Fine-Tuning Large Language Models
In this article I consider the fine-tuning of large language models and how it compares to zero and few shot approaches.

The large language model (LLM) landscape is ever expanding with a number of new additions of late, with the most notable introduction being ChatGPT.
There are three approaches to reaching desired outcomes with LLMs:
1️⃣ Zero Shot Learning
2️⃣ Few Shot Learning
3️⃣ Custom/Fine-Tuned Models
Zero Shot Learning is a scenario where a LLM can recognise a wide range of user requests without explicitly being trained on the user input. It can be argued that the new discipline of Prompt Engineering forms part of zero shot learning.
Few Shot Learning is an approach where the LLM makes a prediction based on a very limited number of training samples. These samples can be stored in clusters and retrieved for real-time training during the conversation. You can find more detail on this approach here.
Custom / Fine-Tuned Models is a longer term approach where a fine-tuned model is based on one of the standard models offered by the LLM.
Below is an example from the OpenAI playground where the custom fine-tuned models are listed together with the standard available OpenAI Language API models.
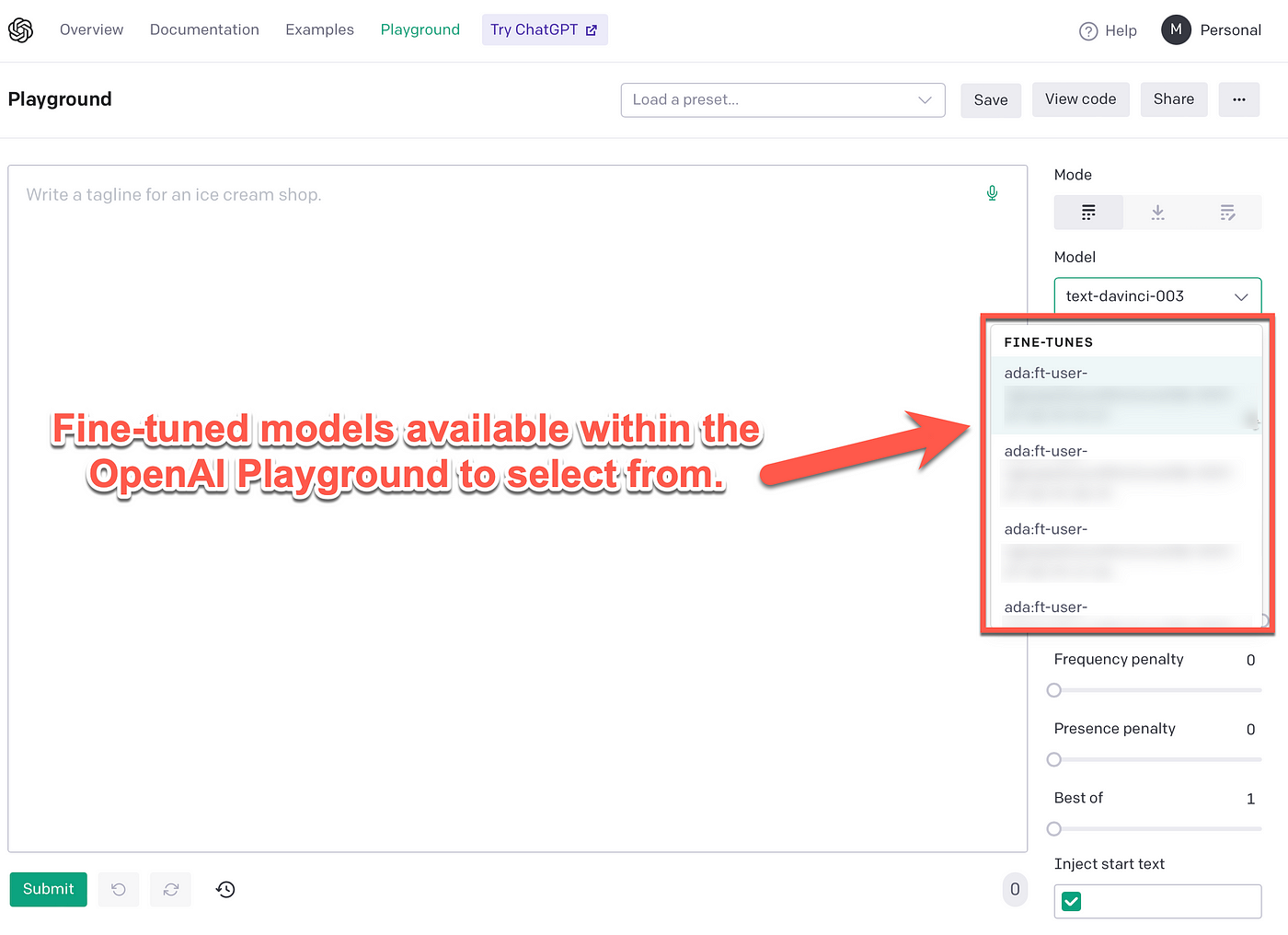
When compiling a query in the OpenAI playground, the model drop-down is visible on the top right. There are a few standard models to choose from, each of these are optimised for different tasks.
The steps to create a custom model are:
- Select an existing model which is best suited for the envisioned task.
- Curate and prepare your custom training data.
- Format the data into the relevant format as mandated by the LLM providers.
- Upload and start the training process.
- All of the training takes place in the cloud.
- Depending on the size of the base model you select, and the amount of training data, the training time can differ significantly.

Once training is completed, the LLM platform will send you a notification and the model reference will be available for you to use in your projects.
⭐️ Please follow me on LinkedIn for updates on Conversational AI ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.