What Are Realistic GPT-4 Size Expectations?
This article aims to cut through the hype by considering historic scaling and current trends of existing LLM models.

An August 2021 article from Wired first rumoured the possibility of 100 Trillion parameter GPT-4 model…
More recent astute commentaries concluded that everything is in the air regarding GPT-4’s size…but what would be a reasonable expectation in terms of GPT-4?
The short answer is that OpenAI’s GPT-4 will be closer to 1 Trillion parameters, as shown in the image below.
This is in stark contrast with the widely shared big circle graphic of a 100 Trillion Parameter GPT-4 model next to the small dot of a 175 Billion Parameter GPT-3…
I say this for 3️⃣ reasons…
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
1️⃣ The LLM Trends point to a one trillion model, or close to it.
A billion = 1,000,000,000 & a trillion = 1,000,000,000,000
The graph below shows how a one trillion GPT-4 model compares to existing Large Language Models (LLMs).
The graph also include models which are not yet generally available, like Google’s PaLM model and LaMDA. The graph clearly shows the progression and relative scale of models in sheer parameters.
From this graphic it should be evident how model sizes are scaling and what realistic expectations should resemble.
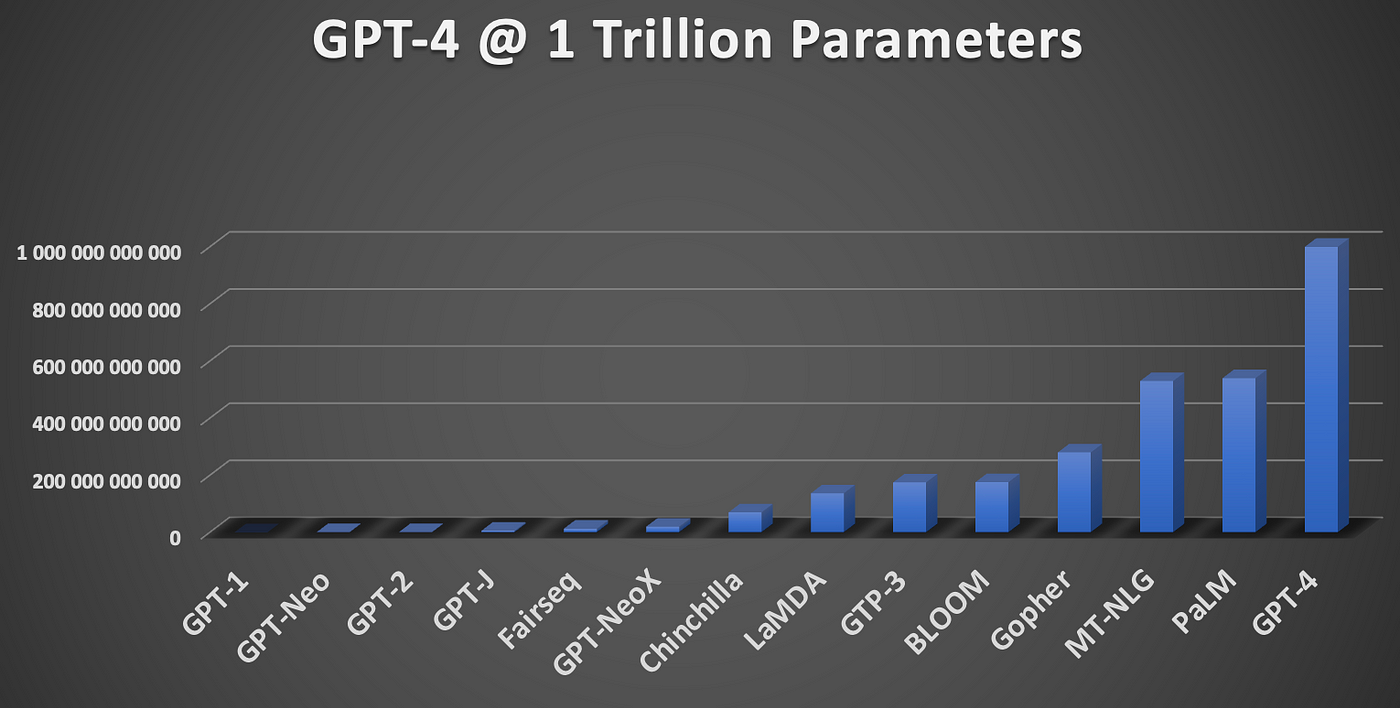
The data constituting the graph:
GPT-1 117 000 000
GPT-Neo 1 300 000 000
GPT-2 1 500 000 000
GPT-J 6 000 000 000
Fairseq 13 000 000 000
GPT-NeoX 20 000 000 000
Chinchilla 70 000 000 000
LaMDA 137 000 000 000
GTP-3 175 000 000 000
BLOOM 176 000 000 000
Gopher 280 000 000 000
MT-NLG 530 000 000 000
PaLM 540 000 000 000
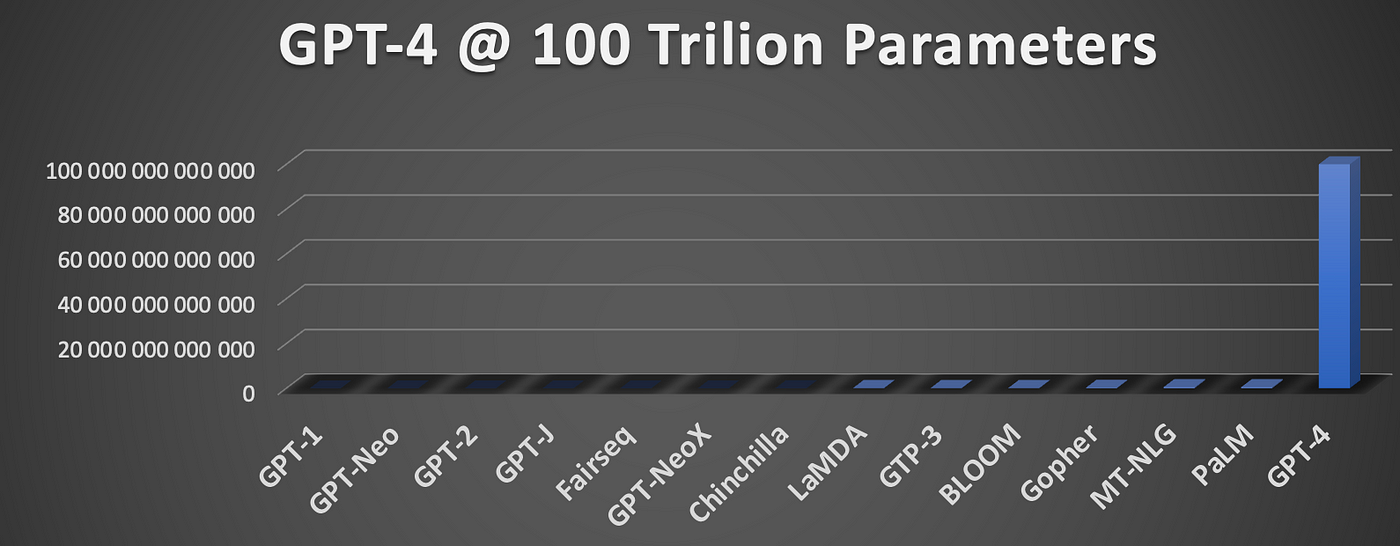
GPT-4 1 000 000 000 000Considering the same graph with GPT-4 at 100 Trillion Parameters below…it is evident that there is no correlate with the natural progression of LLMs.
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
2️⃣ The Experts point to a scenario of less parameters, not more
I recently posed the question on LinkedIn, regarding the GPT-4 parameter count.
Below is an authoritative and astute comment from Gregory Whiteside on that post:
I was fortunate to be invited to the Scale X event where Greg Brockman was speaking (among other people who obviously know a lot more than us where all of this is going) — size of model isn’t the only thing that will allow performance to continue improving, but what they’re seeing is that size / number of parameters is directly correlated with ability to generalize / be applied to newer and more powerful tasks.
