
Seven RAG Engineering Failure Points
Retrieval-Augmented Generation (RAG) systems remains a compelling solution to the challenge of relevant up-to-date reference data at inference time. Integrating retrieval mechanisms with the generative capabilities of LLMs & RAG systems can synthesise accurate, up-to-date and contextually relevant information.
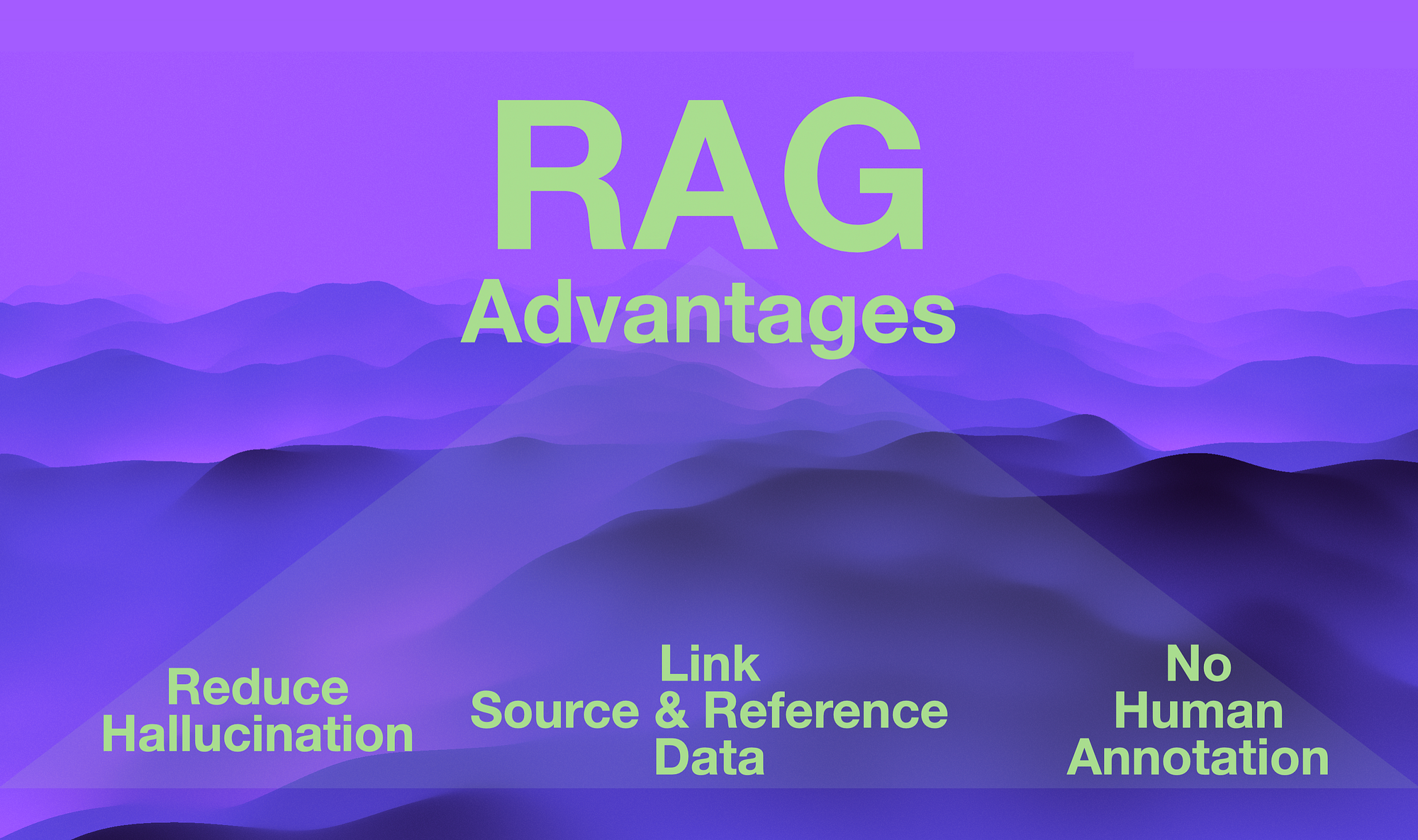
RAG Advantages
A Retrieval-Augmented Generation (RAG) system combines information retrieval capabilities with the generative prowess of LLMs.
