Beyond Chain-of-Thought LLM Reasoning
This approach can be implemented on a prompt level and does not require any dedicated frameworks or pre-processing.
Introduction
A recent study addressed the need to enhance the reasoning capabilities of Large Language Models (LLMs) beyond Direct Reasoning (DR) frameworks like Chain-of-Thought and Self-Consistency, which may struggle with real-world tasks requiring Indirect Reasoning (IR).
The study proposed an IR method leveraging logic of contradictions for tasks like factual reasoning and mathematical proof.
The methodology involves augmenting data and rules using contrapositive logical equivalence and designing prompt templates for IR based on proof by contradiction.
The IR method is simple yet effective,
- Enhancing overall accuracy in factual reasoning by 27.33% and
- Mathematical proof by 31.43% compared to traditional DR methods.
- Combining IR & DR methods further boosts performance, highlighting the effectiveness of the proposed strategy.
LLMs excel at language comprehension, content generation, dialog management and logical reasoning.
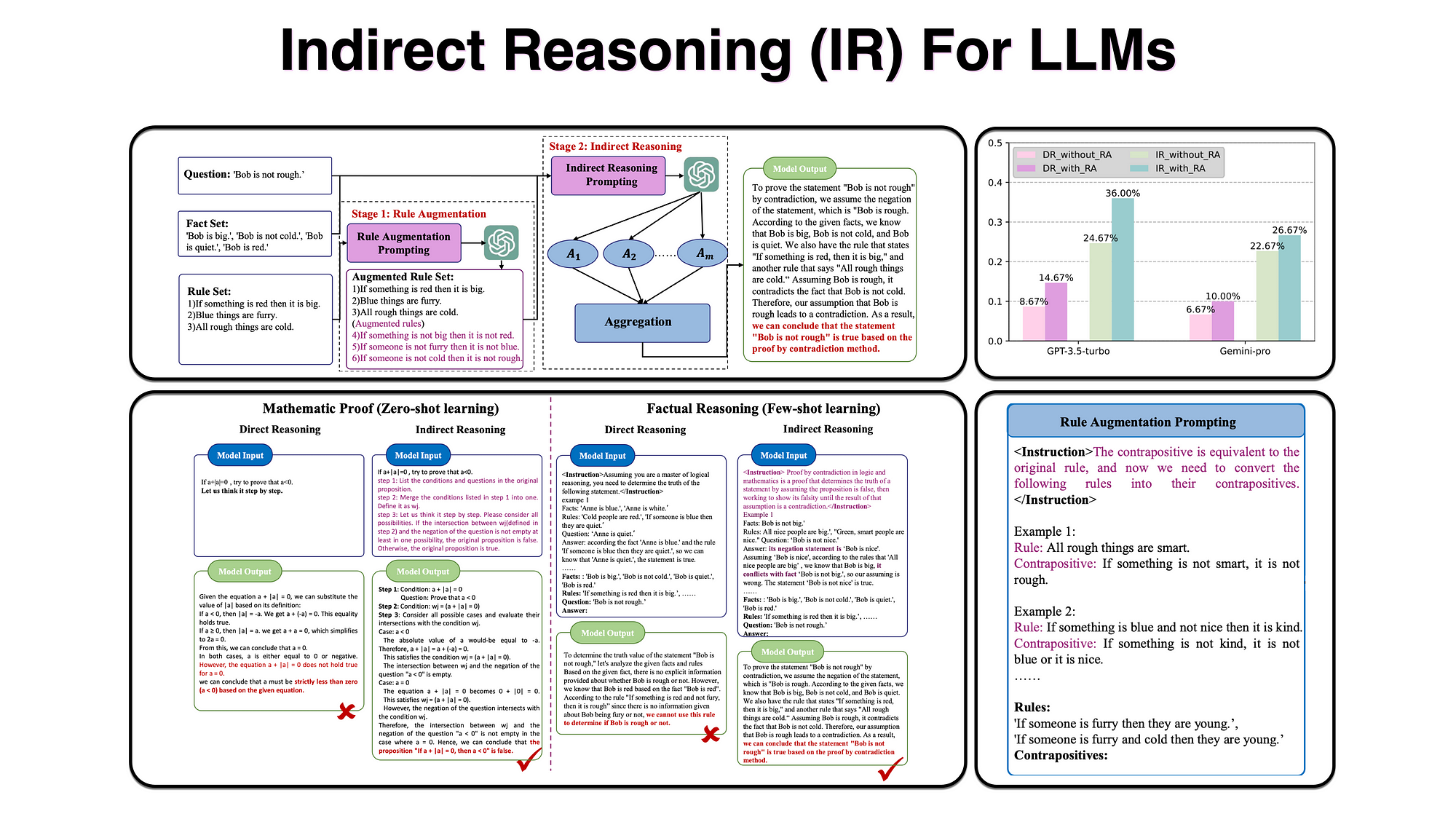
IR Prompt Structure
The image shows indirect reasoning (IR) with Large Language Models (LLMs) in zero-shot and few-shot learning scenarios. It is presented for complex issues involving mathematical proof and factual reasoning.
