LLMs, The co:here Playground & Going From Prototype To Production
Notebooks, API’s, Collaboration & Adding Complexity

Introduction
A short recap for starters…co:here is a natural language platform. It can be used for both natural language understanding and generation.
And, co:here is an easy avenue to access large language models, for use cases like:
- Classification,
- Semantic Search,
- Paraphrasing,
- Summarisation, and
- Content Generation.
The speed and ease with which you can enter your own data, experiment fast and export API details from the playground for use in more production ready environments is very attractive.

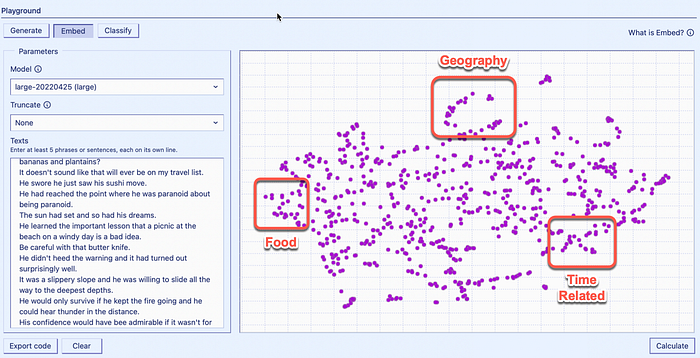
Above is an example from the co:here playground where embeddings are used. A list of very random 724 sentences were used, all of a very random nature. It takes co:here a few seconds to create an embedding from the data and then plot out all the utterances into a 2D chart to visualise the semantic similarities in the sentences.
Impediments to NLP Access
Generally Impediments to NLP access are:
- Requirements for large datasets for training
- Long training times
- Specialised hardware
- Specific knowledge
All of these are negated with the help of a playground. Leveraging pre-trained large language models, small amounts of own data can be used to rapidly achieve results.

As seen above, the playground can act as an incubation area for projects to evolve into API’s, notebooks and general collaboration, eventually culminating in a product or application.

