Chain Of Natural Language Inference (CoNLI)
Hallucination is categorised into subcategories of Context-Free Hallucination, Ungrounded Hallucination & Self-Conflicting Hallucination.
Introduction
It is important for LLM text-to-text generation to respond with factually consistent data in relation to the source text.
Thus establishing alignment between truth and user expectation & instruction.
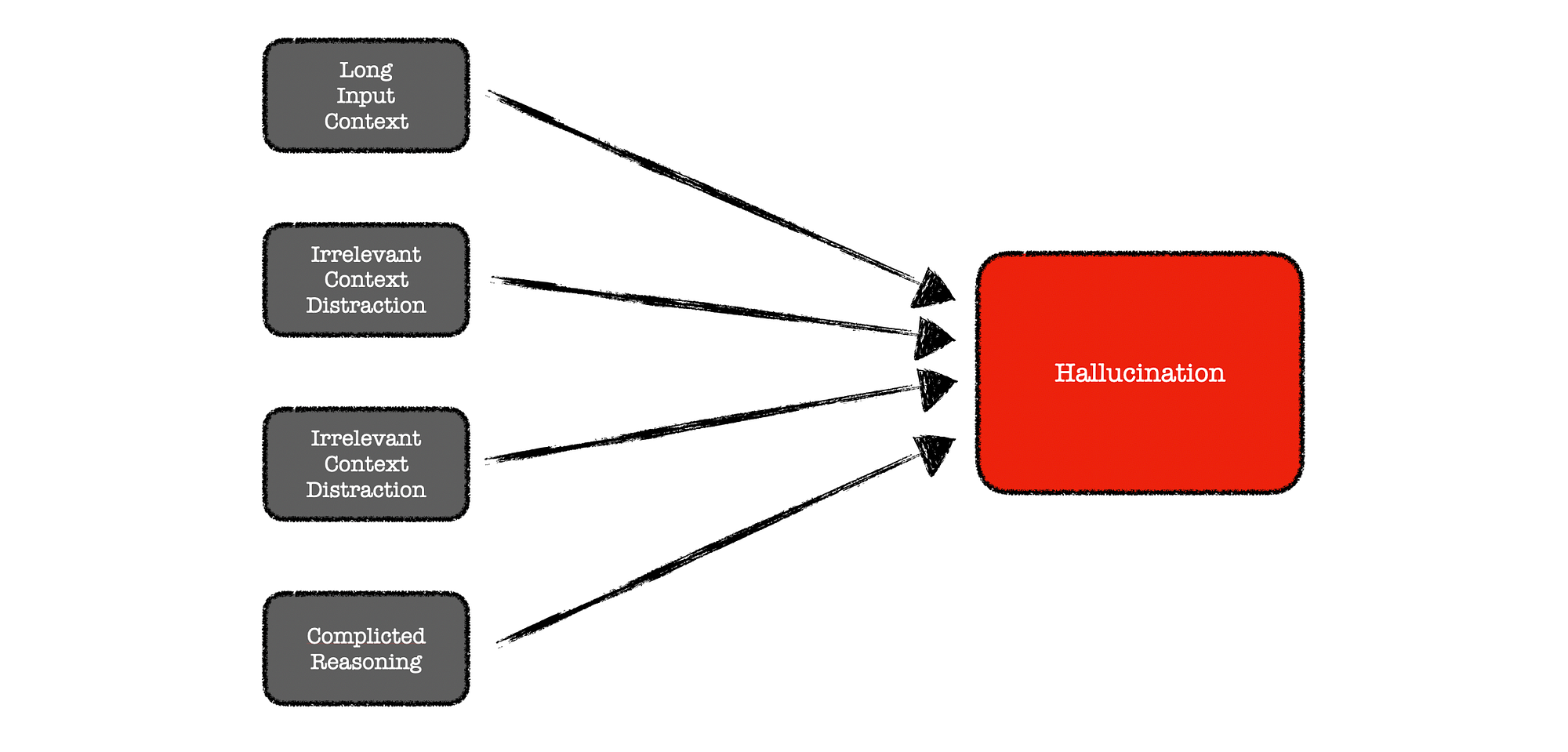
The study identifies a number of factors which causes hallucination. These include:
- Long input context,
- Irrelevant context distraction, and
- Complicated reasoning.
This phenomenon poses a significant challenge to the reliability of LLMs in real-world applications.
CoNLI
CoNLI is used for both hallucination detection and hallucination reduction via post-editing.