Considering the image below, there are three distinct advantages to RAG which makes it such a compelling option.
The first is that RAG reduces LLM hallucination. Hallucination is when an LLM generates highly succinct, coherent, plausible and believable answers.
However, these responses are factually incorrect; this approximation of LLMs to the truth can be remedied by leveraging the immense in-context learning abilities of LLMs. This is achieved by injecting prompts at inference with highly contextual reference data.
The second advantage of RAG is that source and reference data are linked to interactions and conversations. Hence RAG is an easy way to introduce organisation, enterprise or industry specific data, together with definitions, terms and more.
Thirdly, the process of chunking and indexing the reference data is very much an automated process hence no human annotation of data is required.
RAG Challenges
The study states that validation of a RAG system is only feasible during operation and the robustness of a RAG system evolves rather than designed at the start.
This assumption is the traditional belief in terms of user intents; and that user intents needs to be discovered as the application is in use.
I disagree strongly with this assumption, as the long tail of intent distribution can be successfully detected and addressed by leveraging the first two steps of NLU Design.
Read more about NLU Design and solving for the long tail of intent distribution here:
RAG Architecture
The study contains a detailed RAG architecture. with the Index Process shown, and the Query Process. The Index Process takes place at design-time, also referred to as development time.
The query time is also known as inference time, or run-time, as shown on the second row.
What I particularly like is the fact that mandatory elements of the RAG architecture is underlined, while optional elements are not. With this in mind, the process of chunking and creating a vector database entry (indexing/embedding) are mandatory. Together with the retriever and Reader.
Additional features adding a Reranker or a Consolidator or Rewriter add complexity, together with scalability and flexibility.
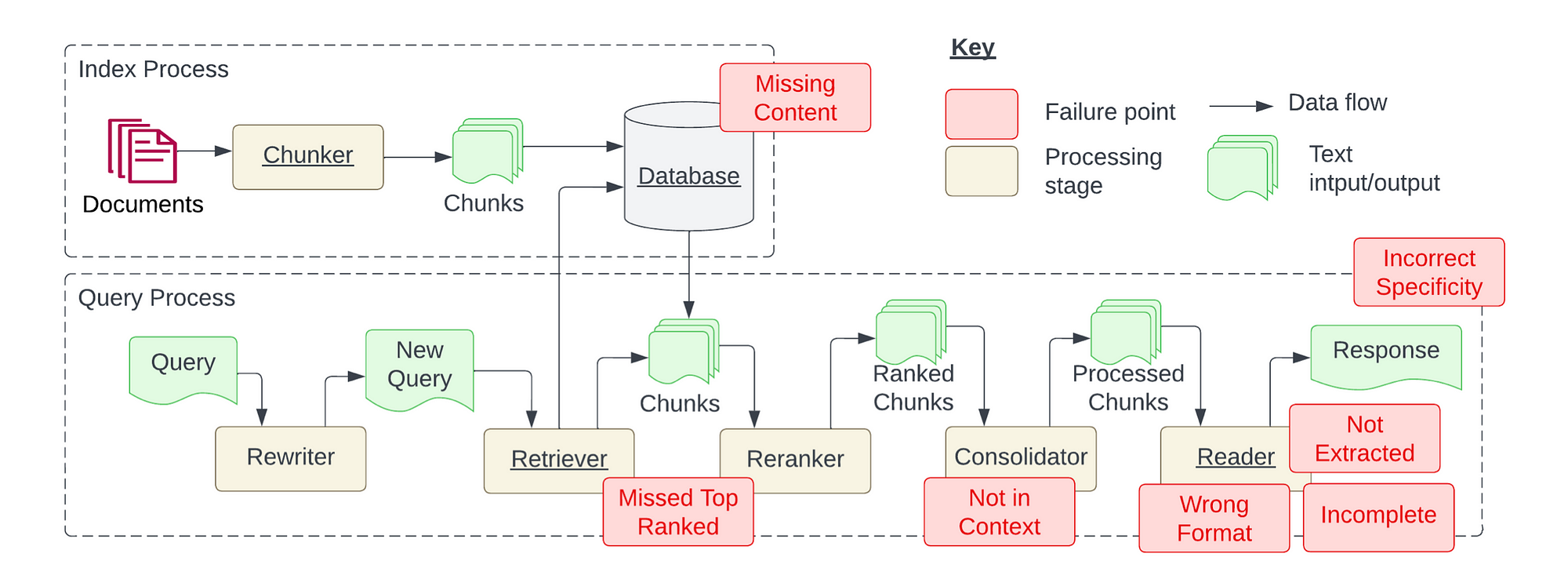
The Consolidator is responsible for processing the chunks, which is important to overcome limitations of large language models in terms of token and rate limits.
