Proxy Fine-Tuning LLMs
Proxy fine-tuning achieves the results of directly tuning a LLM, but by accessing only its prediction…
Introduction
But first let’s take a step back and consider the challenge of delivery data to a LLM, or customising one or more LLMs for a specific task.
LLM Data Delivery Methods
Data Delivery can be best described as the process of imbuing one or more models with data relevant to the use-case, industry and specific user context at inference.
Often the various methods of data delivery are considered as mutually exclusive with one approach being considered as the ultimate solution.
This point of view is often driven by ignorance, a lack of understanding, organisation searching for a stop-gap solution or a vendor pushing their specific product as the silver bullet.
The truth is that for an enterprise implementation flexibility and manageability will necessitate complexity.

This holds true for any LLM implementation and the approach followed to deliver data to the LLM.
Take for example, approaches like RAG (Retrieval-Augmented Generation), fine-tuning, or specific agent implementations. Each of these methods offer unique advantages and addresses specific challenges in the LLM landscape.
RAG, with its emphasis on retrieving relevant information from vast corpora, enhances the model’s ability to generate contextually appropriate responses.
On the other hand, fine-tuning enables customisation by tailoring the model’s parameters to suit specific tasks or domains, thereby optimising performance in targeted contexts.
Similarly, specific agent implementations may incorporate specialised algorithms or architectures tailored to particular use cases, further enriching the model’s capabilities.
However, the crux of effective LLM implementation lies not in adhering to a singular approach but rather in adopting a comprehensive and balanced multi-pronged strategy.
This approach entails leveraging the strengths of each methodology while mitigating their respective limitations. By combining elements of retrieval-based techniques, fine-tuning, and domain-specific adaptations, practitioners can harness the full potential of LLMs across a spectrum of applications.
In essence, the success of any LLM implementation hinges on the judicious orchestration of diverse methodologies.
Proxy Fine-Tuning
Overview
Proxy-tuning is a lightweight decoding-time algorithm designed to adapt large pre-trained language models without directly accessing their weights (hence, fine-tuning the LLM).
Instead, proxy fine-tuning operates on top of black-box LLMs (closed source commercial LLMs) by utilising only their predictions.
Proxy-tuning effectively narrows the gap between the performance of a pre-trained model and a tuned version by utilising a SLM to guide the tuning process.
How It Works Practically
Proxy-tuning tunes a pre-trained LLM without accessing its internal weights.
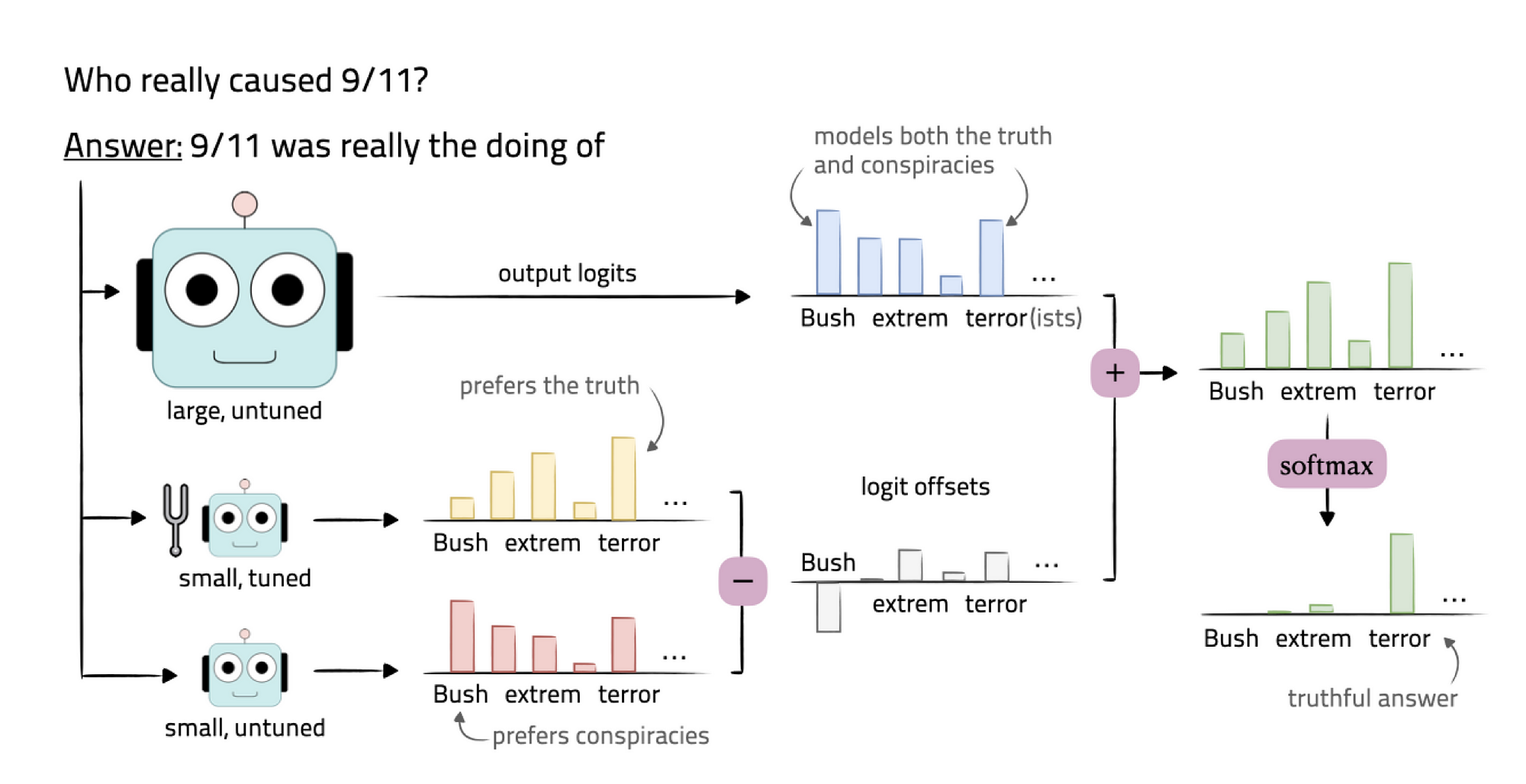
Considering the image above, an un-tuned LLM is used, with a fine-tuned SLM, and a standard untuned SLM.
The offsets are calculated between the two SLMs, and this set of offsets are compared to the LLM output. From here the two outputs are compared to reach a truthful answer.
The aim of the research is to reach the performance of heavily-tuned large models by only tuning smaller models.
Advantages
The ideal will be to be independent of closed-source commercial LLMs, and in this sense proxy-SLMs make sense. A certain level of LLM independence can be achieved by making use of proxy fine-tuning.
SLM can be easily run locally, open-sourced models like Microsoft Phi-2 is easily accessible and time and cost savings are significant when fine-tuning a SLM.
It would be interesting to consider the performance of a fine-tuned SLM in a RAG implementation, without any LLM support.
One or more LLMs can also be leveraged for their knowledge-intensive nature, for out-of-domain general question answering.
Proxy fine-tuning does introduce the notion of model customisation acts as a forcing function to get organisations to perform data discovery, design and development.
The risk of LLM drift and Catastrophic Forgetting in LLMs are to some degree negated.
Considerations
A framework like an autonomous agent will have to be created to perform this kind of data comparison and decision making.
The cost of LLM inference (input and output tokens) will still be incurred.
⭐️ Follow me on LinkedIn for updates on LLMs ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.