Prompt Chaining & Large Language Models
What are the underlying requirements driving the need for prompt chaining? What defines prompt chaining and what are the essentials of a robust prompt chaining development tool?

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.
To understand the importance of Prompt Chaining, three aspects related to Large Language Models (LLMs) need to be considered.
These being:
(1) training, (2) inference and (3) chain-of-thought prompting.
These three elements combined in any LLM based conversational interface improves the user experience considerably…
Training
For prompt-chaining, the LLM prompt context needs to be established for each dialog turn or prompt chain. Using the context, the prompt needs to be well formed for each chain.
Training improves the accuracy of LLM responses considerably. Training as defined in its simplest form, is the number of examples supplied to the LLM for each and varying instance it needs to make a prediction and create an output.
This training data is most often embedded in requests to LLMs via prompt engineering.
The challenge is to be able to have an effective and efficient supervised approach to the creation of prompts to ensure at every dialog turn of the conversation, accurate training data is included in the prompt. With accurate the implication is that the training data is well-formed, highly contextual and well structured.
Humans can perform new language tasks with only a few simple instructions & examples. Something traditional NLP is incapable of. This changed with LLMs.
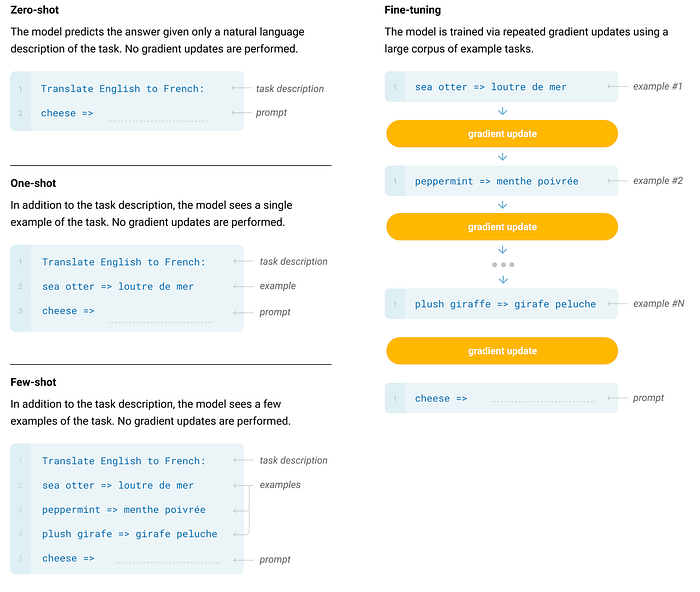
Considering the graph below, the variance in accuracy is well illustrated between zero, one and few-shot training. Few-shot training offers big potential in terms of coaching and guiding the LLM…more about that later.
However, I hasten to say, constituting accurate few-shot training examples at scale and on the fly is the challenge to solve for.