Above, all co:here playground activity can be exported in various formats.
Something to keep in mind with the co:here playground is that you will soon outgrow the playground in terms of:
- Size of datasets
- Customisation of results
- Pre and Post Processing
- Collaboration
- and Obviously Integration
Hence the next step is notebooks and or API’s for collaboration and adding complexity, and finally getting the functionality production ready.
But what if the play can continue, and the playground can expand into a full-fledged no-code workbench…absorbing all the iterations from play to production in one cohesive no-code interface?
“The master in the art of living makes little distinction between his work and his play, his labor and his leisure, his mind and his body, his information and his recreation, his love and his religion. He hardly knows which is which. He simply pursues his vision of excellence at whatever he does, leaving others to decide whether he is working or playing. To him he’s always doing both. ”
― James A. Michener
Visualising & Exploring Data
Back to the co:here playground…As seen below, highly unstructured user utterances with spelling and grammar errors are graphically represented and clustered. Outliers for each cluster can be inspected.
For a deep-dive on co:here clustering, take a look at this article…
Creating structure from highly unstructured data, also data which has not be cleaned or pre-processed in any way is always insightful. In many cases pre-exising parameters need to exist for the data to be compared to and segmented accordingly. This is not the case here…
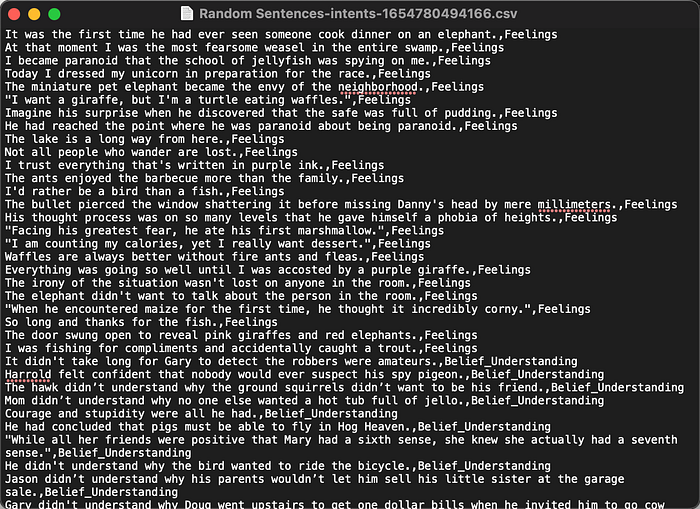
Above a list of intentionally random sentences, some are not complete sentences and with many spelling and grammar errors. This is often the nature of customer entered data.
Yet co:here has the ability to create a visual embedding of the utterances. Immediately with a quick glance you can see what customers are speaking about. Some clusters are closely related, for instance on the top Geography & at the bottom time related utterances are clustered together.
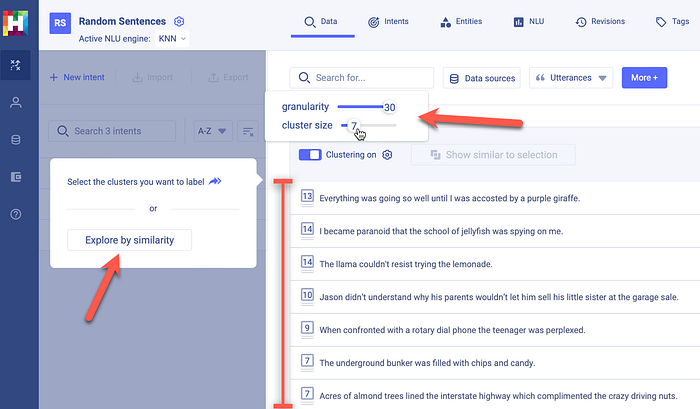
I imported the same random sentences into the HumanFirst workbench. In this case, not a few dozen as in the case of the co:here playground, but 724 utterances. And you will see how the granularity can be set with cluster size. The different clusters can be viewed and visually inspected and a range of scores and confidences can be accessed on the right.
Again, the raw data is grouped into intents and can quickly be re-arranged without any pre-defined list of guiding intents or suggestions. No preprocessing was performed on the data. There are at least three other frameworks that offer intent detection and clustering of utterances. These are Amazon Lex, Oracle Digital Assistant & Nuance Mix.
Playground To Product
But what if you could scale, from a playground approach to a final product?
What if you could stay in a no-code playground environment and import vast amounts of data and remain in the no-code environment to explore, annotate and create NLU models?
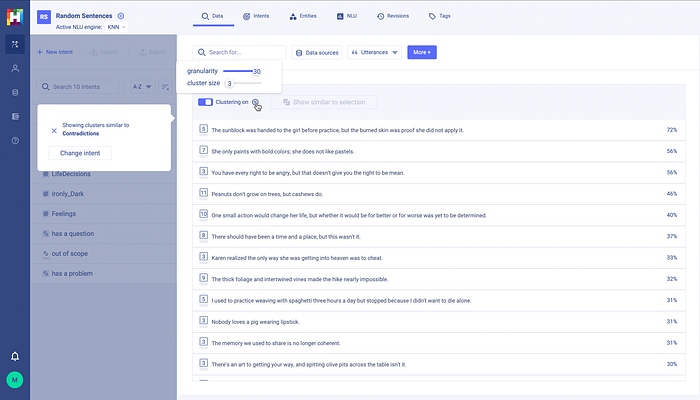
With HumanFirst, the clusters can be transformed and named as intents. A NLU model trained on this data and searched with matching intents and confidences surfaced.
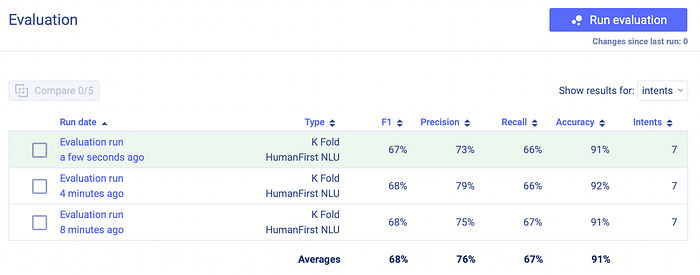
Is this a playground, yes and no…it starts off as a playground…but scales into a fully fledged NLU engine, with options to evaluate your model according to F1, Precision, Recall, Accuracy , etc.
And lastly, below the list of plausible intents extracted from sentences.
Evaluation is important to ensure there is no deprecation in accuracy as data is added and or edited.
Back to the idea of a fully fledged NLU, the NLU engine can be queried and the results and confidences generated. This is analogous to the Nuance Mix NLU try testing interface.

