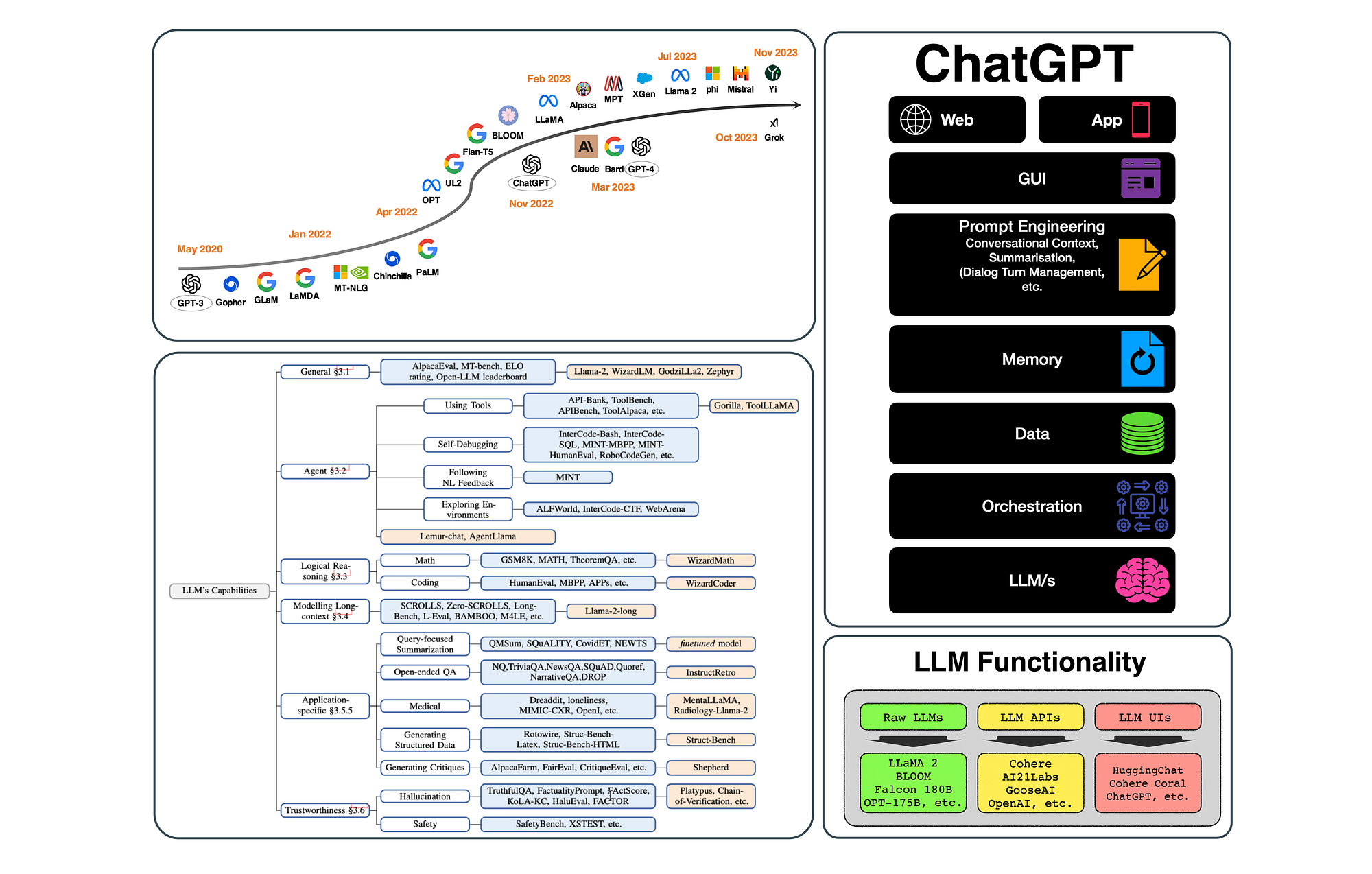
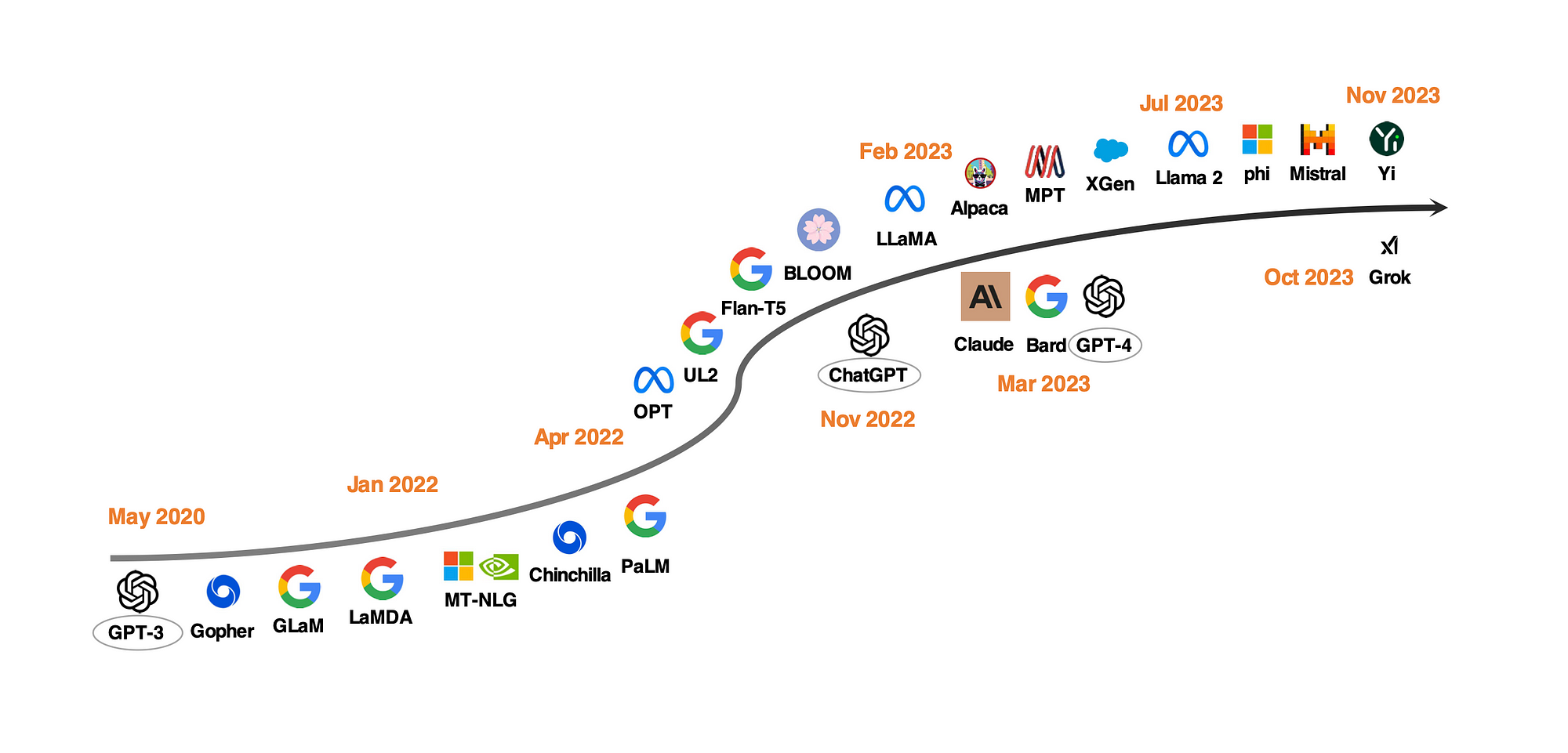
ChatGPT Is One-Year Old: Are Open-Source Large Language Models Catching Up?
A recent study examined and highlighted tasks where open-source LLMs are on par or better than GPT models.
Overview
A few findings from the study are:
For general capabilities, Llama-2-chat-70B shows improvement over GPT- 3.5-turbo in some benchmarks, but remains behind for most others.
There are also several domains where open-source LLMs are able to surpass GPT-3.5-turbo.
For LLM-based agents, open-source LLMs are able to surpass GPT-3.5-turbo with more extensive and task-specific pre-training and fine-tuning.
For example, Lemur-70B-chat performs better in exploring the environment and following feedback on coding tasks.
ToolLLama can better grasp tool usage. Gorilla outperforms GPT-4 on writing API calls.
For logical reasoning, WizardCoder and WizardMath improve reasoning abilities with enhanced instruction tuning.
Lemur and Phi achieve stronger abilities by pre-training on data with higher quality.
For modelling long contexts, Llama-2-long can improve on selected benchmarks by pre-training with longer tokens and a larger context window.
For application-specific capabilities, InstructRetro improves on open-ended QA by pre-training with retrieval and instruction tuning.
With task-specific fine-tuning, MentaLlama-chat- 13B outperforms GPT-3.5-turbo in mental health analysis datasets.
For trustworthy AI, hallucinations can be reduced by fine-tuning with data of higher quality, context-aware decoding techniques , external knowledge augmentation or multi-agent dialogue.
For trustworthy AI, hallucinations can be reduced by:
- Fine-tuning with data of higher quality
- Context-aware decoding techniques
- External knowledge augmentation
- Multi-agent dialogue
There are also domains where GPT-3.5-turbo and GPT-4 remain unbeatable…
Such as AI safety, due to the large-scale RLHF involved in GPT models, they are known to demonstrate safer and more ethical behaviours, which is probably a more important consideration for commercial LLMs compared to open-source ones.
There are also several domains where open-source LLMs are able to beat GPT-3.5-turbo.
Terminology
A basic understanding of the market is lacking, ChatGPT and GPT have become generic terms for everything related to LLMs.
In general, virtually no distinction is made between the raw LLMs, LLM APIs and end-user UIs like HuggingChat, Cohere Coral, ChatGPT and others.