ConNLI detects hallucination and enhances text quality through rewriting the response.
One of the objectives of CoNLI was to only rely on LLMs without any fine-tuning or domain-specific prompt engineering.
CoNLI is described as a simple plug-and-play framework which can serve as an effective choice for hallucination detection and reduction, achieving competitive performance across various contexts.
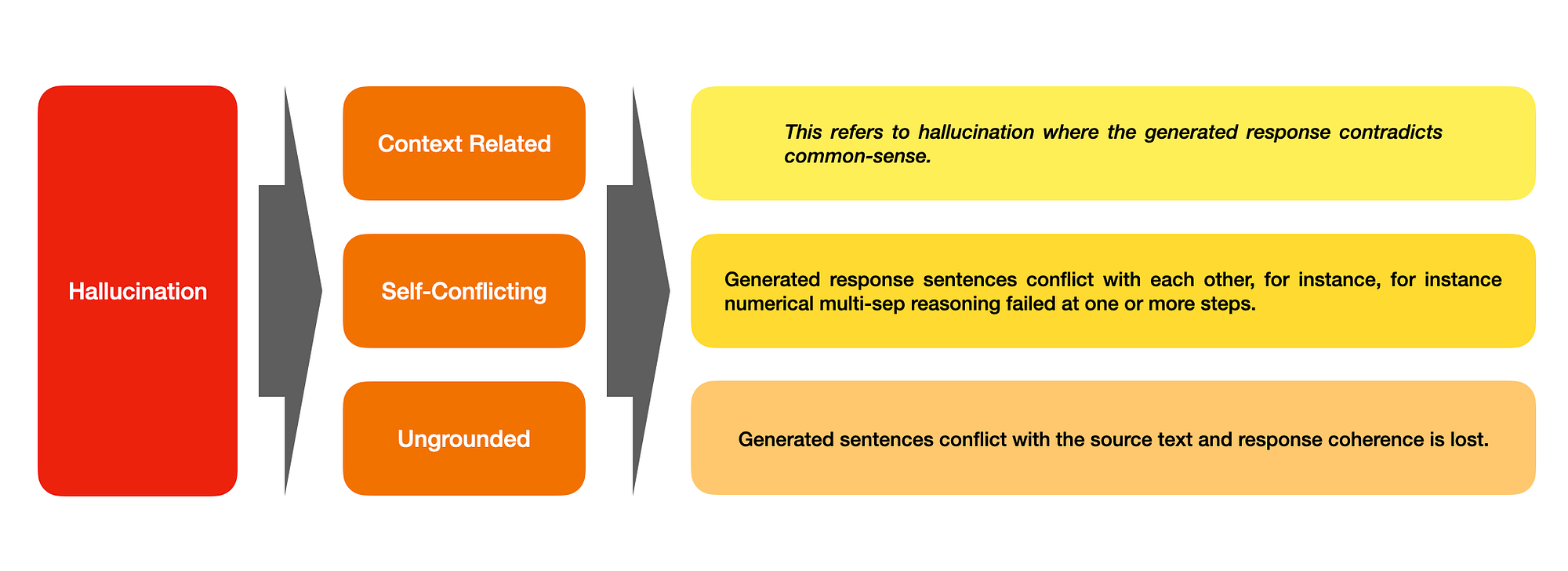
I like to describe ungrounded hallucination has LLM generated responses which are succinct, highly plausible and believable, but factually incorrect. — Author
Ecosystem Constraints
It needs to be stated that one of the objectives of the study was to achieve a reduction in hallucination in scenarios where the maker does not have full control over the LLM model or cannot leverage additional external knowledge.
Considering the image below, it is important to note that the study’s grounding strategy is rooted in four principles. And one of those principles is retrieving a contextual corpus of reference data.