The quality / type of data being used to train these models is also going to keep improving (my guess is that Whisper was released as an open model to accelerate the creation of high-quality voice transcripts to feed the next generation of LLMs with a completely new source of high-value data: voice).
A second quote by Gregory Whiteside leads me to the third point…
My hunch would be that OpenAI released Whisper as an open model (instead of monetizing it like their other APIs) to accelerate this high-quality STT data availability — if every single publicly available video / audio on the net comes with high-quality transcriptions (without OpenAI paying for it), makes OpenAI’s job cheaper / faster.
There also other authoritative sources citing caution in exaggerating the GPT-4 parameter count.
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
3️⃣ There is only so much quality data
A recent study found that stock of high-quality language data will be exhausted in all likelihood by 2026. In contrast, low-quality language and image data will be exhausted only between 2030 and 2050.
The study also found that the current growth of LLM size will slow down if the data efficiency does not improve or new sources of data become available.
Language datasets have grown exponentially by more than 50% per year, and contain up to 2e12 words as of October 2022.
The stock of language data currently grows by 7% yearly, but our model predicts a slowdown to 1% by 2100.
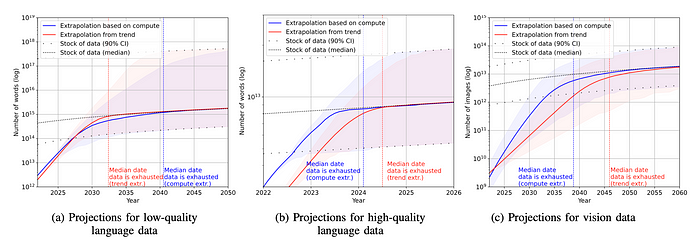
Each graph shows a representation of data usage with past trends and projections.
Thanks to Julien Simon for pointing out this study.
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
In Conclusion
There are two elements which capture the imagination of the general public when it comes to AI.
The first is the sheer number of parameters which make for really captivating graphics. 🙂
The second is the ability of a LLM to have a natural, general conversation without any form of training, Like ChatGPT.
For enterprise adoption however, there is a requirement to fine-tune LLMs and train these vast models on specific use-case related data.
From a Chatbot / Digital Assistant perspective, intent classification is front of mind.

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.