Zero-Shot
Zero-shot learning is where an instruction is given to the LLM with no demonstrations on a particular instruction given. Hence only a blind instruction in natural language is given to the model.
One-Shot
One-Shot learning is in essence the same as zero-shot, except that only one demonstration example is included in the instruction given to the LLM.
Few-Shot
Few-Shot is where the model is given a few demonstrations of the task at inference time.
One of the advantages cited in a recent paper, is: a few-shot approach is a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset.
I need to stress that the challenge here is to retrieve accurate and relevant few-shot training data in real-time and at scale for each chain in the application.
A small amount of task specific data is still required for each few-shot training instance.
Keep in mind, that with a few-shot approach, not only should context be established in the prompt, but the desired output should also be imbedded via prompt engineering.
The main disadvantage of few-shot training is that the results have been, so far, much worse than state-of-the-art fine-tuned models.
Fine-Tuning
Fine-Tuning of LLMs has not received the attention it deserves.
Fine-Tuning has been the most common approach in recent years, and involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task. (Source)
The primary advantage of fine-tuning is strong performance on most benchmarks. The biggest impediment to fine-tuning is seen as the need for a new large dataset for every task.
This impasse can be negated by following a supervised bottom-up approach to detecting signal in data, curating, clustering and labelling data. Hence converting unstructured data into highly structured LLM training data.
Natural Language Inference
Natural Language Inference (NLI) is the ability to understand the relationship between two sentences.
An important part of chaining together multiple dialog turns is establishing inference.
Wider dialog context is established by stringing together a number of dialog turns, and hence inference can also be seen as in-conversation context.
This context needs to be maintained in a prompt chaining application, and passed from chain to chain; or stored for later retrieval.
Described differently: Natural Language Inference (NLI), also known as Recognising Textual Entailment (RTE), is the task of determining the inference relation between two pieces of text.
Stanford research proposed an approach to natural language inference based on a model of natural logic. The most efficient way to establish inference is via chain-of-thought prompting.
Chain-Of-Thought Prompting (COTP)
Prompt chaining in essence is a chain of thought application. In principle chain-of-thought prompting allows for the decomposition of multi-step requests into intermediate steps.
Inference can be established via chain-of-thought prompting. Chain-of-thought prompting enables large language models to address complex tasks like common sense reasoning and arithmetic.
Below is a very good illustration of standard prompting on the left, and chain-of-thought prompting on the right.
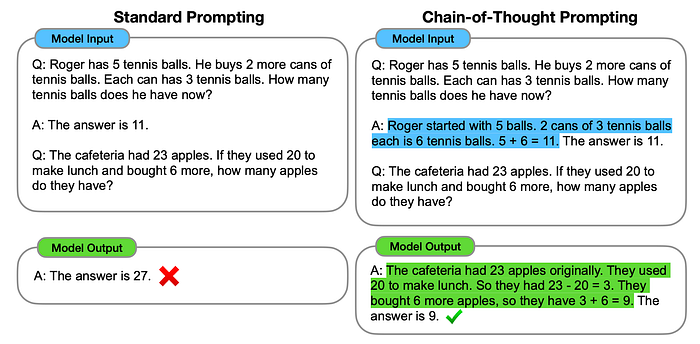
What is particularly helpful of COTP is that by decomposing the LLM input and LLM output, it creates a window of insight and interpretation.
This Window of decomposition allows for manageable granularity for both input and output, and tweaking the system is made easier.
COTP is ideal for contextual reasoning like word problems, common-sense reasoning, math word problems, common-sense reasoning, and very much applicable to any task that we as humans can solve via language.
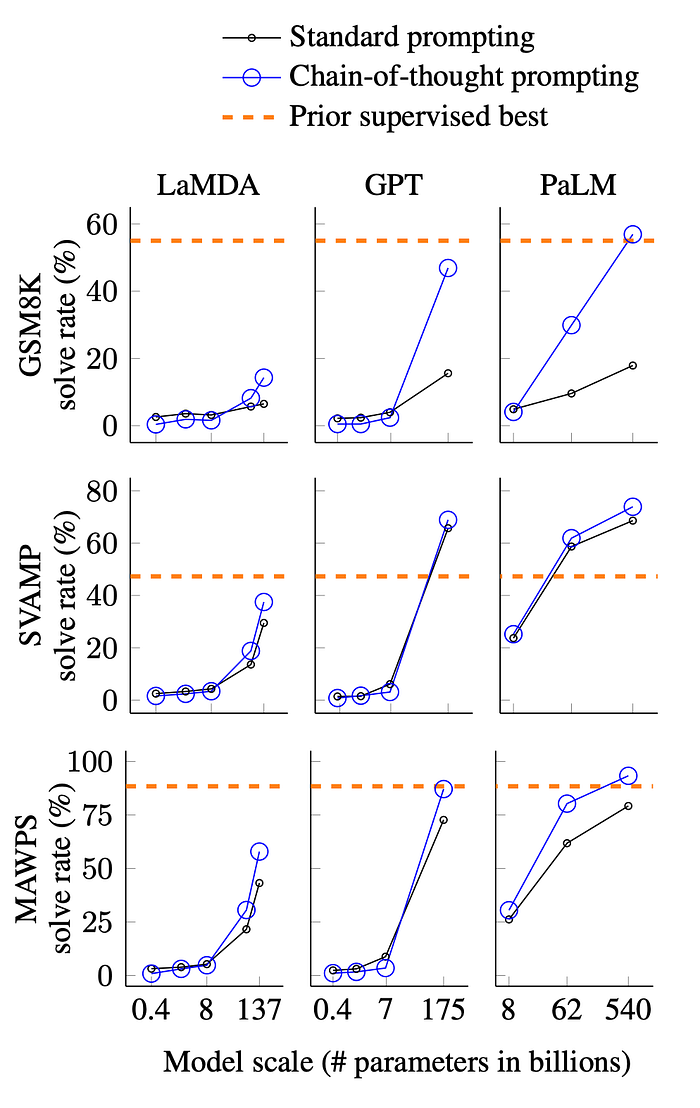
The image below shows a comparison of percentage solve rate based on standard prompting and chain-of-thought prompting.
In Conclusion
As the demand increase for LLMs to be implemented in production settings, a first port of call will be prompt chaining.
Prompt chaining can have conversational input and output. Or in the case where it is used for RPA-like tasks, only the input will be conversational.
But in both instances complex and multi-step tasks need to be decomposed and implemented sequential fashion, all the while making provision for exceptions, different user behaviours, etc.
Creating, managing and measuring these prompt chains calls for a flexible no-code, studio-like workbench.

⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.