Automatic Speech Recognition & The Rise Of Audio Intelligence
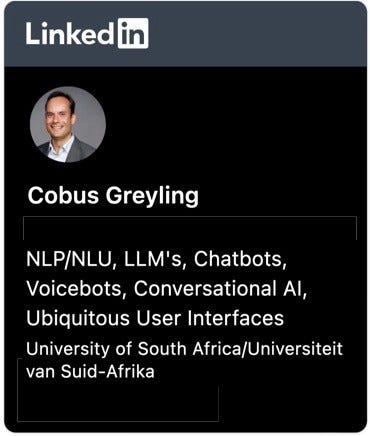
ASR transcription can be Extractive or Generative. With the Generative aspect of ASR poised for immense growth.

Introduction
Automatic Speech Recognition (ASR) is also referred to as Speech-To-Text (STT). ASR is the process of transcribing audio into text, which can be synchronous or asynchronous in nature.
Synchronous transcription is usually used for implementations like voicebots and agent assist scenarios.
Asynchronous implementations are for after-the-fact transcription of customer/agent conversations or other speech interactions. Redaction of PII comes into play for both audio and text and especially automated PII redaction.
ASR is the first line of defence when it comes to any voicebot or speech implementation, and is also one of the more challenging aspects to get right for a synchronous, low-latency speech implementation.
👉🏼 Please follow me on LinkedIn for Conversational AI Updates
Extractive ASR
Extractive ASR is where the audio is transcribed into text for downstream processing; usually NLP and or NLU.
Key Elements Of Extractive ASR:
▪️ Language Detection From Speech
This is vital in customer routing, updating CRM data and more. Language Detection is dependent and often impeded by the unavailability of a model for that particular human langauge.
Available models for language detection are in most cases more than that for transcription/extraction. Hence being able to detect language can inform the CX process if a particular user should be routed to a language specific agent.
A solution like Deepgram has more than 32 languages available for language detection.
Microsoft Azure Cognitive services offer langauge detection for more than 46 languages and many more locales.