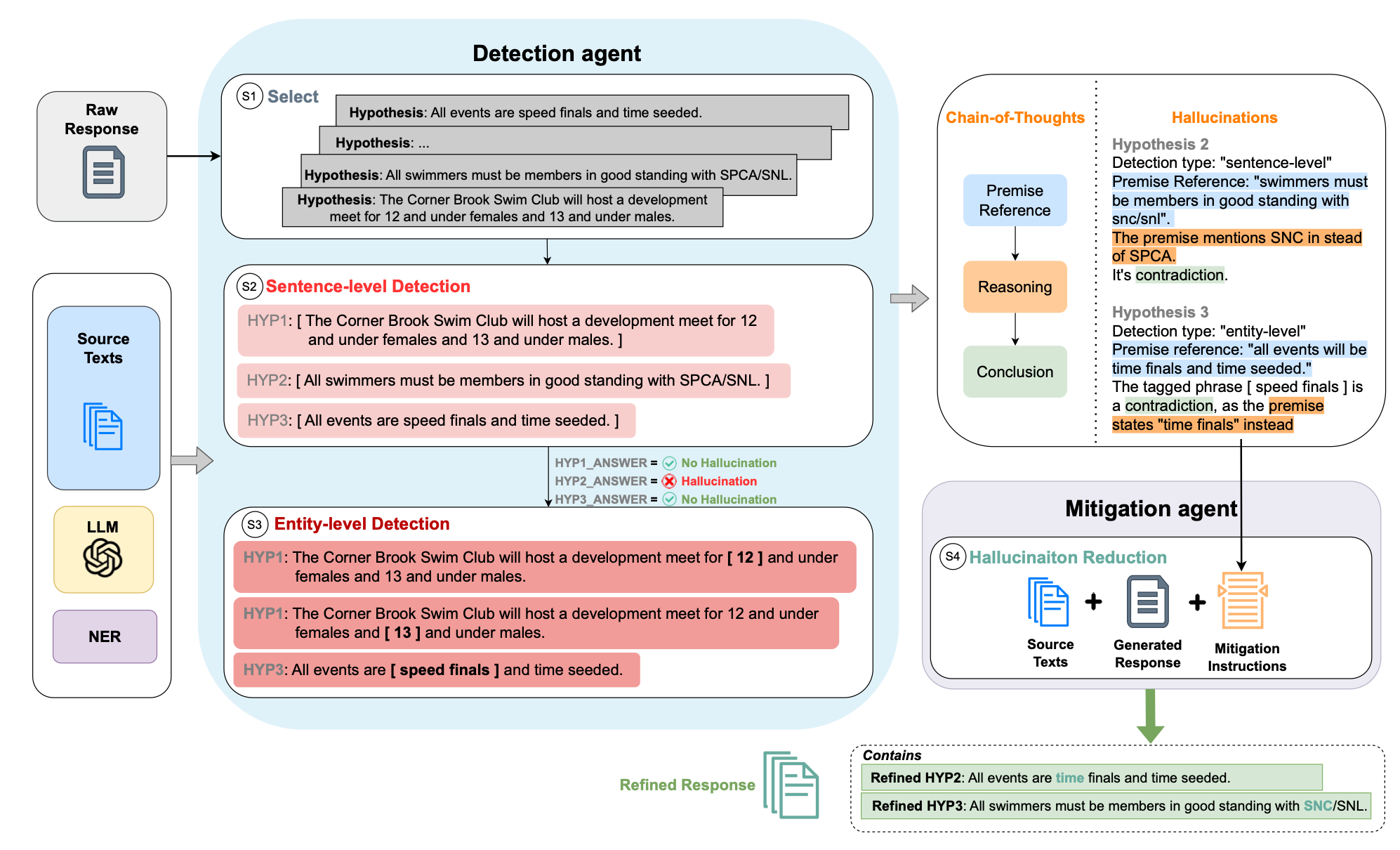
Considering the image below, the proposed framework of CoNLI is shown with a real example.
Each hypothesis in the raw response will first go through sentence-level detection.
If no hallucination is detected, it will go to detailed entity-level detection.
Detection reasonings will be used as mitigation instructions.
This is the second study, in a short period of time where sentence-level and entity-level detection are used to check generated text coherence and truthfulness.
Making use of entity detection is an effective approach as the range of standard named entities is wide and entity detection can be performed out of the box.
Finally
CoNLI was tested on text abstractive summarisation and grounded question-answering making use of both synthetic-generated and human-annotated data.
The study considered text-to-text datasets, which is the most prevalent use-case for realtime and off-line processing of especially unstructured data and conversations.
Some key considerations from the study…
- Astute prompt engineering techniques can negate hallucination.
- However, grounding with a contextual corpus is still highly effective.
- I love how NLU is making a comeback to check the LLM output. Where the framework performs a NLU pass on the generated text to ensure truthfulness.
- This approach is ideal in instances where the user does not have much autonomy over the LLM and access to data.
- The ideal would be to have human annotated data and the option to make use of RLHF in the process.
- This approach will most certainly introduce latency and cost.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.