
Managing Your OpenAI Token Use
In this article I explain OpenAI token usage for model input, output & fine-tuning. And how to convert text into tokens to calculate token-use cost.
I would like to start with a few assumptions I hold regarding the LLMs and production implementations…and I truly welcome any correction and examples illustrating the contrary. 🙂
Assumptions
I get the impression that most LLM use-cases and implementations are focussed on experimentation and design-time use-case implementations (as opposed to run-time implementations).
It seems like LLM-based large-scale enterprise implementation are virtually non-existent at this stage and most LLM implementations are focussed on specific use-cases which is not primarily realtime, but non-realtime analysis.
This includes bulk conversion of speech into text for Natural Language Processing, summarisation, intent and entity recognition, etc.
A basic understanding of the market is lacking, ChatGPT and GPT have become generic terms for everything related to LLMs.
There is no distinction made between the raw LLMs, LLM APIs and end-user UIs like HuggingChat, Cohere Coral, ChatGPT and others.

I also get the impression that not much attention is being given at token cost, which might indicated a slant towards more design time use, experimentation, tinkering and personal use. As opposed to high value, high value implementations.
OpenAI Token Pricing
What Is A Token
OpenAI calculates cost in terms of tokens. A price in USD is assigned to 1,000 tokens.
Different token encodings are linked to different models, so this needs to be kept in mind when converting text into tokens, to be cognisant of what model will be used.
Consider the encoding name being linked to a specific OpenAI model.

Tokenising
