Preventing LLM Hallucination With Contextual Prompt Engineering — An Example From OpenAI
Even for LLMs, context is very important for increased accuracy and addressing hallucination. From the examples below it is clear that a little context can go a long way in improving the accuracy of engineered prompts.

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.
Introduction
A little bit of context can go a long way to change or improve the result of any predictive system. For instance, consider Google Search…and should only the word “david” be entered, the predicted result, sentence completion generated by Google is completely different should “david and” be entered. Hence only adding a single word “and” changes the predicted sentence completely.
Obviously OpenAI’s GPT-3 models excel at general generative question answering. However, regular users of GPT-3 will know that the Language API’s answers are not always well rounded and the response paragraph being often too long, ending mid sentence.
The objective of this article is to illustrate how contextual awareness can be introduced to the discipline of prompt engineering.
Let’s get started…
🌟 Follow me on LinkedIn for Updates on Conversational AI 🙂
Getting Started With OpenAI
In your Colab Notebook you will first have to install OpenAI:
pip install openaiFollowing the installation of openai the code below needs to be run.
You can see how the completion model is defined and also the OpenAI API Key.
You will need to register on the OpenAI website to generate a key.
Initially you will have free tokens to make use of, these will run out quite quickly. However, I have registered my credit card and cost is extremely low, compared to other cloud AI frameworks I have experimented on.
The completion model we will use for starters will be text-davinci-002…for later examples we will switch to text-davinci-003, which is the latest and most advanced text generation model available. Some of the lines of code are redundant for this example, but will be used in a follow-up article.
import pandas as pd
import openai
import numpy as np
import pickle
COMPLETIONS_MODEL = "text-davinci-003"
openai.api_key = ("sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx")In the Python example below a simple question is asked relating to the Olympics.
prompt = "Who won the 2020 Summer Olympics men's high jump?"
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")The answer is well formed, but unfortunately it is the wrong answer…
The 2020 Summer Olympics men's high jump was won by Mariusz Przybylski of Poland.Mariusz Przybylski is a Polish football player. So it is clear that GPT-3 got the answer wrong. The remedial action to take is to provide GPT-3 with more context in the engineered prompt.
It needs to be stated also that the GPT-3 model is hallucinating an answer rather than stating “I do not know the answer”.
Having a model stating, “I don’t know” is far better than having a model giving a wrong or hallucinated answer.
Hence the prompt will be engineered to change from:
Who won the 2020 Summer Olympics men's high jump?to:
prompt = """Answer the question as truthfully as possible, and if you're unsure of the answer, say "Sorry, I don't know".
Q: Who won the 2020 Summer Olympics men's high jump?
A:"""
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")Yields the truthful response:
Sorry, I don't know.However, we would want to improve the interaction with the LLM, by having the LLM provide an accurate and correct answer to a question.
This can be achieved by helping the model through providing additional context within the prompt.
🌟 Follow me on LinkedIn for Updates on Conversational AI 🙂
I find this particularly interesting for a digital assistant (chatbot) scenario where recent chat history can be summarised (using a LLM) and used as context with the user’s input for highly contextual responses.
As seen below, the prompt structure is updated to the following basic sequence:
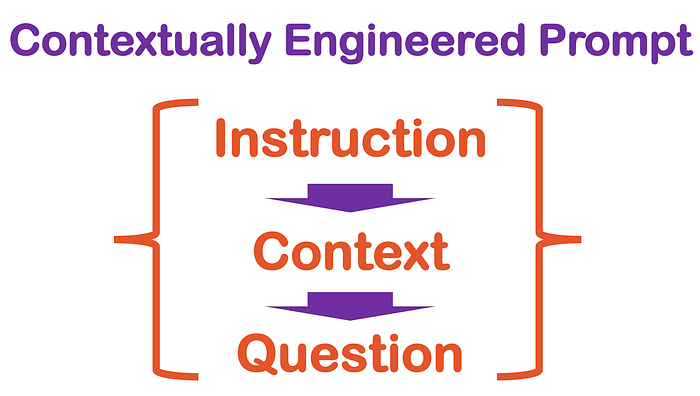
..and the Python version for this new engineered prompt:
prompt = """Answer the question as truthfully as possible using the provided text, and if the answer is not contained within the text below, say "I don't know"
Context:
The men's high jump event at the 2020 Summer Olympics took place between 30 July and 1 August 2021 at the Olympic Stadium.
33 athletes from 24 nations competed; the total possible number depended on how many nations would use universality places
to enter athletes in addition to the 32 qualifying through mark or ranking (no universality places were used in 2021).
Italian athlete Gianmarco Tamberi along with Qatari athlete Mutaz Essa Barshim emerged as joint winners of the event following
a tie between both of them as they cleared 2.37m. Both Tamberi and Barshim agreed to share the gold medal in a rare instance
where the athletes of different nations had agreed to share the same medal in the history of Olympics.
Barshim in particular was heard to ask a competition official "Can we have two golds?" in response to being offered a
'jump off'. Maksim Nedasekau of Belarus took bronze. The medals were the first ever in the men's high jump for Italy and
Belarus, the first gold in the men's high jump for Italy and Qatar, and the third consecutive medal in the men's high jump
for Qatar (all by Barshim). Barshim became only the second man to earn three medals in high jump, joining Patrik Sjöberg
of Sweden (1984 to 1992).
Q: Who won the 2020 Summer Olympics men's high jump?
A:"""
openai.Completion.create(
prompt=prompt,
temperature=0,
max_tokens=300,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
model=COMPLETIONS_MODEL
)["choices"][0]["text"].strip(" \n")Gianmarco Tamberi and Mutaz Essa Barshim won the 2020 Summer Olympics men's high jump.According to OpenAI: Adding extra information into the prompt only works when the dataset of extra content that the model may need to know is small enough to fit in a single prompt. What do we do when we need the model to choose relevant contextual information from within a large body of information?
In a follow-up article I will look in detail at adding a larger body of information. Hence extending the notion of a Contextually Engineered Prompt being extended into a larger body of information. But where the body of information serving as context is too large to host in the “prompt” and needs to be referenced in some other way.
🌟 Follow me on LinkedIn for Updates on Conversational AI 🙂
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.