Traditional direct reasoning approaches might faltered in addressing these challenges.
In contrast, this methodology directs LLMs to employ contrapositive logic and contradictions, leading to precise reasoning and successful deduction of accurate answers.

The goal was to introduce novel strategies for employing Indirect Reasoning (IR) to address the constraints of direct reasoning. This approach offers an alternative and effective method for tackling practical problems.
The study also makes a number of prompt templates available which effectively stimulate LLMs to follow indirect reasoning.
Prompt Based
The aim of the study was to keep the implementation light and prompt based, without any dependancy on external data. Hence approaches like fine-tuning, RAG-based implementations, or tool base (agent-like) were avoided.
Rule Augmentation
LLMs often struggle to grasp complex rules, affecting their ability to use them effectively.
Consider the following:
Fact: Bob does not drive to work
Rule: If the weather is fine, Bob drives to work
Humans can apply the equivalence of contrapositive to deduce that the rule is equivalent to: If Bob does not drive to work, the weather is not fine hence humans can deduce.
And this allows humans to conclude based on the rule, that The weather is not fine .
LLMs can find this reasoning approach challenging, hence to address this issue, the study propose adding the contrapositive of rules to the rule set.
Hence applying at type of in-context learning, with few-shot learning.
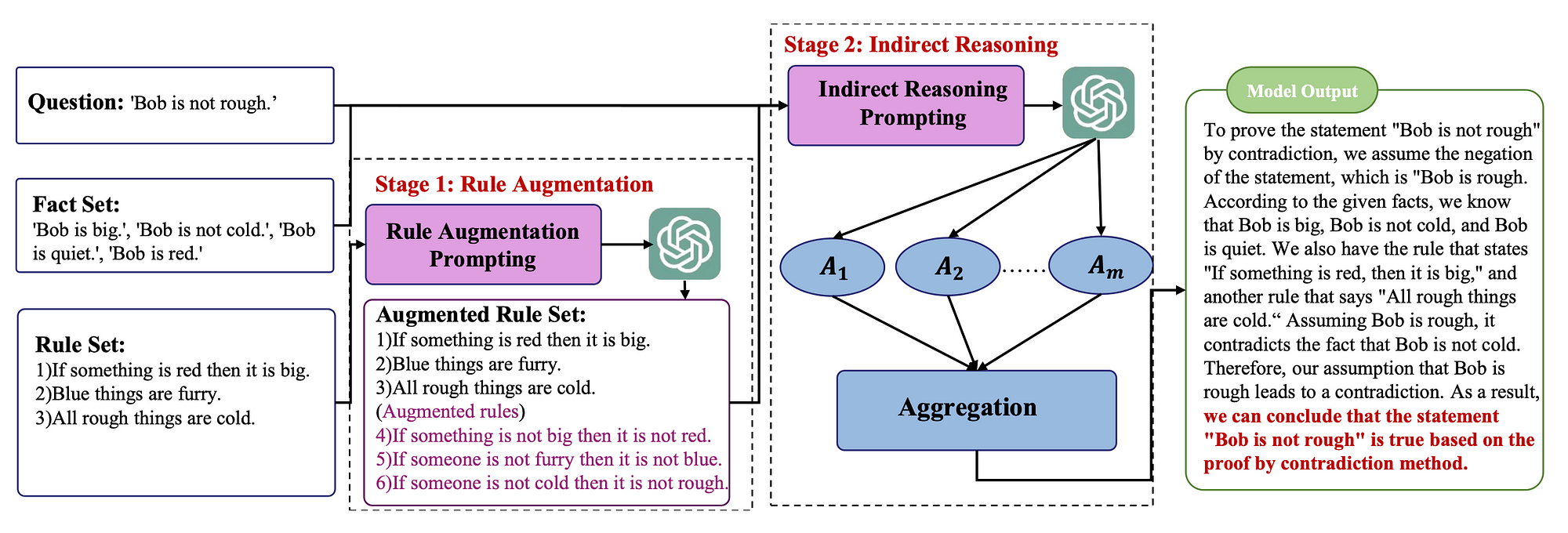
And here is a prompt template:
# <Instruction>The contrapositive is equivalent to the original rule,
and now we need to convert the following rules into their contrapositives.