Tiktoken is an open-source tokeniser by OpenAI. To better explain it, below are three lines of code, defining the encoding base, the OpenAI model and the sentence to be encoded or tokenised.
encoding = tiktoken.get_encoding("cl100k_base")
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
encoding.encode("How long is the great wall of China?")
And, below the tokens created by Tiktoken…
[4438, 1317, 374, 279, 2294, 7147, 315, 5734, 30]The line of code below gives the number of tokens…
num_tokens_from_string("How long is the great wall of China?", "cl100k_base")In this case it is nine.
9The token encoding can be decoded as the shown below in a snippet from the Colab notebook; and in the second like, the single tokens are broken down.

Model, Input & Output Considerations
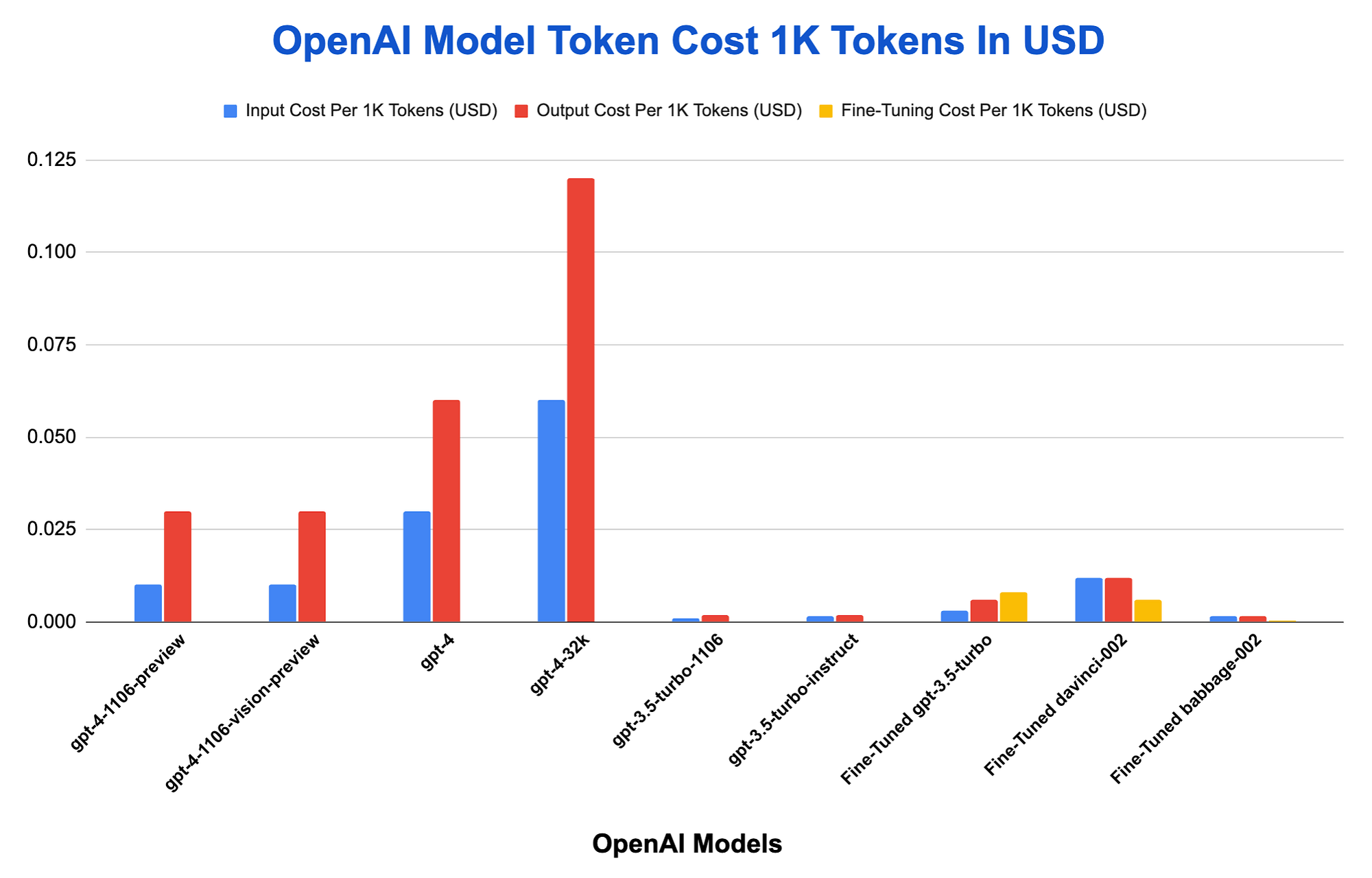