The API request can be copied with the click of a button to create an NLU API.
Below is the copied result from HumanFirst in the Postman API tool…
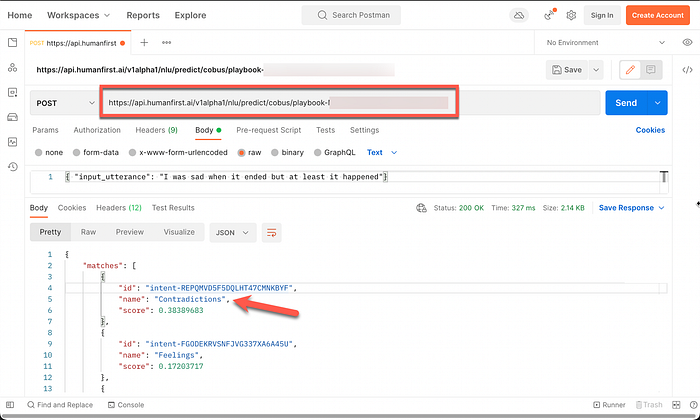
And below is the result of the API Call…
{"matches": [
{"id": "intent-REPQMVD5F5DQLHT47CMNKBYF",
"name": "Contradictions",
"score": 0.38389683},{"id": "intent-FGODEKRVSNFJVG337XA6A45U",
"name": "Feelings",
"score": 0.17203717
},
{
"id": "intent-QVDWEWOQWFB4BFJOWQQIPXO6",
"name": "Too Random",
"score": 0.16002339
},
{
"id": "intent-MNPN4KIFDVBMFB6KSSVH4BJV",
"name": "Belief_Understanding",
"score": 0.14170465
},
{
"id": "intent-SR3WDEMJFZAM7JZHNMUCBD63",
"name": "Ironly_Dark",
"score": 0.056618396
},
{
"id": "intent-XUWANTMV2RERXNJYCSUIW6DN",
"name": "LifeDecisions",
"score": 0.047174823
},
{
"id": "intent-SFZGDHLEJVDSXMYFNIFYNF5V",
"name": "Happiness",
"score": 0.038544785
..................
Even though the HumanFirst workbench is such an augmented no-code interface, for production data, integration, pipelines and API’s will have to be created.
Provision is made within HumanFirst for this, which will be a natural outflowing from the workbench work, but only on a much later stage.

The HumanFirst Studio features can be leveraged by controlling the scheduling, training and deployment of NLU models and artefacts, and exposing APIs.
The next step will be the annotation of Entities…
Annotation Of Entities
Within the HumanFirst workbench training data can be annotated and entities can be marked within intents. Machine Learning seem to be employed with the Find similar variations functionality, which sort training examples to surface related variations on the existing annotations.
Annotation of intents with entities aided by AI.
This reminds somehow of the forward annotation which IBM Watson Discovery performs.
Conclusion
Dark data and unstructured data are a wealth of information, especially on customer behaviour, customer speak and customer desire.
These can all be visualised, clustered, discovered and designed for.
Workspace history can be reviewed, restored, differences listed, locked and unlocked.
