UniMS-RAG: Unified Multi-Source RAG for Personalised Dialogue
Considerable development has taken place in the area of RAG, especially in adding structure and multi-document approaches.
This study explores how the RAG process can be decomposed, adding elements like multi-document retrieval, memory and personal information.
Overview
- Large Language Models (LLMs) excel in natural language tasks but face challenges in personalisation & context within dialogue systems.
- The study proposes a Unified Multi-Source Retrieval-Augmented Generation system (UniMS-RAG) to address personalisation issues by decomposing tasks into Knowledge Source Selection, Knowledge Retrieval, and Response Generation.

- The system includes a self-refinement mechanism that iteratively refines generated responses based on consistency scores between the response and retrieved evidence.
- Experimental results demonstrate UniMS-RAG’s state-of-the-art performance in knowledge source selection and response generation tasks.

- The diagram above, shows two scenarios, where the user and bot persona are independent and (in the second example) inter-dependent.
- For the inter-dependent approach there needs to be evaluation tokens, and acting tokens.
Considerations
Knowledge Source Selection
Intelligent and accurate knowledge source selection, together with synthesising multiple information sources into one coherent and succinct answer will become crucial.
Introduction of Complexity
One of the allures of RAG use to be the simplicity of implementation. However, considerable work is being done in terms of Agentic RAG, multi-document search and adding elements like conversational history and more.
Agentic RAG is where a hierarchy of agents are combined with a RAG implementation. The introduction of complexity and enhanced intelligence are inevitable.
Personalisation & Context
Personalisation and maintaining context via conversational history are both important elements for stellar UX. UniMS-RAG prioritises these elements with their proposed RAG structure.
Continuous improvement
The study includes an algorithm for Inference with Self-refinement, coupled with the fact that RAG in general lends a great degree of inspectability and observability.
UniMS-RAG Framework
UniMS-RAG unifies the training process for planning, retrieving, and reading tasks, integrating them into a comprehensive framework.
Leveraging the power of large language models (LLMs) to harness external knowledge sources, UniMS-RAG enhances LLMs’ ability to seamlessly connect diverse sources in personalised knowledge-grounded dialogues.
This integration simplifies the traditionally separate retriever and reader training tasks, allowing adaptive evidence retrieval and relevance score evaluation in a unified manner.
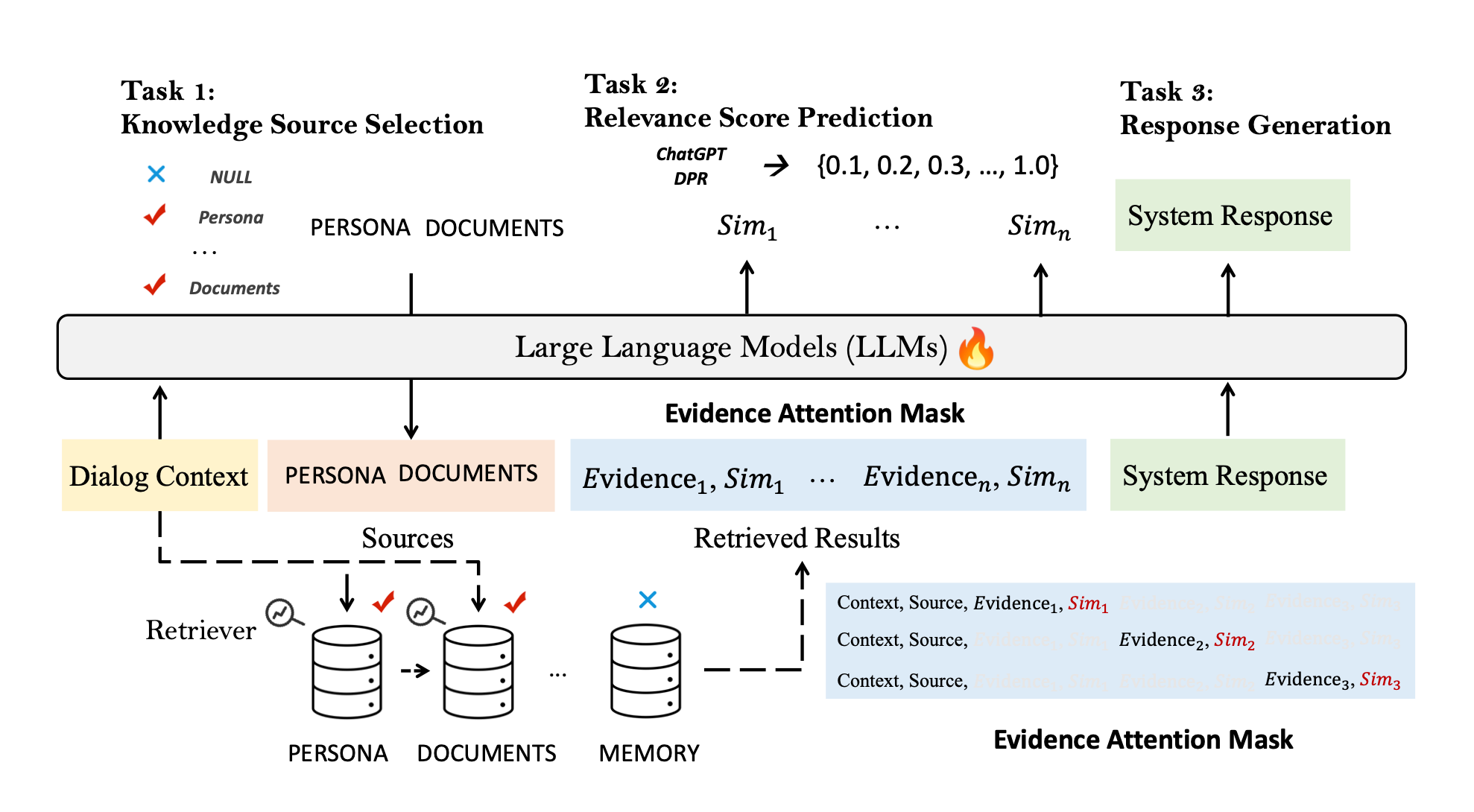
The image below is an illustration of the proposed method called UniMS-RAG. Three optimisation tasks are carefully designed:
- Knowledge Source Selection
- Relevance Score Prediction
- Response Generation.
Planning
This is the process of creating a series of decisions on which specific knowledge source should be used, given the relationship between different sources.
Retrieval
Retrieve the top-n results from external databases according to the decisions.
Generation
Incorporate all retrieved knowledge into the final response generation.
Final Thoughts
This approach seeks to address personalised knowledge-grounded dialogue tasks in a multi-source setting, breaking the problem into three sub-tasks: knowledge source selection, knowledge retrieval, and response generation.
The proposed Unified Multi-Source Retrieval-Augmented Dialogue System (UniMS-RAG) uses Large Language Models (LLMs) as planners, retrievers, and readers simultaneously.
The framework introduces self-refinement during inference, refining responses using consistency and similarity scores.
Experimental results on two datasets show UniMS-RAG generates more personalised and factual responses, outperforming baseline models.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.