Considering the graph below, it is interesting to note that the output token cost (red) is much higher than the input token cost (blue). It is also interesting to note the cost of the 32k context window version of GPT-4–32k window, where the input and especially the output token cost is high.
Fine-Tuning Considerations
The fine-tuning cost per token (yellow) seems to be quite low in contrast to the other models. Enterprises will have to find a balance between model performance, fine-tuning cost, and the regularity with which the model will have to be updated.
Multiple models, each with different capabilities and price points. Prices are per 1,000 tokens. You can think of tokens as pieces of words, where 1,000 tokens is about 750 words. This paragraph is 35 tokens.
~ OpenAI
Finally
LLM-based Autonomous Agents, Prompt Chaining and recent prompting techniques have one thing in common, and that is that multiple requests are made to the LLM.
For instance, below the sequence followed by an autonomous agent is visible, token used and cost can be tracked for each of the agent iterations.
Below you see how a single call to an agent is decomposed into all the steps followed by the agent, and the tools used. With the LLM input and output along the way.
Notice how the tokens and latency are given within the agent trace; and how it is possible to navigate from node to node with relevant data being surfaced.
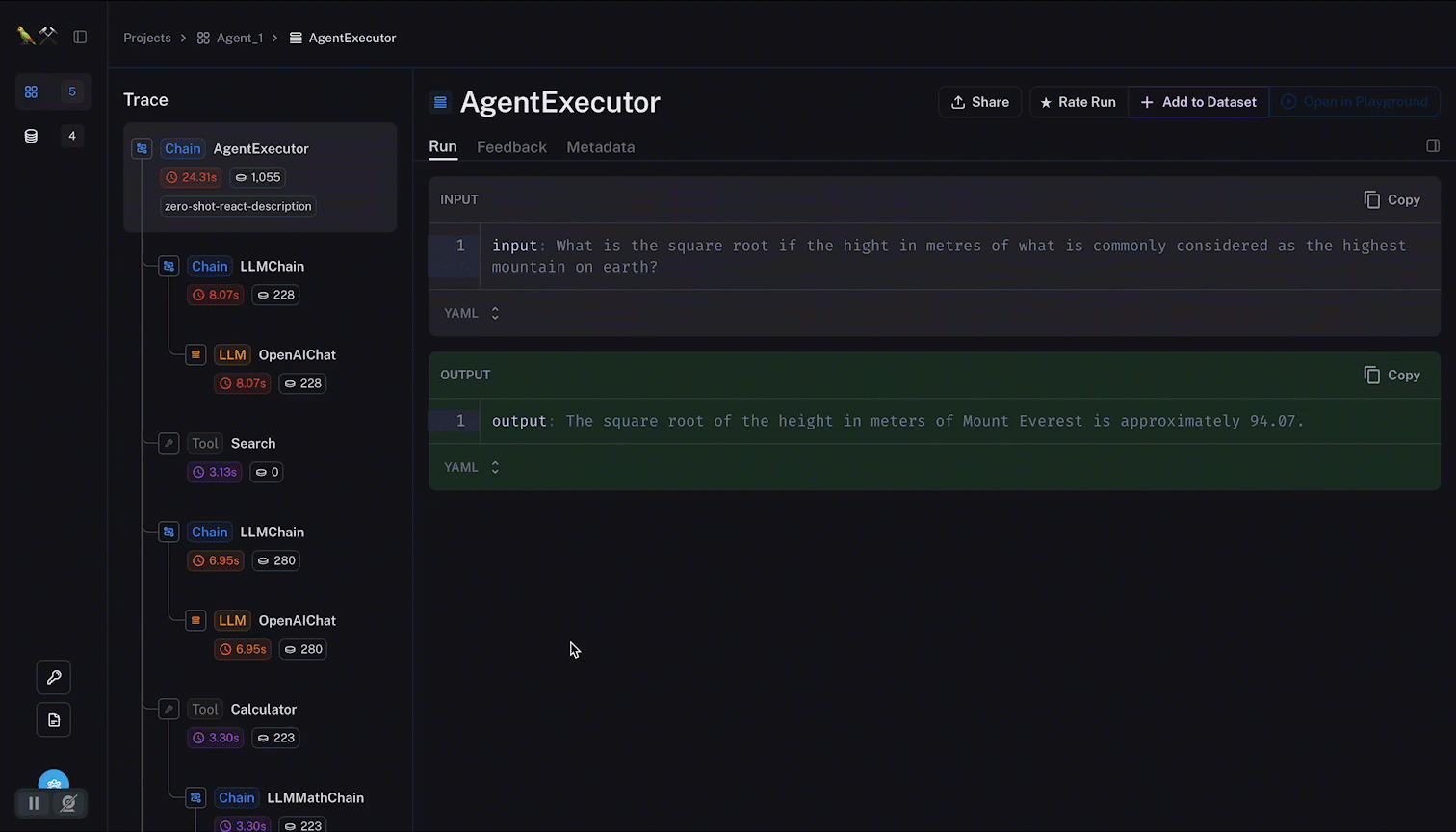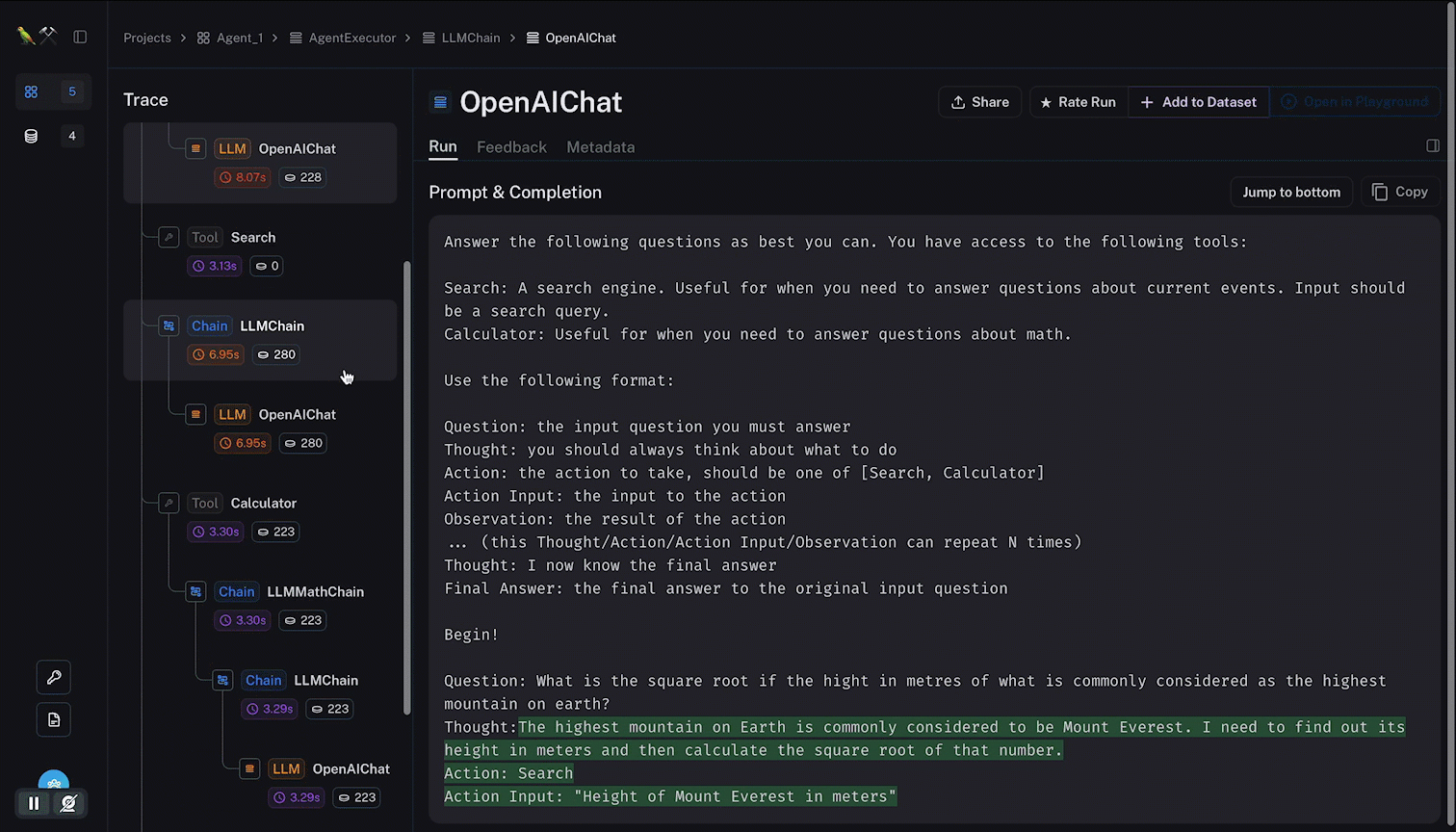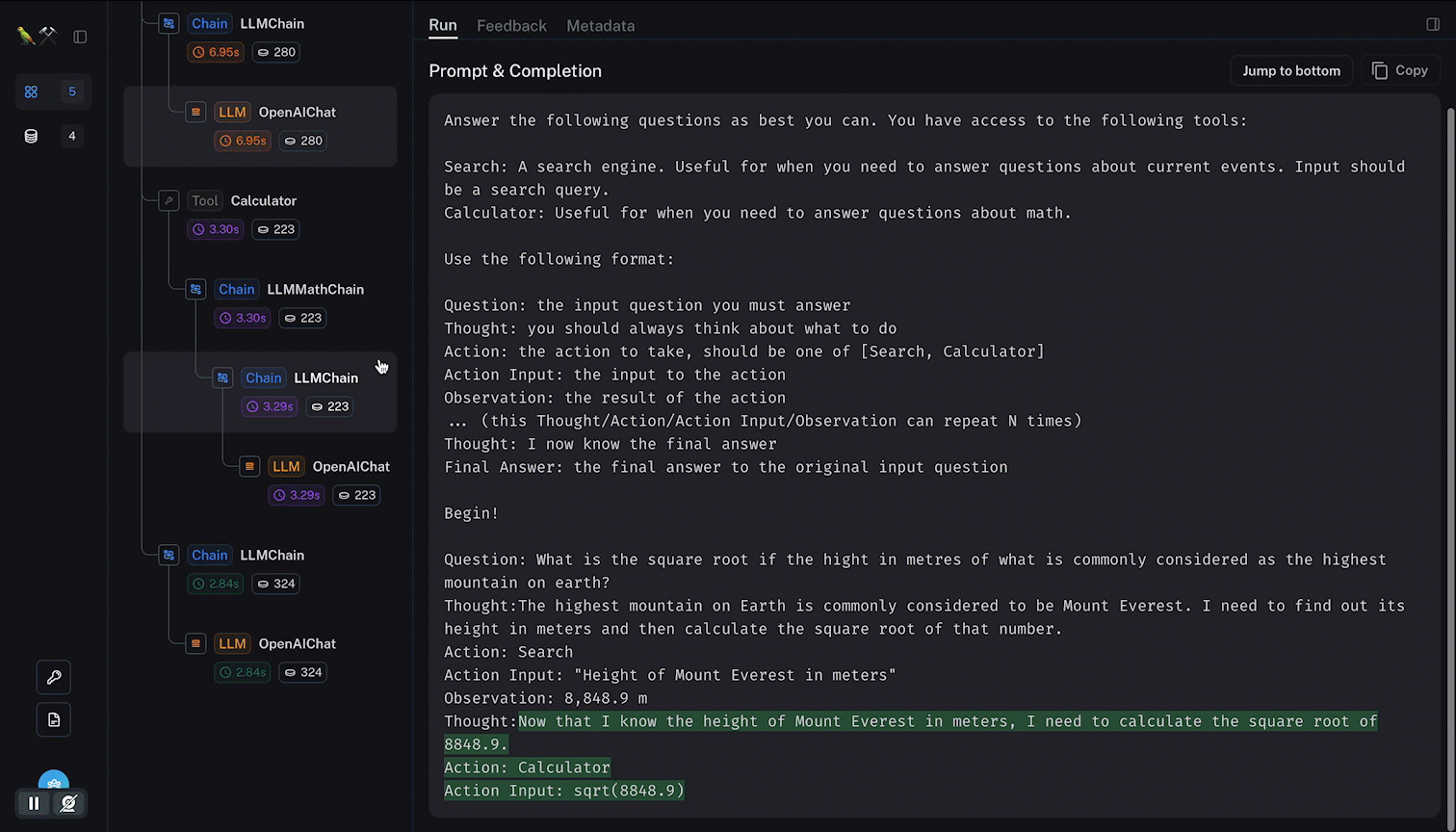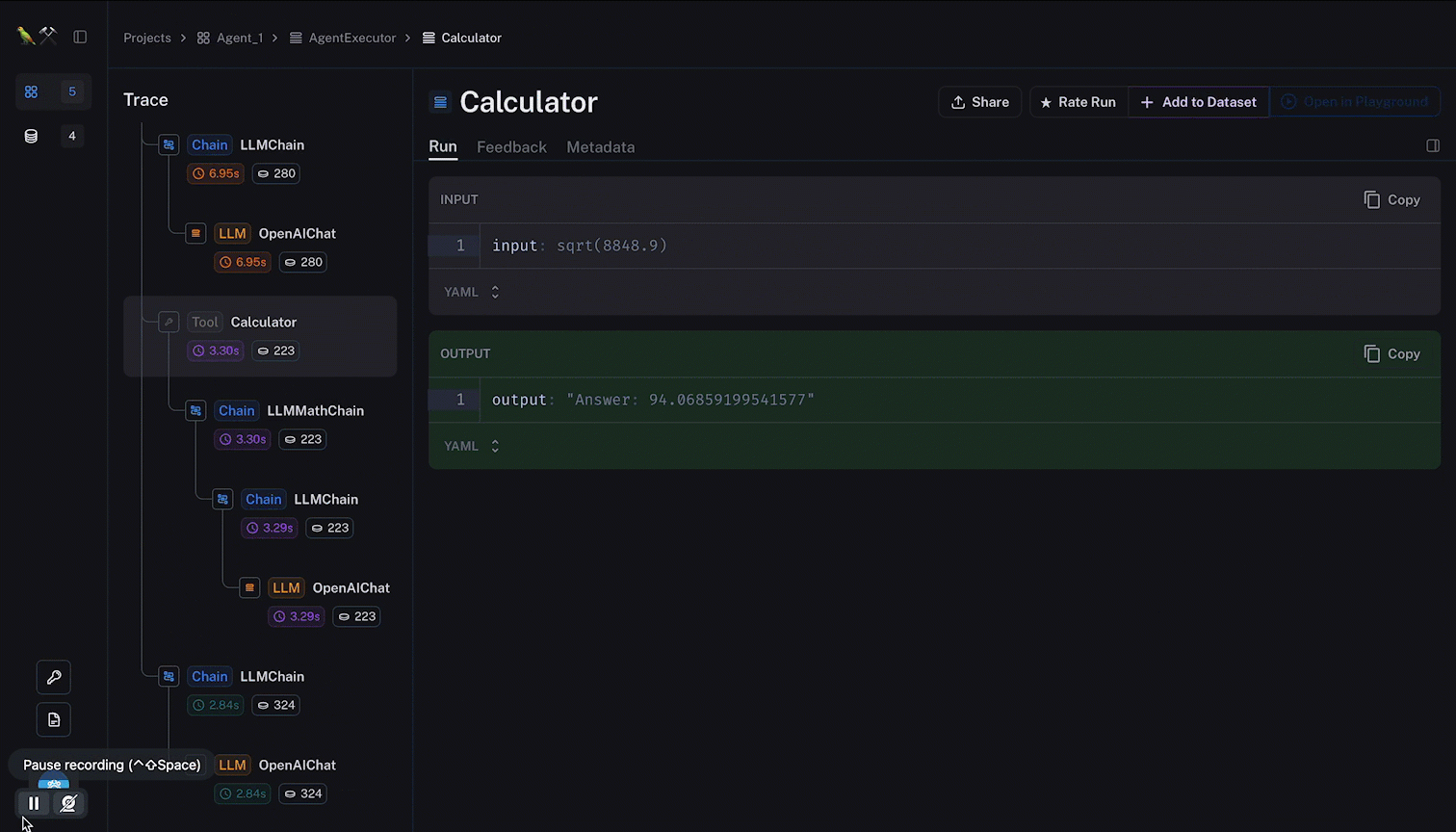
As these complex implementations grow, the need for token management will increase due to the number of inferences made for a single agent run.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.


https://platform.openai.com/docs/guides/text-generation/managing-tokens