Readers are responsible for filtering the noise from the prompt, complying to formatting templates and producing the output to return for the query.
Seven Potential RAG Failure Points
1️⃣ Missing Content
Failure can occur while posing a question that cannot be addressed using the existing documents. In the favourable scenario, the RAG system will simply reply with a message such as “Sorry, I don’t know.” However, in cases where questions are relevant to the content but lack specific answers, the system might be misled into providing a response.
2️⃣ Missed Top Ranked
The document contains the answer to the question but didn’t rank high enough to be presented to the user. In theory, all documents are ranked and considered for further processing. However, in practice, only the top K documents are returned, where the value of K is chosen based on performance metrics.
3️⃣ Not In Context
Documents containing the answer were successfully retrieved from the database but were not included in the context used to generate a response.
This situation arises when multiple documents are retrieved from the database, and a consolidation process is employed to extract the answer.
4️⃣ Wrong Format
The question required extracting information in a specific format, such as a table or list, yet the large language model disregarded this instruction.
5️⃣ Incorrect Specificity
The response includes an answer, but it lacks the required specificity or is overly specific, failing to meet the user’s needs.
This situation arises when the designers of the Retrieval-Augmented Generation (RAG) system have a predetermined outcome for a given question, such as providing educational content for students.
In such cases, the response should include not only the answer but also specific educational materials. Incorrect specificity can also occur when users are uncertain about how to phrase a question and provide overly general queries.
6️⃣ Not Extracted
In this scenario, the answer is within the context provided, but the large language model fails to accurately extract it. This usually happens when there is excessive noise or conflicting information within the context.
7️⃣ Incomplete
Incomplete answers are not necessarily incorrect but lack some information, even though it was present in the context and could have been extracted.
For instance, consider a question like “What are the key points covered in documents A, B, and C?” A more effective approach would be to ask these questions separately for each document to ensure comprehensive coverage.
I need to mention that this scenario is solved for by a approach from LlamaIndex called Agentic RAG. Agentic RAG allows for a lower level agent tool per document, with a higher order agent orchestrating the agent tools.
Chunking
Chunking is a natural language processing technique used to group words or tokens together based on specific criteria, such as syntactic structure or meaning.
It involves dividing a sentence into segments, or “chunks,” that consist of one or more words and typically include a noun and its modifiers.
Chunking helps in identifying meaningful units of text, which can then be processed or analyzed further. This technique is commonly used in tasks like information extraction, named entity recognition, and shallow parsing.
Chunking documents may seem straightforward, but its quality significantly impacts the retrieval process, particularly concerning the embeddings of the chunks and their matching to user queries.
Two main approaches to chunking exist:
- heuristic-based, which relies on punctuation or paragraph breaks, and
- semantic chunking, which uses text semantics to determine chunk boundaries.
Further research should delve into the tradeoffs between these methods and their impact on crucial downstream processes like embedding and similarity matching. Establishing a systematic evaluation framework to compare chunking techniques based on metrics such as query relevance and retrieval accuracy would greatly advance the field.
Embeddings
Embeddings represent a dynamic research area, encompassing the generation of embeddings for multimedia and multimodal chunks, such as tables, figures, and formulas.
Chunk embeddings are usually generated during system development or when indexing a new document. The preprocessing of queries plays a vital role in the performance of a Retrieval-Augmented Generation (RAG) system, especially in managing negative or ambiguous queries.
Further exploration is necessary on architectural patterns and approaches to tackle inherent limitations in embeddings, as the quality of a match is often domain-specific.
In Closing
For highly scaleable implementations the most appropriate approach seems to be something called Agentic RAG.
The topic of Agentic RAG explores how agents can be incorporated into existing RAG pipelines for enhanced, conversational search and retrieval.
I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.

