Exciting Conversational AI Trends & Areas Of Development
In this article I address three areas of rapid development and growth in Conversational AI currently. These areas include Voicebots (as part of Contact Centre AI), Data-Centric Tooling and Large Language Models (LLMs). Recently I published an updated matrix of the Conversational AI landscape, which was segmented into five broad categories. Apart from the traditional chatbot development frameworks and chatbot tooling, I included two additional categories; those being Large Language Models and data-centric latent space Conversational AI tooling.

The TL;DR
- There are a number of exciting emerging technologies receiving overdue focus currently due to market demands, this is especially the case with voicebots driving Contact Centre AI and automation.
- There is a dire need from Customer Care Executives to automate calls into the contact centre.
- Data-Centric tooling will in the near future receive massive attention and will be an area of rapid growth and focus. I say this due to two reasons…
- Firstly, I recently coined the term Intent Driven Design & Development. In a recent Gartner report, laser focus was placed on starting with intents.
- Secondly, in many instances chatbot implementations are not yielding the promised results, and by leveraging data-centric tooling vital insights can be gleaned.
- Below the updated matrix with updated categories 4 and 5.

Data-Centric Tooling
All of the commercial LLMs have playgrounds where models can be selected and functionality tested. There are options for fine-tuning but in most cases fine-tuning is pro-code and technical and fine-tuning is not as granular or pin-pointed as it needs to be.
I have alluded to this before, there exist a chasm which needs to be filled here. The best way to describe this technology void is in the following way:
- A latent space where conversational data can be manipulated with focus on similarity detection and clustering semantically similar data.
- A latent space can be seen as a form of data compression, where insights are surfaced.
- No-code data-centric tooling geared towards Intent Driven Design & Development.
- There is much talk of designing and developing for the long-tail of NLU. I’m of the persuasion that the long-tail exist within the current customer conversation, seeing companies’ chatbots and voicebots are very domain specific. It just needs a sufficiently advanced data-centric tool for discovery, structuring data and training a model.
- This discovery should be both supervised and unsupervised. Where conversation data and user utterances are automatically assigned to existing intents. Or where the data is clustered without any pre-existing intents, but merely on semantic similarity.
Voicebots & Contact Centre AI (CCAI)
Enterprise demand is driving the implementation of voicebots. Due to the fact that Speech-To-Text (STT) and Text-To-Speech (TTS) are both highly specialised technologies, chatbot development frameworks need to look outward to service these voicebot elements.
STT is also referred to as Automatic Speech Recognition (ASR) & TTS is referred to as Speech Synthesis.
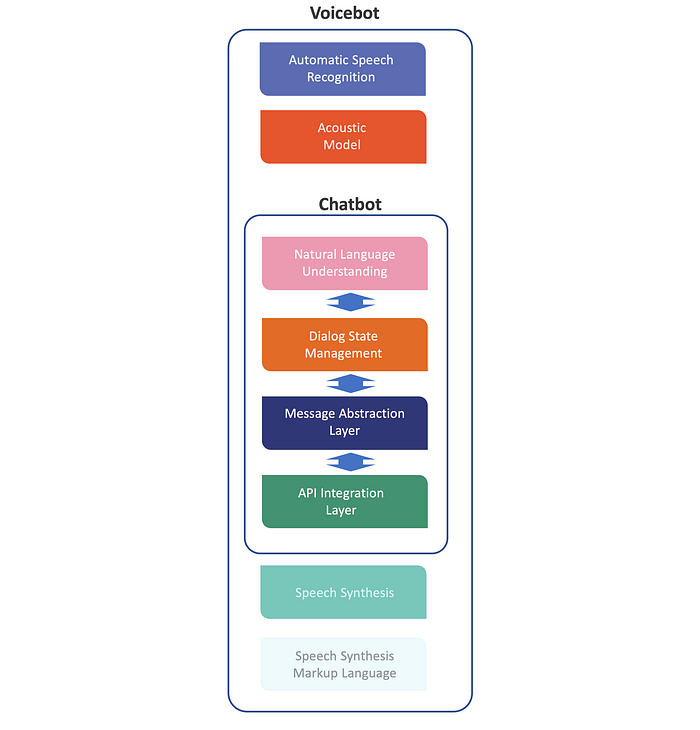
Only the large cloud providers have their own in-house STT and TTS, these include Nuance, NVIDIA, IBM, Microsoft and AWS. There are companies who specialise in these segments, of which are Resemble AI, Respeecher, Deepgram, and more.
Large Language Models (LLMs)
In a previous post I compiled two graphics. The first being a chart breaking down different components of LLMs and which LLMs currently exist in each of those components.
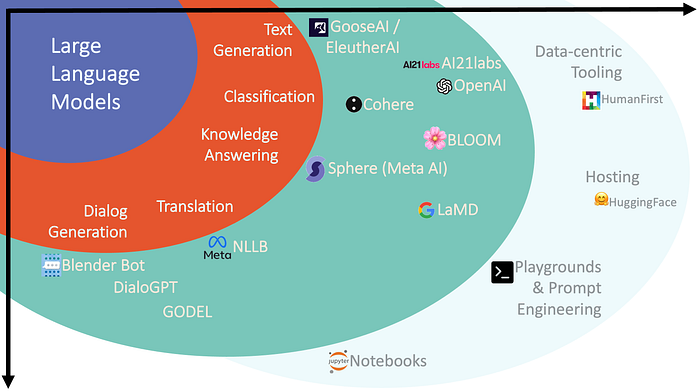
The chart ends with the current existing tooling ecosystem, which is severely lacking at this stage, especially from a no-code data-centric UI perspective.
I also created a matrix listing the existing LLMs, both commercial and open-sourced, and the key functionalities of each model. I do realise this is not an exact science and that there are overlaps, etc. This will always be the case when distilling a complex environment into an easy digestible matrix.
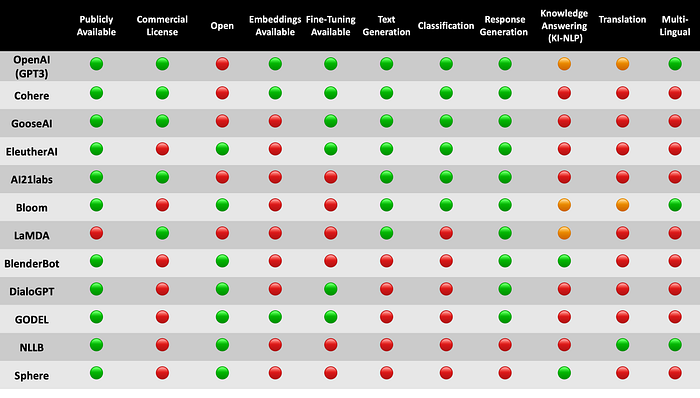
What I find compelling here is that even with LLMs, there are specific focus on certain areas. For instance, there are LLMs focussing on langauge translation, text generation (fuelled by prompt engineering), embeddings for semantic searches and semantic similarity clustering, etc.
And Finally
I recently asked the question, will the Conversational AI landscape become more fragmented?
Considering the market requirements for voice, data-centric tooling and the power of LLMs, this certainly seem to be the case…