Large Language Model Hallucination Mitigation Techniques
This recently released study is a comprehensive survey of 32+ mitigation techniques to address hallucination.
Introduction
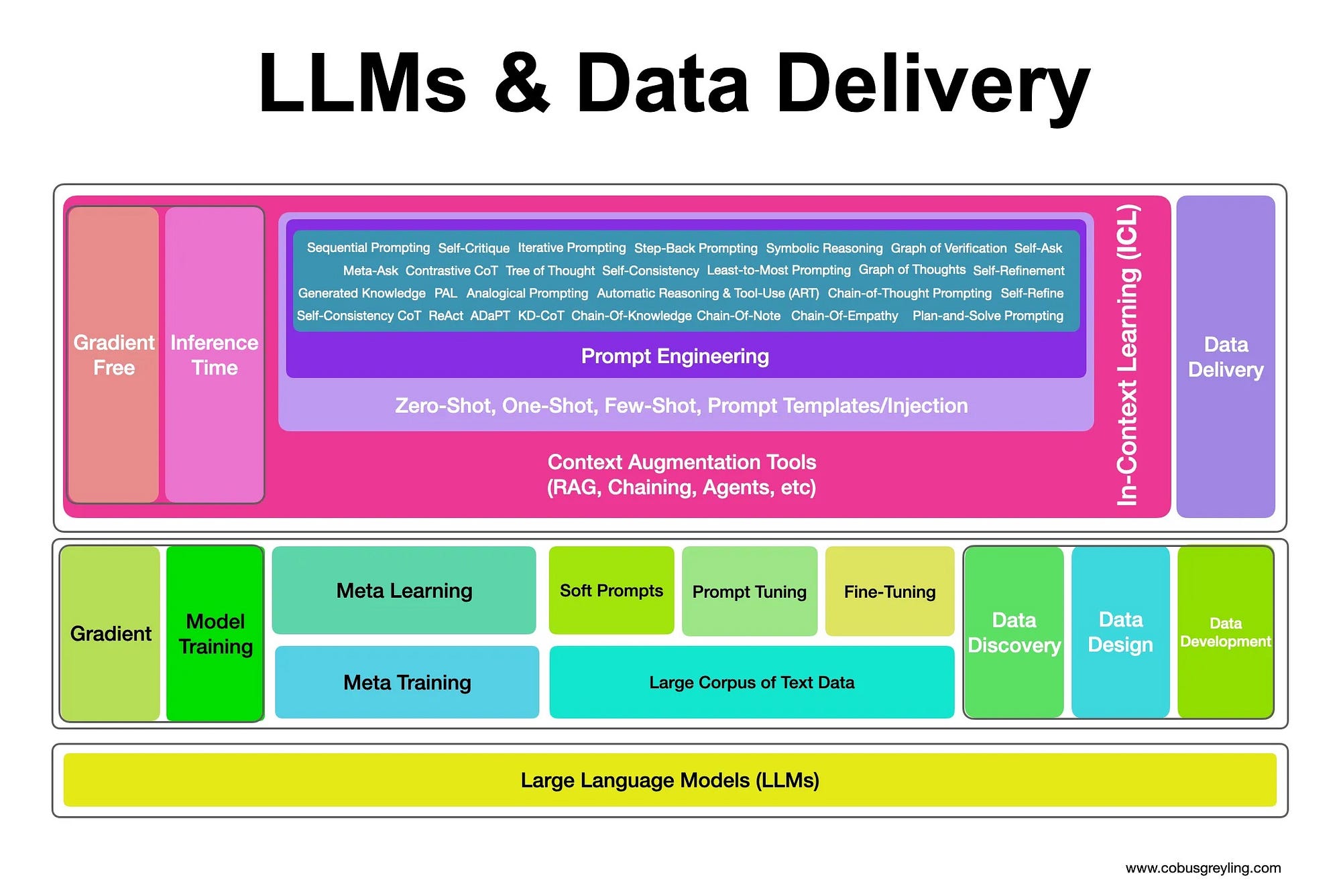
The techniques are broken down into two main streams, gradient and non-gradient approaches. Gradient approaches refers to fine-tuning the base LLM. While non-gradient approaches involves prompt engineering techniques which are delivered at inference.
Most notable are the inclusion of:
- Retrieval-Augmented Generation (RAG)
- Knowledge Retrieval
- CoNLI
- CoVe
Hallucination mitigation in LLMs represents a multifaceted challenge addressed through a spectrum of innovative techniques.
Unlike traditional AI systems focused on limited tasks, LLMs have been exposed to vast amounts of online text data during training.
This allows LLMs to display impressive language fluency, it also means they are capable of:
- Extrapolating information from the biases in training data,
- Misinterpreting ambiguous prompts, or modifying the information to align superficially with the input.
This becomes hugely alarming when language generation capabilities are used for sensitive applications, such as:
- Summarising medical records,
- Customer support conversations,
- Financial analysis reports, and providing erroneous legal advice.