</Instruction>
# Example 1
# Rule: [rule1]
# Contrapositive: [contrapositive1]
...
# Rules: [rules]
# Contrapositives:Performance
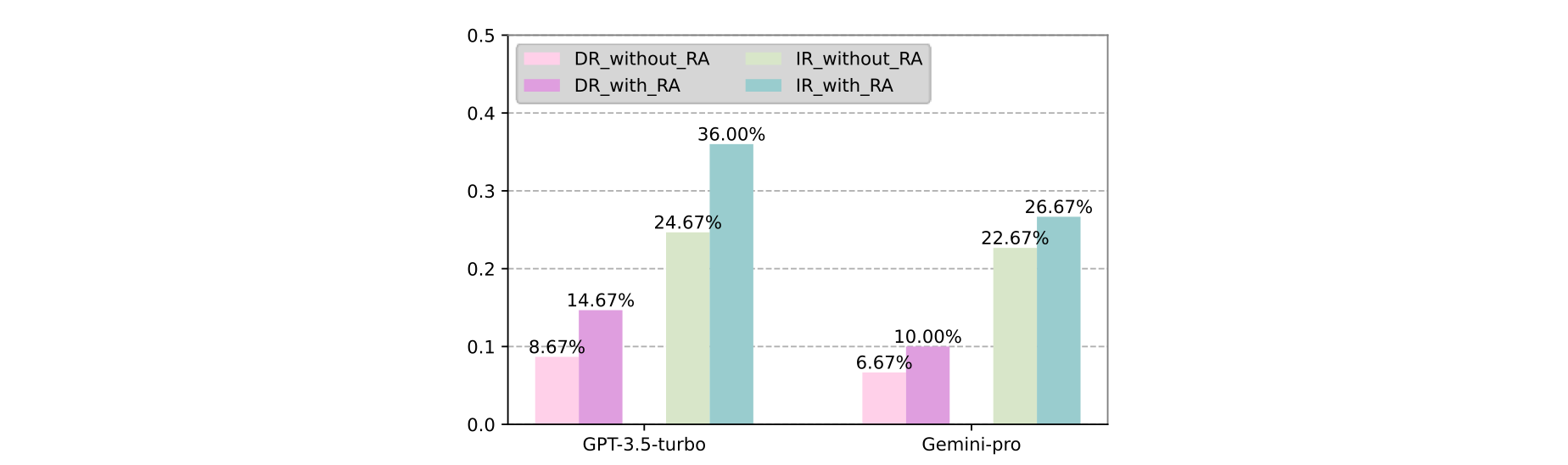
Considering the graph below, the comparison between GPT 3.5 turbo and Gemini-pro.
I was surprised by the jump in performance, an interesting piece of research to see which models respond best on IR with or without RA.
It is evident that both models showed below have a significant improvement in performance; but the spike in improvement from GPT.3.5 turbo on IR/RA scenario.
In Conclusion
Indirect reasoning effectively addresses challenges that cannot be directly resolved using known conditions and rules.
The study demonstrates the effectiveness of this method in factual reasoning and mathematical proof tasks, confirming its utility.
While this current study focuses on simple contrapositive and contradiction logic, future research could explore integrating more complex logical principles to enhance LLMs’ reasoning abilities further.

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.