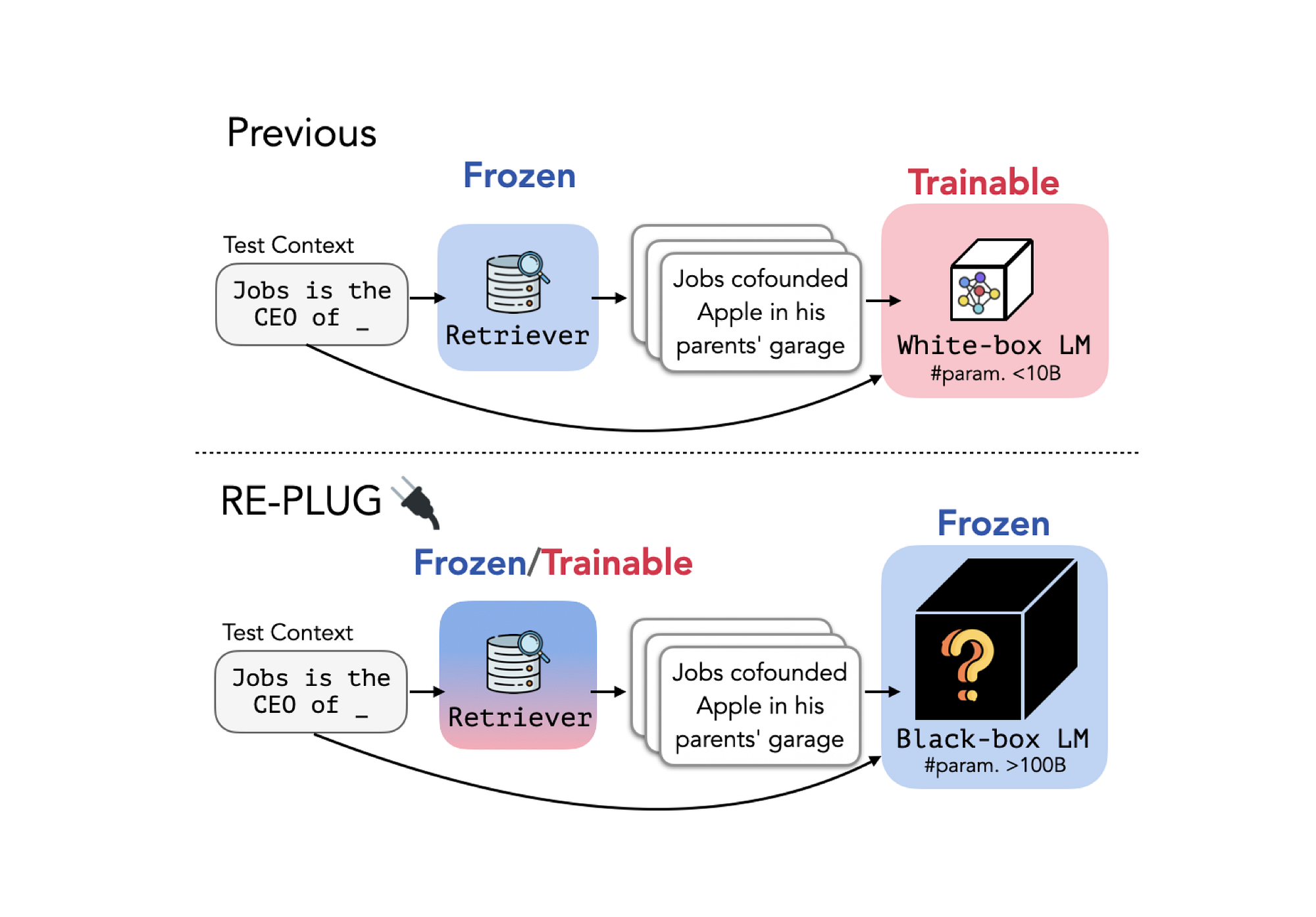
Treating An LLM As A Black Box & Augmenting A Tuneable Retrieval Model
A recent study explores an approach named REPLUG (Retrieval-Augmented Black-Box Language Models) where the LLM is considered a black box and the retriever is highly trainable…
Taking a step back…currently there is a rapid evolution of ideas on how LLM-based applications should be architected. And it needs to be noted that there is not a silver bullet or a perfect solution for all use-cases.
Three main concerns raised with regard to LLM based applications are:
Hallucination
Hallucination of LLMs is when the LLM generates a highly plausible and succinct answer, but which is factually incorrect. Hallucination can be solved for by injecting each prompt with a contextual reference at inference time.
The Long-Tail of Conversational Context
As the number of users and the volume of conversations increase, the long-tail of conversational context becomes more important. The user intent is really the conversation the user wants to have, and ensuring the ambit of use is understood. RAG has been identified as the avenue to cater for disparate user intent and establish a contextual reference for each conversation.

Data Governance
Complete data privacy can only be achieved if the LLM is hosted in a private cloud or on premise. Should fine-tuning efforts be moved away from the LLM to the Retriever, a level of LLM independence can be achieved. But data will still be sent to LLMs sitting somewhere, and if the LLM is outside a private cloud or off premise governance targets will be missed.
Hence, a Retriever/RAG approach does not solve for data governance, due to the fact that company and user input information is passed to the LLM.
There is a company who implemented middleware which decides which general queries can go to the LLM in the cloud and queries with PII should be dealt with locally. This option can be cumbersome and hard to manage.
REPLUG — LLM As A Utility
There is an ideal scenario where the LLM is seen as only a utility for general domain QnA, dialog management and Natural Language Generation (NLG) for responses. The REPLUG approach fits into this school of thought, of a black-box approach to LLMs and vesting all fine-tuning in the Retriever.
This approach does raise concerns in terms of varying context lengths of LLMs, languages catered for and performance degradation when moving from one LLM to another.
The REPLUG study states the high cost of fine-tuning, training time and training data required. All of these considerations have been addressed from an OpenAI perspective with their latest developments.
There are also cost considerations like the number of input and output tokens together with the context window size required for data passed in. REPLUG is made up of numerous LLM passes, which adds additional cost and latency.

The image above shows, that when given an input, REPLUG first retrieves a small set of relevant documents for an external corpus using a retriever.
Each document is prepended separately with the input context and combines the output probabilities from numerous passes.
As shown above, given an input context, REPLUG first retrieves a small set of relevant documents from an external corpus using a retriever. Then REPLUG passes the concatenation of each retrieved document with the input context through the LLM in parallel, and at the end ensemble the predicted probabilities.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.



