Data Delivery To Large Language Models [Updated]
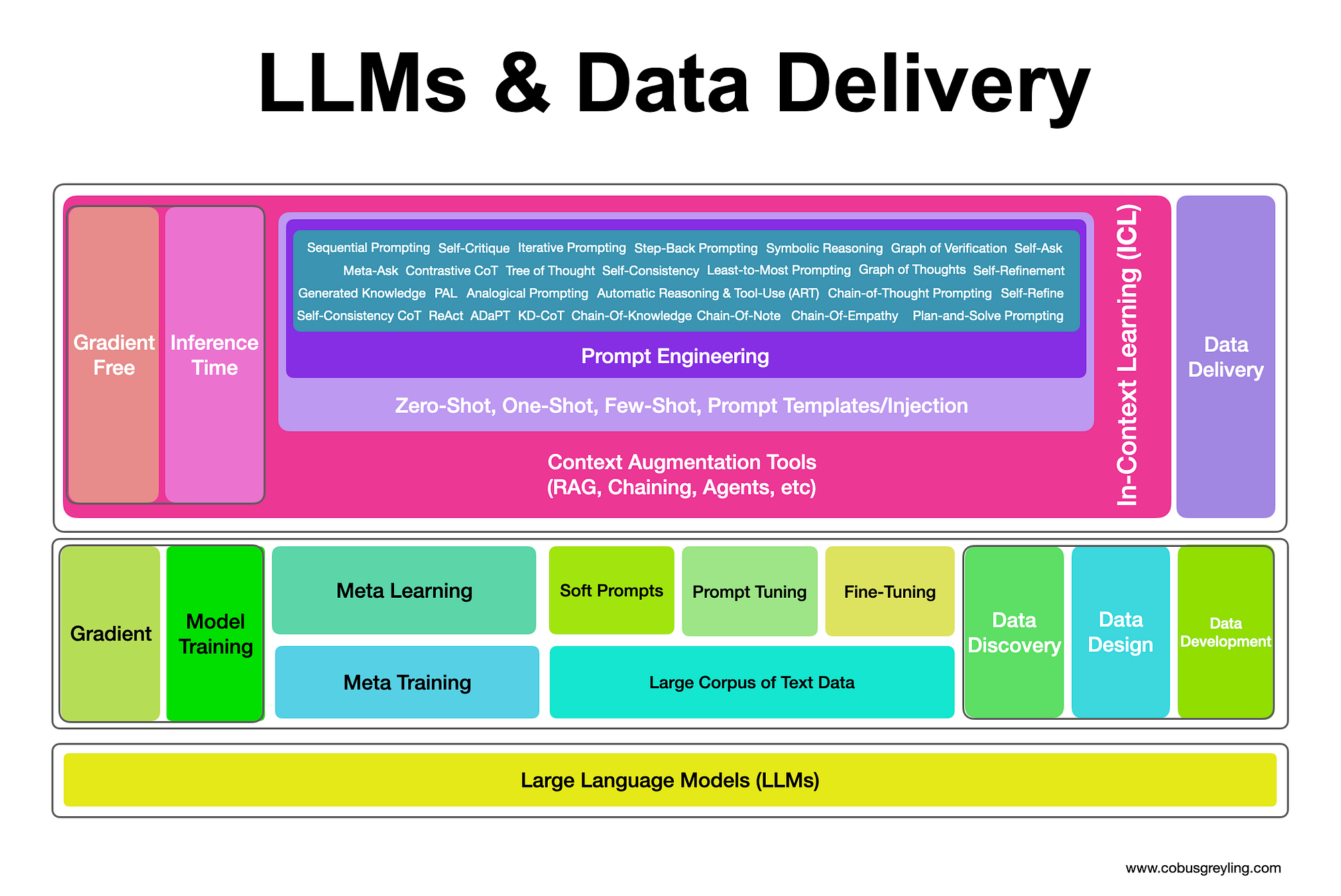
Every AI Strategy should start with a Data Strategy. The Data Strategy should consist of four components: Data Discovery, Data Design, Data Development & Data Delivery.
Data At Inference = Contextual Reference
In order to generate accurate, coherent and succinct responses, an LLM requires access to accurate contextual information to reference.
Recent studies have shown that LLMs excel at In-Context Learning.
The idea that LLMs have Emergent Abilities has created immense hype, with new prompting techniques yielding new and presumed hidden latent abilities of LLMs.
