Supervised Chain-Of-Thought Reasoning Mitigates LLM Hallucination
Large Language Model (LLM) results significantly improved by implementing natural language reasoning.

What Is Model Hallucination?
When Large Language Models (LLMs) are faced with uncertainty, they exhibit a tendency to invent facts in those moments of resolution. This leads to highly plausible and believable results, but which is unfortunately factually incorrect.
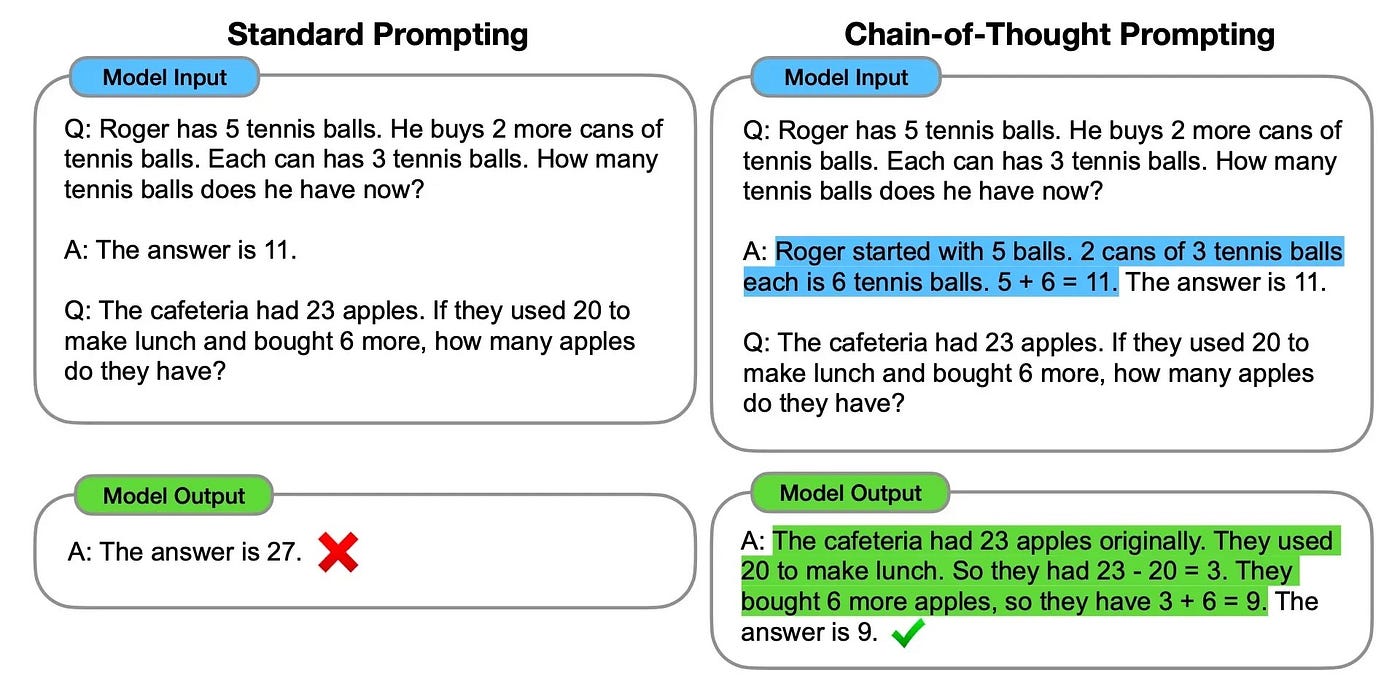
This is especially prevalent in the case of solving for mathematical problems, as seen below in this commonly used example:
Detecting & Mitigating Hallucination
There are three methods to mitigating hallucination:
1️⃣ Contextual References
Even for Natural Language Models (LLMs), a contextual reference is essential for improved accuracy and avoiding false resolutions.
Even a small amount of contextual information imbedded in a prompt can significantly enhance the precision of automated queries.
A little bit of context can make a big difference in the output of any predictive system. For instance, if you type “David” in Google Search, the results will be vastly different than if you type in “David and.”
Read more about contextually enriching a prompt within GPT3 & 4 here.
2️⃣ Generative Prompt Pipeline
Prompt Pipelines extend prompt templates by automatically injecting contextual reference data for each prompt.
Read more about the generative prompt pipeline approach here.
3️⃣ Natural Language Reasoning
For starters, chain-of-thought reasoning improves the performance and accuracy of LLMs in general.
Below is a simple example on how a LLM can be instructed via a few-shot prompt on how to perform chain-of-thought reasoning.
First text-davinci-003 is prompted sans any chain-of-thought example. And in the second instance, a single example is given to text-davinci-003 yielding the desired result.

Hence it stands to reason that OpenAI’s process of human supervision was focussed on process as apposed to outcome. By focussing on process training, the LLM is enhanced with Natural Language Reasoning.
When we as humans are faced with a complicated reasoning task, such as a multi-step math word problem, we segment our thought process.
We typically divide the problem into smaller steps and solve each of those before providing an answer.

Considering the graph below, it is evident that process supervision improves accuracy considerably, as apposed to outcome supervision.
Process supervision also guides the model to align to a chain-of-thought reasoning pattern, which yields interpretable reasoning.

By decomposing reasoning, it is easier for human trainers to identify where the logical error was made by the system.
Training a model to perform this type of decomposition addresses the problem upstream on a model level, instead of performing decomposition on an autonomous agent or prompt level.
Supervision
OpenAI found that there is no simple way to automate process supervision.
Hence they relied on human data-labellers to implement process supervision, specifically by labelling the correctness of each step in model-generated solutions.

To collect process supervision data, OpenAI presented human data-labellers with step- by-step solutions to MATH problems sampled by the large-scale generator.
Their task was to assign each step in the solution a label of positive, negative, or neutral, as shown above. Hence addressing process as opposed to outcome.
⭐️ Please follow me on LinkedIn for updates on LLMs ⭐️

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.