ChatGPT has democratised and popularised Large Language Models (LLMs), but ChatGPT is not a LLM per se. ChatGPT is a LLM-based User Interface, which delivers an exceptional user experience. The elements which (most probably) constitute ChatGPT are listed below.
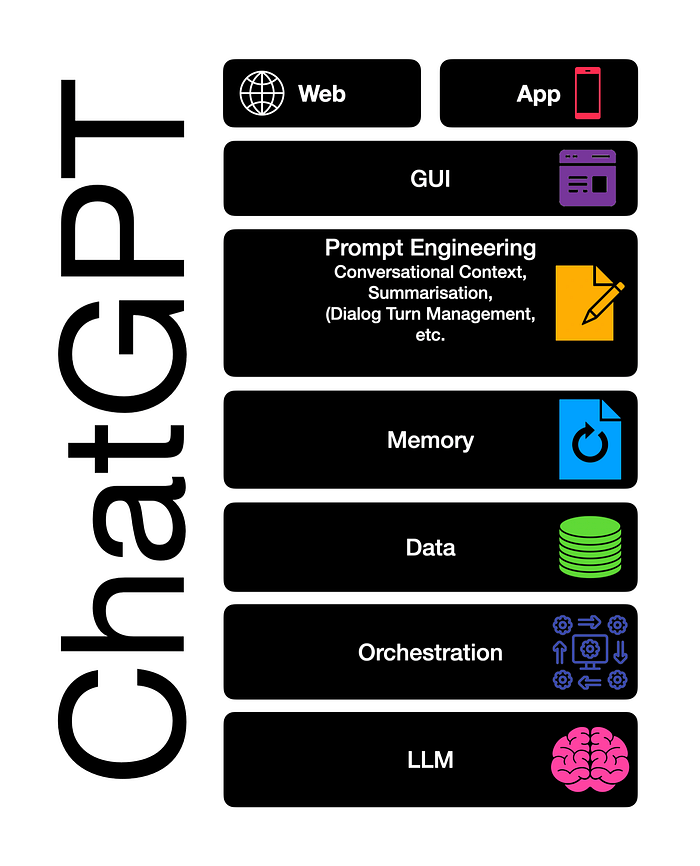
The terms GPT, ChatGPT and LLMs are also used interchangeably…considering the image below, LLM technology can be broken down into three groups.
Raw LLMs
Raw LLMs are Large Language Models which have been available, and are in most cases open-source. These LLMs required to be hosted somewhere, managed and made available via some managed interface.
LLM APIs
What most people today refer to as LLMs, are primarily exposed APIs to access LLMs. These APIs have a host of input and output parameters, and the layer between the surfaced API and the LLM is opaque; with the user not being aware of what is happening under the hood.
OpenAI has introduced a fingerprint functionality, to alert users to underlying model changes.
LLM User Interfaces
LLM UIs include user interfaces like Cohere Coral, HuggingChat and ChatGPT. These interfaces perform instructions while implicitly or explicitly save user preferences and more.
The objective of these UIs is to present users with a LLM-based chatbot (conversational UI) which enables users to refine and steer a conversation towards a desired length, format, style, level of detail, and language.

Back To ChatGPT
Since ChatGPT is not open-sourced and its access is controlled by a private company, most of its technical details remain unknown. Despite the claim that it follows the procedure introduced in InstructGPT (also called GPT-3.5) — Source
Risks
The study highlights enterprises adopting ChatGPT should be concerned with the heavy cost of calling APIs, service outages, data ownership and privacy issues, and other unpredictable events such as the recent boardroom drama.
The study includes the typology shown below. This maps out the capabilities of LLMs and the best performing open-LLMs.
White Boxes: denote domains,
Blue Boxes: Represent Specific Datasets,
Orange Boxes: denote open-sourced LLMs.

LLM Training Regimes
Pre-Training (Gradient)
All LLMs rely on large-scale self-supervised pre-training on Internet text and other data.
Fine-Tuning (Gradient)
Fine-tuning aims to adapt a pre-trained LLM to specific downstream tasks, by updating weights with the available supervision, which usually forms a dataset orders of magnitude smaller than the one used for pre-training.
Instruction-Tuning (Gradient)
.Instruction-tuning gained popularity, due to its ability to drastically improve zero-shot performance of LLMs, including on new tasks (unseen during training), and especially at larger models scale.
Continual Pre-Training (Gradient)
Continual pre-training consists of performing another round of pre-training from a pre-trained LLM, typically with a lesser volume of data than in the first stage. Such process may be useful to quickly adapt to a new domain or elicit new properties in the LLM.
Inference (Non-Gradient)
What has been mistaken as emerging capabilities of LLMs were all the time users utilising in-context learning better. The notion of Emergent Abilities also creates immense market hype, with new prompting techniques and presumed hidden latent abilities of LLMs being discovered and published.
However, a recent study shows that as models scale and become more capable, the discipline of prompt engineering is used to develop new approaches to leverage in-context learning, as we have seen of late…
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.