However, studies have shown that in actual fact via new prompt engineering approaches and techniques, in-context learning is being exploited. And subsequently the performance of the LLMs are improving by the advancement of improved contextual references.
Data Delivery
Data Delivery can be best described as the process of imbuing one or more models with data relevant to the use-case, industry and specific user context at inference.
The contextual chunk of data injected into the prompt, is referenced by the LLM to deliver accurate responses in each and every instance.
Often the various methods of data delivery are considered as mutually exclusive with one approach being considered as the ultimate solution.
This point of view is often driven by ignorance, a lack of understanding, organisation searching for a stop-gap solution or a vendor pushing their specific product as the silver bullet.
The truth is that for an enterprise implementation flexibility and manageability will necessitate complexity.

This holds true for any LLM implementation and the approach followed to deliver data to the LLM. The answer is not one specific approach, for instance RAG, or Prompt Chaining; but rather a balanced multi-pronged approach.
Model Training
Data can be delivered to a LLM at two stages, during model training (gradient) or at inference time (gradient-free).
Model training creates, changes and adapts the underlying ML model. This model is also referred to as a model frozen in time with a definite time-stamp.
Model training can again be divided into two sub-categories…
Meta Training & Meta Learning
Meta Training
Meta-training is not something an organisation will perform; generally, I would say. It is rather the process used by model providers to firstly create models and secondly create models of different sizes and different optimisations.
Meta-training typically involves the initial pre-training of a LLM on a massive corpus of text data.
In this phase, the model learns to understand the structure and patterns of language, building a strong foundation of general knowledge and language understanding; going through a pre-training phase where it learns from a wide range of internet text.
The term “meta” in meta-training is used because this training doesn’t involve a specific task or domain adaptation. Instead, it prepares the model to be a versatile language understanding tool that can later be fine-tuned for various tasks or domains. It’s the base training that precedes task-specific learning.
Meta Learning
Meta-learning is the process of fine-tuning an existing LLM for a specific task or domain. This could be considered as the second phase of training, following the meta-training.
During meta-learning, the model is trained on task-specific or domain-specific data and adjusts its parameters to perform well on that specific task or within that specific domain.
Meta-learning can be performed by fine-tuning the model, prompt tuning or a new approach by DeepMind PromptBreeder.
While fine-tuning takes place at a certain point in time, and produces a frozen model which is then referenced over time; approaches like prompt tuning or soft prompts introduce a more flexible and dynamic way of guiding the model.
Instead of a fixed prompt, users provide high-level instructions or hints to guide the model responses.
Inference Time Training
Inference is the moment the LLM is queried and where the model subsequently generates a response. This is also referred to as a gradient-free approach due to the fact that the underlying model is not trained or changed.
Recent research and studies have found that providing context at inference is of utmost importance and various methods are being followed to deliver highly contextual reference data with the prompt to negate hallucination. This is also referred to as prompt injection.
Context and conversational structure can be delivered via RAG, prompt pipelines, Autonomous Agents, Prompt Chaining and prompt engineering techniques.
The advent of LLMs, Foundation Models and Generative AI have given rise to a gold rush of sorts, with companies in a mad dash to develop the ultimate product to leverage the power of these models.
This gave rise to ambitious marketing (to say the least) and a susceptibility to identify one product or a single approach which will solve for all LLM implementation challenges.
The reality is that there is no elixir of sorts to remedy all implementation challenges; the solution most probably lies with a combination of technologies and principles.
Prompting Techniques
In generation time correction, a common theme is to make reasoning decisions on top of the base LLM in order to make them more reliable.
Another promising approach to rectify these flaws is self-correction, where the LLM itself is prompted or guided to fix problems in its own output.
Techniques leveraging automated feedback — either produced by the LLM itself or some external system, are of particular interest as they are a promising way to make LLM-based solutions more practical and deployable with minimal human feedback.
Augmentation Tools
A third approach is to use external tools to help mitigate hallucinations, rather than relying solely on the abilities of the language model itself.
For example, retrieval-augmented generation can decrease hallucinations by using factual documents for grounding or chain-of-thought verification.
Other approaches include using tools for fact-checking or linking to external documents with attribution.
A majority of the methods for reducing hallucination can be divided into roughly three categories: training-time correction, generation-time correction and via augmentation (tool-use). ~ Source
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.