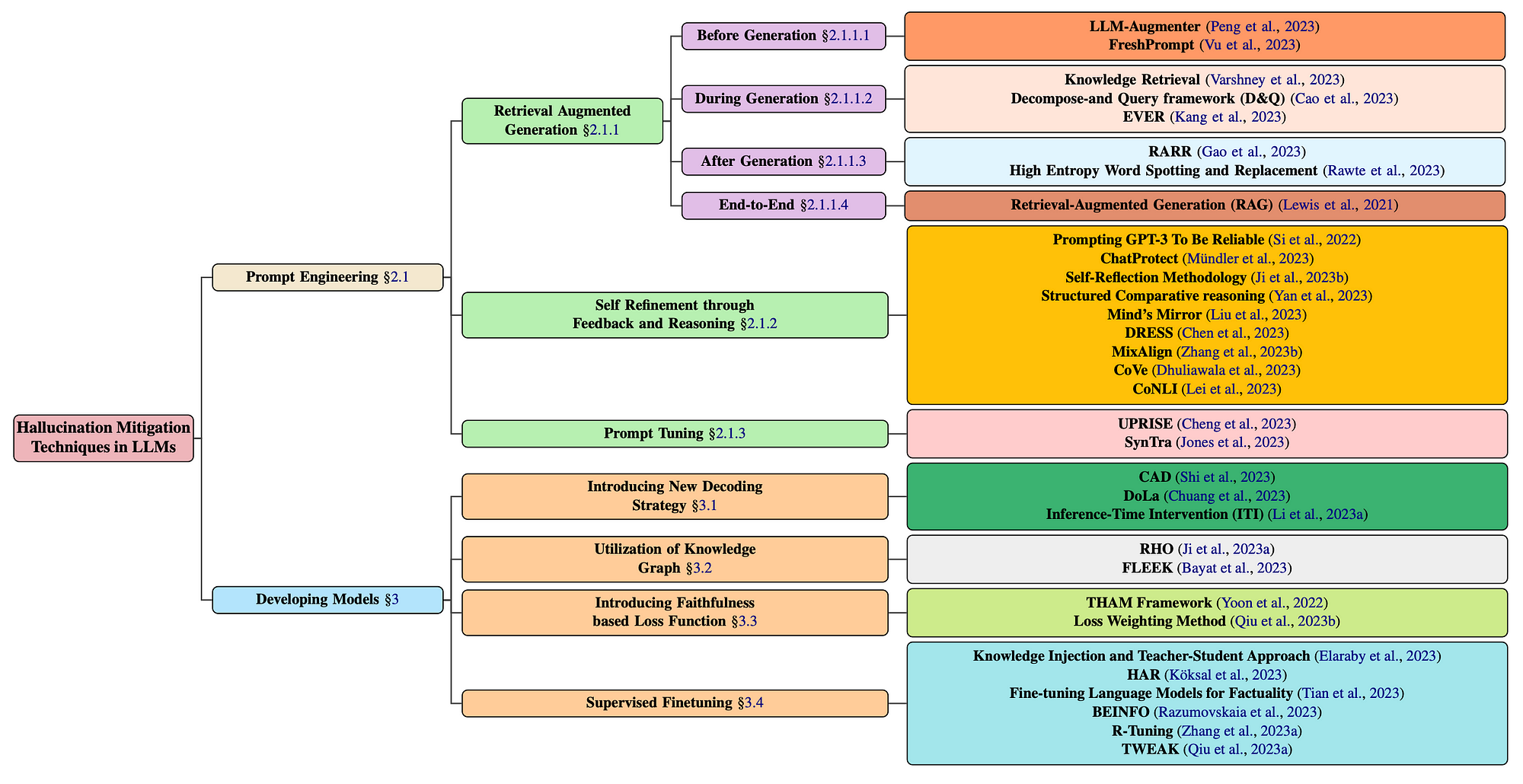
Hallucination Mitigation Taxonomy
The study includes very insightful taxonomy of hallucination mitigation techniques for LLMs; both gradient and non-gradient.
Gradient approaches include complex and opaque decoding strategies, knowledge graphs, fine-tuning strategies and more.
Non-gradient approaches include RAG, Self-Refinement and prompt tuning.
Notably the RAG approaches are segmented into four parts;
- Before Generation
- During Generation
- After Generation
- End-to-End
The power of prompt engineering to mitigate hallucination lies in defining:
- Specific context &
- Expected Outcomes
The Best Defence
The best defence against hallucination is not one single approach or method, but a combined approach defending against hallucination.
Seamlessly integrating numerous mitigation approaches, is the most important takeaway.
The factors which any organisation should keep in mind are:
- To what extent is there a reliance on labeled data?
- What are the possibilities of introducing unsupervised or weak-supervised learning techniques to improve scalability and flexibility?
- Consideration of gradient and non-gradient approaches to produce coherent and contextually relevant information.
- The collected works on hallucination mitigation reveal a diverse array of strategies, each contributing uniquely to address the nuances of hallucination in LLMs.
- Self-refinement through feedback and reasoning brings forth impactful strategies.
- Structured Comparative reasoning introduces a structured approach to text preference prediction, enhancing coherence and reducing hallucination.
- Supervised fine-tuning can be explored via Knowledge Injection and Teacher-Student Approaches.
- Domain-specific knowledge is injected into weaker LLMs and approaches that employ counter factual datasets for improved factuality.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.