- Most enterprises and countries have legislation governing the protection of private information, generally known as Personally Identifiable Information (PII).
- The redaction of PII in conversations, not only allow for companies to achieve compliance when archiving interaction data. But, it also paves the way for conversation transcripts to be utilised for Intent Driven Design & Development (IDD) and for continuous improvement of digital assistants.
- The challenge with redacting PPI in conversations, is the highly unstructured nature of conversational data.
- Microsoft is expanding their CCAI offering, in areas like conversation summarisation, speech enablement, and now PII Redact in conversations.
- Like Summarisation for Conversations, PII for Conversations is currently in preview.
Understands why customers are calling and customises the experience to anticipate their needs with AI intent prediction.
~Charles Lamanna
Contact Centre AI (CCAI) & Redaction of PII
Firstly…
When considering CCAI and the 18 elements Gartner identified as CCAI use-cases, Redacting of Personally Identifiable Information is listed 10th out of 18 in importance. With a near-high business value, but lagging in feasibility.
However, this development by Microsoft aims to solve for the lagging feasibility.

Secondly…
CCAI use-cases 1 and 2 are closely related to use-case 10, redacting of PII. To analyse conversations for sentiment and topics, redacted conversational data will most probably be a requirement.
Also, in order to perform continuous intent training and improvement of the digital agent, the only real source of valuable information is conversational transcripts.
Hence access to transcript data is vital.
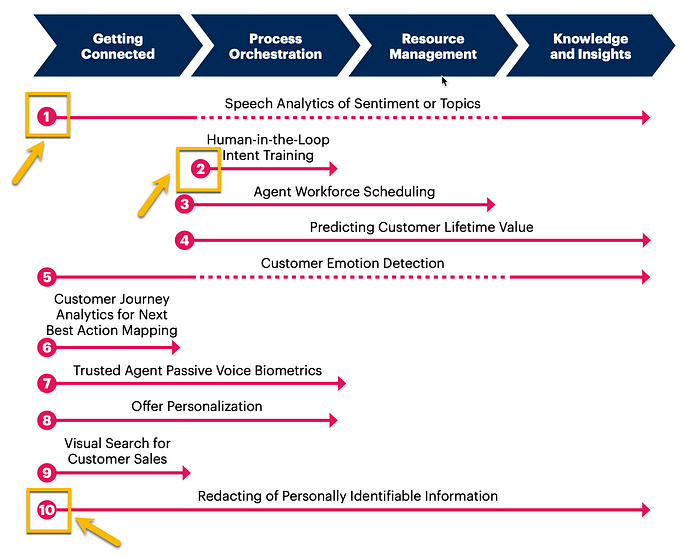
The 18 CCAI use-cases identified by Gartner cannot be seen in isolation, and there is definitely an interdependence between some of the use-cases.
Please consider subscribing and receive an email when I publish a new article…🙂
Personally identifiable Information (PII) in Conversations
Currently the conversational PII preview API only supports English language and it is available in all Azure regions supported by the Language service.
The API is asynchronous, seemingly the delay between sending an API request, and receiving the redacted results vary.
When you submit data to conversational PII, you can send one conversation (chat or spoken) per request.
The API will detect all the pre-defined entities for a given conversation input. Users can also specify custom entities by using the optional piiCategories parameter to define custom entities.
To make use of this API, you will need to create an Azure Language resource, which grants you access to the features offered by Azure Cognitive Service for Language. It will generate a password (called a key) and an endpoint URL that you’ll use to authenticate API requests.
Below is an example of a PII query in Postman, with the input at the top, and the redacted sentence at the bottom, followed by the data redacted and the description/entity name.
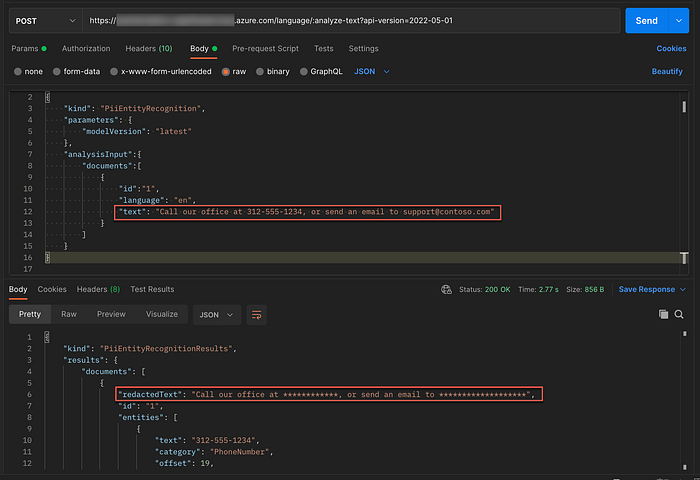
Here is the JSON payload submitted…
{
"kind": "PiiEntityRecognition",
"parameters": {
"modelVersion": "latest"
},
"analysisInput":{
"documents":[
{
"id":"1",
"language": "en",
"text": "Call our office at 312-555-1234, or send an email to support@contoso.com"
}
]
}
}And the response received…
{
"kind": "PiiEntityRecognitionResults",
"results": {
"documents": [
{
"redactedText": "Call our office at ************, or send an email to *******************",
"id": "1",
"entities": [
{
"text": "312-555-1234",
"category": "PhoneNumber",
"offset": 19,
"length": 12,
"confidenceScore": 0.8
},
{
"text": "support@contoso.com",
"category": "Email",
"offset": 53,
"length": 19,
"confidenceScore": 0.8
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2021-01-15"
}
}As you can see from this example, the PII API is synchronous, but the PII for Conversations API is asynchronous; as mentioned previously. This synchronous API can be useful for live agent chats, to protect the agent from PII information like credit card numbers, etc.
The open nature of our platform enables companies to build on what they already have and easily add any combination of capabilities they need to take their contact center to the next level.
~Charles Lamanna
And Lastly…
The redacted data with asterisks will surely be clumsy to work with, having the spot the context prior to labelling or training.
But it would make sense to replace the string of asterisks with the category name. The category name is analogous to the entity name, which will go a long way in making the data more interpretable from a NLU perspective.
The redacted conversation transcripts with PII replaced with a category name can also be used for testing the accuracy of entity recognition.
So apart from being useful in intent training, the transcripts can also be useful in entity verification.
The idea of having the name of the entity, sparks the question, can entities not be replaced with random but related strings. For instances, a 10 digit phone number is replaced with a randomised 10 digit phone number. Hence the data will still be coherent and very much useable for training purposes.
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more…