Concise Chain-of-Thought (CCoT) Prompting
Traditional CoT comes at a cost of increased output token usage, CCoT prompting is a prompt-engineering technique which is aimed at reducing LLM response verbosity & inference time.
LLM-based generative AI apps will have to be optimised using a multi-pronged approach. An approach which considers prompt structure, data delivery, token use and inference latency. Together with LLM orchestration; using the best model for the best task. And a data centric approach for data discovery, design and development.
Introduction
A recent study introduced a new prompting technique called Concise Chain-of-Thought (CCoT).
In this study, standard CoT is compared to CCoT prompting with regard to response length and accuracy.
For multiple-choice Question-and-Answer CCoT reduces the response length by 48.70%. Hence CCoT introduces savings on output token costs and more condensed answers.
The study also found that problem-solving performance remain unchanged between the two approaches of CoT and CCoT.
For math problems CCoT incurs a performance penalty of 27.69%.
Overall, CCoT leads to an average token cost reduction of 22.67%.
Chain-Of-Thought (CoT)
CoT has been nothing less than a phenomenon in terms of LLMs, spawning a slew of CoT based prompting techniques. And giving rise to the Chain-of-X phenomenon.
CoT prompting has been shown to improve LLM performance by up to 80% for certain problem tasks and problem domains.
However, these performance improvements come at a literal cost, with added expenses in terms of increased output token usage. Added to this, inference time is also extended.
CoT explicitly encourages the LLM to generate intermediate rationales for solving a problem. This is achieved by providing a series of reasoning steps in the demonstrations for the LLM to emulate.
More On CCoT
Cost & Latency
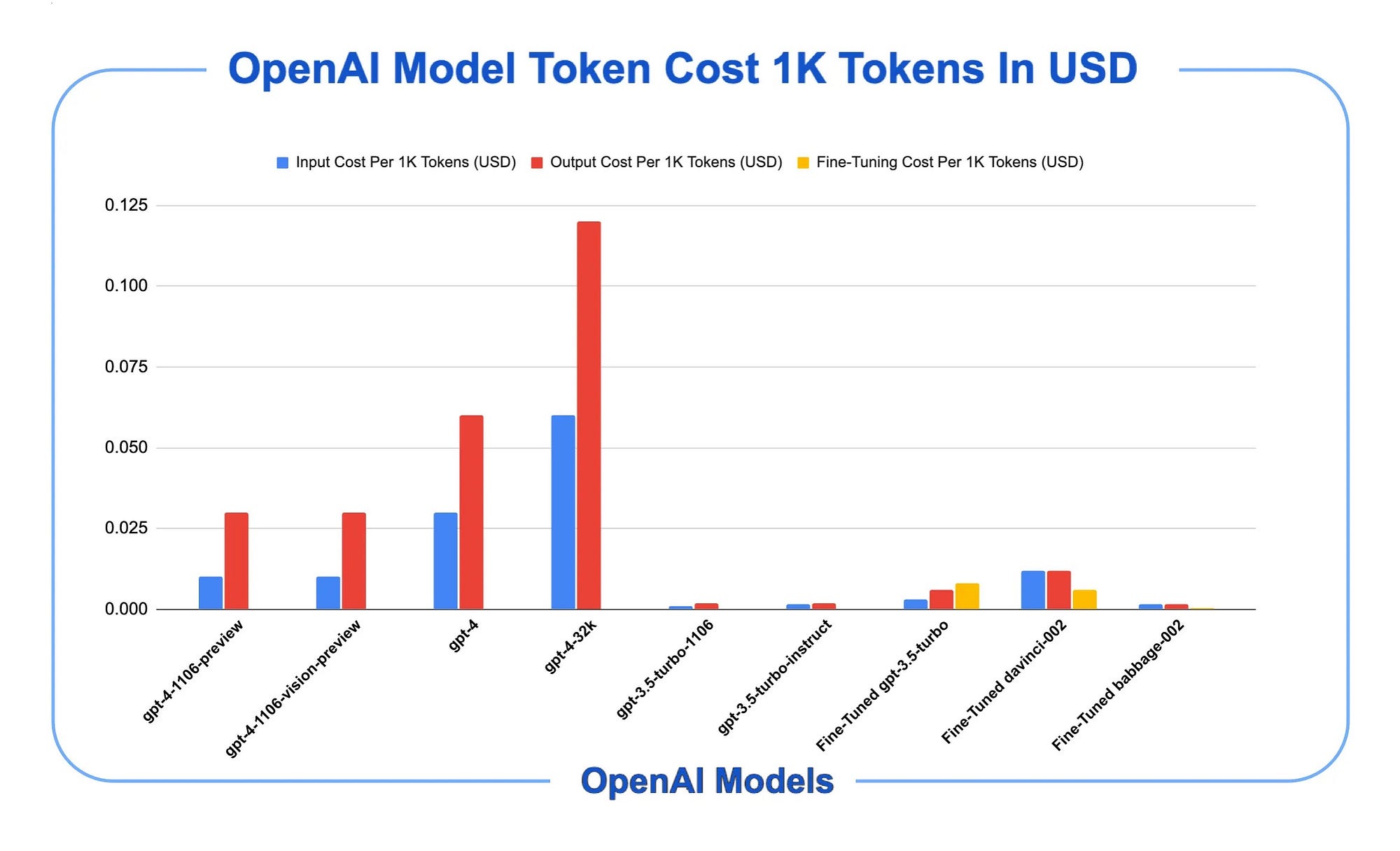
If CCoT reduces response length then CCoT can be used to reduce LLM costs. Third-party LLM APIs are typically priced per token with output tokens being more expensive than input tokens.
As can be seen in the graph below, the red bars indicate the output token cost, compared to the input token cost in blue.
Inference latency is also a challenge, which can be addressed to some degree by ensuring the responses are shorter. This can be achieved with no deprecation in performance; the study finds that CCoT comes with no performance penalty in this regard.
Practical Comparison
Below is an example of an answer-only prompt, followed by a traditional verbose CoT prompt. And lastly a CCoT prompt.
Below an answer-only prompt.

And here a comparison between verbose and concise CoT prompting.

Possible Limitations
The study only made use of GPT LLMs, it would be interesting to see the performance on open-source and less capable LLMs.
The study only made use of a single CoT and CCoT prompt. As a result, other variations of CoT and CCoT prompts may produce different results.
Considering the variation in prompt performance over different tasks, the thought comes to mind that an implementation of user intent triage can work well.
And user input is classified in order to make use of orchestrating multiple LLMs, selecting the most appropriate prompting technique, etc.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.