Combining Ragas (RAG Assessment Tool) with LangSmith
This article considers how Ragas can be combined with LangSmith for more detailed insights into how Ragas goes about testing the RAG implementation.
I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.
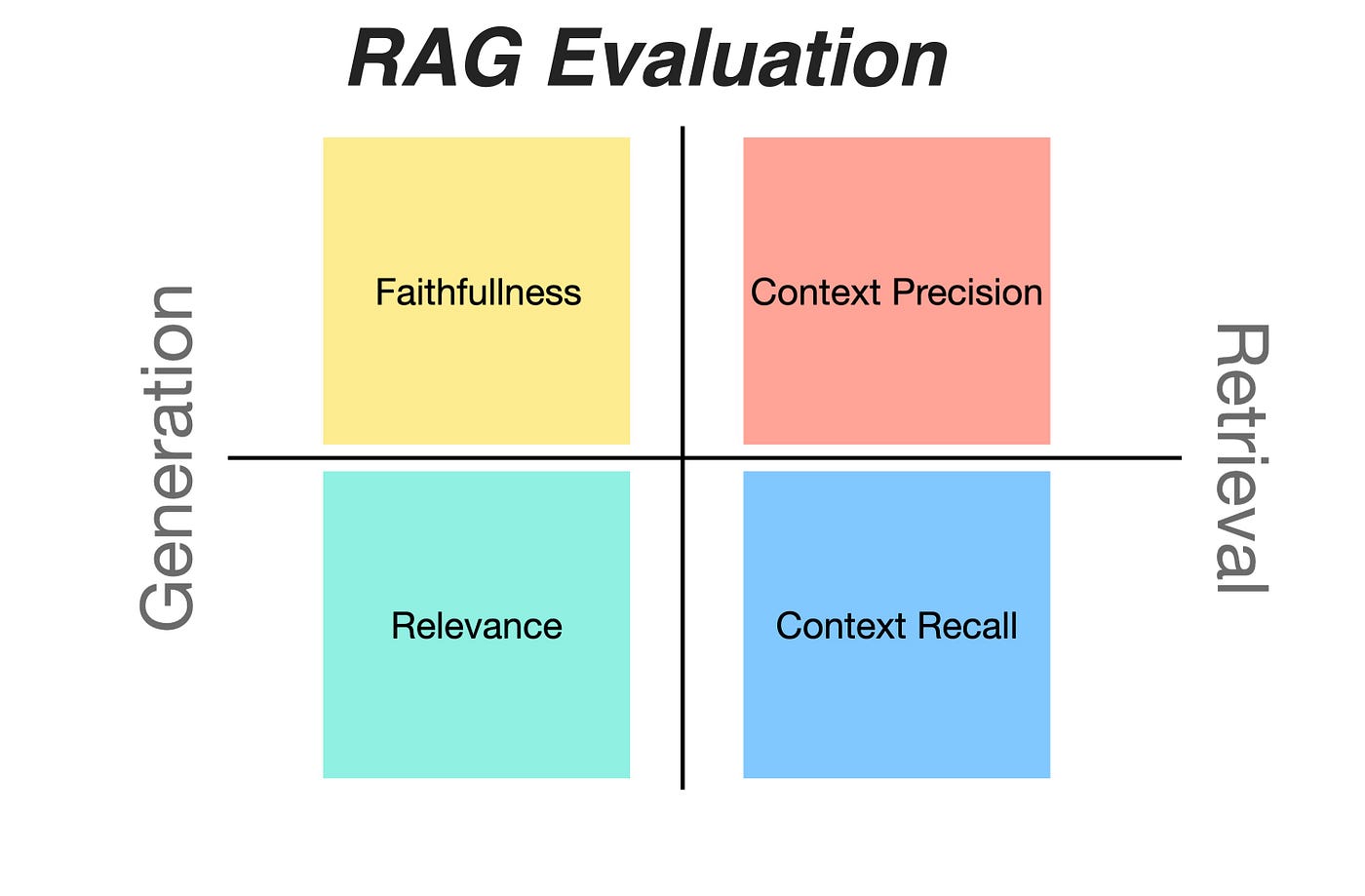
Ragas is a framework which can be used to test and evaluate RAG implementations. As seen in the image below, the RAG evaluation process divides the assessment into to categories, Generation and Retrieval.
Generation is again divided into two metrics, faithfulness and relevance.
Retrieval can be divided into Context Precision and Context Recall.
Read more here.
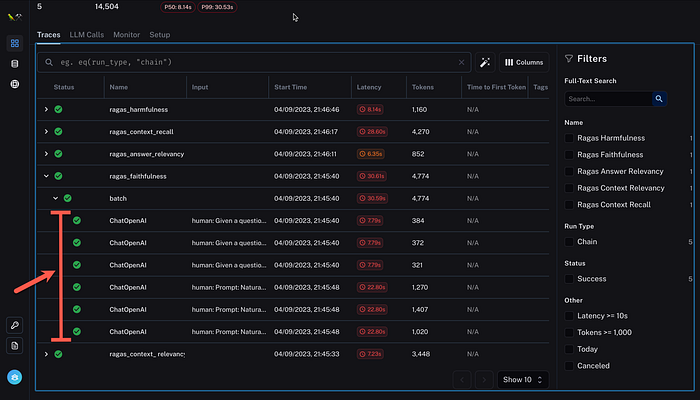
Considering the image below, the view of LangSmith for the Ragas session, a total number of 14,504 tokens were spent, with a P50 latency of 8.14 seconds and a P99 latency of 30.53 seconds.