▪️ Language Transcription From Speech
A solution like Microsoft currently accommodates > 139 languages for transcription from audio to text.
A key element of ASR is the ability to fine-tune for specific regional implementations to accommodate representation of age, gender, ethnicity, regional accents, product and industry specific names and terminology.
I’ll be remiss not to mention Whisper, the open-source ASR model from OpenAI. Considerations for using Whisper are:
- Cost of hosting, processing, API resilience…the list goes on
- Whisper is currently only intended for asynchronous use
- Fine-Tuning is not accommodated and Word Error Rate (WER) outside of the 5 primary languages are not production ready.
▪️Asynchronous Transcription
Asynchronous transcription has numerous use-cases, one is creating NLU training data from customer conversations. Most organisations have vast amounts of customer recordings which can be transcribed off-line and the text used for NLU Design and optimisation.
Generative ASR
Generative extraction is a feature which is available with most ASR’s, and will grow with the advent of large language models (LLMs).
Generative ASR is the process of using NLP to enhance the text output and make it more consumable for processes like NLU, NLP or just human intelligibility when reading the text.
Some examples of the generative step in ASR:
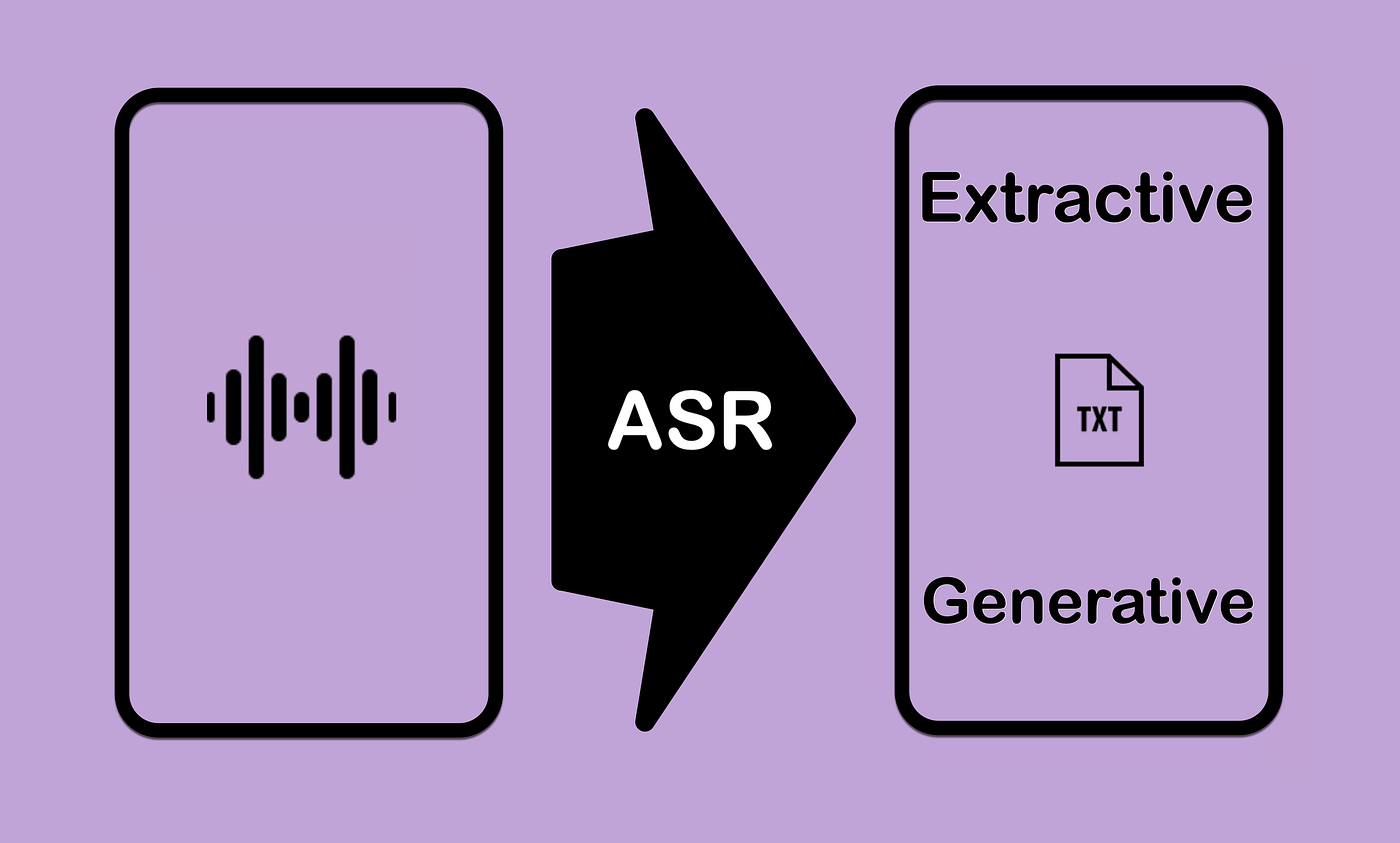
▪️Punctuation & Numerals
One of the most widely used generative features in ASR is adding punctuation and numbers, also referred to as Inverse Text Normalisation (ITN). This feature makes the text more user-friendly and legible.
Especially in agent-assist scenarios where the user speech is passed to the agent’s screen and subsequent submission to an agent-assist bot.
Adding punctuation can assist with a NLP high-pass prior to NLU processing especially in the case of sentence boundary detection. Sentence boundary detection is useful to break verbose user utterances into smaller segments for NLU processing. This also helps with detection of multiple intents and effectively offer disambiguation to the user.
▪️ Source-Based Generative Text
This is the process of optimising the text output based on a specific model.
For example, with Deepgram, there are a number of models available to optimise the text extracted based on the audio source. For instance the use-case or audio source specific models are:
- general,
- meeting,
- phone call,
- voicemail,
- financial vocabulary model,
- video audio optimisation
- voicebots.
▪️LLM Related Tasks
Other generative tasks which can be performed on the transcribed text include summarisation, named entity extraction, content moderation, key phrase extraction and more.
Some ASR providers allow for intents and entities to be defined within their ASR solution, hence we are seeing a close coupling of ASR and NLU.
As I have stated before, having a good WER helps to alleviate some of the strain on the NLU model.
NLU training data can be used to create and train a text based fine-tuning model for the ASR. This is above and beyond an audio based acoustic model for ASR.

As seen above, LLM’s do not pose a threat to ASR providers like Deepgram…instead it is an avenue to leverage and harness the power of that particular LLM.
Another case in point is HumanFirst’s integration with the LLM Cohere and allowing users to leverage Cohere from a no-code accelerated latent space for NLU Design.
In Conclusion
Voice and audio will become increasingly important from a CCAI and CAI point of view.
Especially due to the fact that ASR is an enabling technology for numerous CCAI use-cases.
Due to ASR technology being specialised, traditional chatbot development frameworks are forced to look outward for voice enablement partners and solution providers.
ASR companies also have a unique ability to expand their footprint and value proposition via leveraging LLMs and delivering on the unique value proposition of LLMs.
And lastly, branching into NLP and NLU functionality via what can be called generative ASR, traditional ASR companies can drastically augment the value of their output data.

I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.