Currently Ragas makes use of OpenAI, but it would make sense for Ragas to become more LLM agnostic.
The LangSmith integration lifts the veil on cost and latency running Ragas. For this assessment based implementation, latency might not be that crucial, but cost can be a challenge.
Visible below are the five runs, with scores for Harmfulness, Context Recall, Answer Relevancy, Faithfulness and Context Relevance.
For each line the status is shown, name, start time, latency and tokens spent.
Ragas believes that their approach enhances QA evaluation by addressing traditional metric limitation and leveraging LLMs. LangSmith compliments Ragas by being a supporting platform for visualising results.
Using LangSmith for logging, tracing, and monitoring the add-to-dataset feature can be used to set up a continuous evaluation pipeline that keeps adding data points to the test to keep the test dataset up to date with a comprehensive dataset with wider coverage.

As seen below, the harmfulness run is expanded, with each of the runs visible.
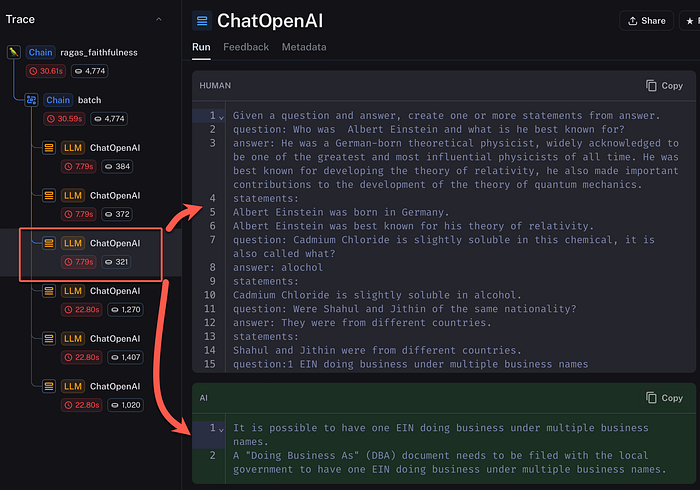
And below is the complete chain for faithfulness, where the chain can be viewed with its six LLM interaction nodes. The input is visible, with the LLM output.
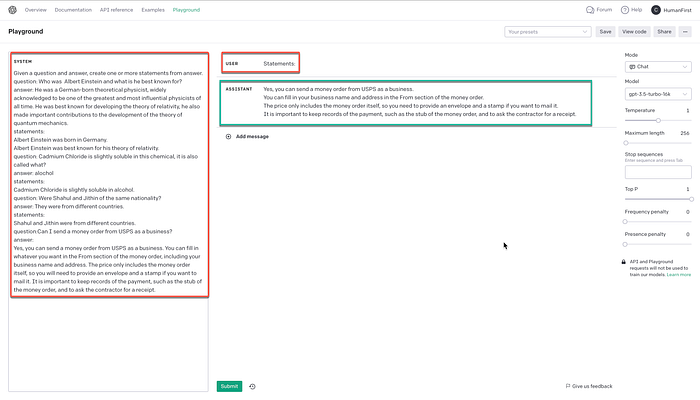
Below the single node in the chain is replicated in the OpenAI playground, just as a reference.
Here is complete working code to run Ragas with OpenAI as the LLM and logging metrics to LangSmith. You will have to add your OpenAI API key, and also have access to LangSmith.
pip install ragas
pip install tiktoken
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxxxxxx"
pip install -U langsmith
from uuid import uuid4
unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Ragas_RAG_Eval"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "xxxxxxxxxxxx"
# data
from datasets import load_dataset
fiqa_eval = load_dataset("explodinggradients/fiqa", "ragas_eval")
fiqa_eval
from ragas.metrics import (
context_relevancy,
answer_relevancy,
faithfulness,
context_recall,
)
from ragas.metrics.critique import harmfulness
from ragas import evaluate
result = evaluate(
fiqa_eval["baseline"].select(range(3)),
metrics=[
context_relevancy,
faithfulness,
answer_relevancy,
context_recall,
harmfulness,
],
)
result
Here is the test results:
{
'ragas_score': 0.3519,
'context_ relevancy': 0.1296,
'faithfulness': 1.0000,
'answer_relevancy': 0.9257,
'context_recall': 0.6370,
'harmfulness': 0.0000
}And to view the data file:
df = result.to_pandas()
df.head()Below, the first few lines, with the columns visible.

Again, a helpful updates to Ragas would be the option to use different LLMs for the QA process, instead of a default to the OpenAI models.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.