Security Challenges Associated With AI Agents
A recent survey investigated the emerging security threats confronting AI Agents.
Considering Traditional Guardrails
There has been immense focus on guardrails for Language Models focus on enhancing safety, trust, and adaptability through mechanisms like trust modelling, adaptive restrictions, and contextual learning.
These guardrails manage user interactions by dynamically assessing trust levels, restricting responses based on risk, and mitigating potential misuse through composite trust evaluations. However, while these improvements are effective in controlling language model outputs, the security challenges of AI agents are far more complex.
AI Agents face threats such as unpredictable multi-step user inputs, intricate internal executions, and variable operational environments, which make them vulnerable to a broader range of exploits.
Additionally, their interactions with untrusted external entities introduce risks that current language model guardrails are not designed to address comprehensively. These complexities highlight the need for specialised security strategies to protect AI Agents in dynamic and real-world use cases.
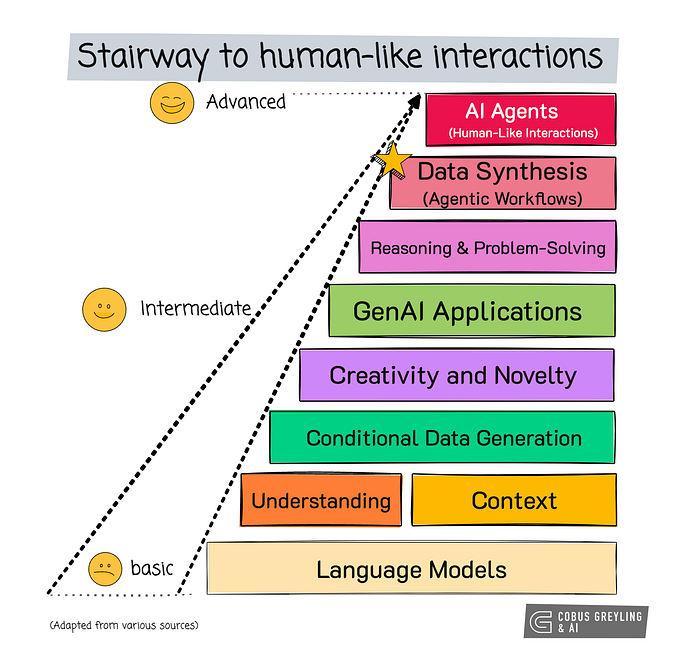
An Artificial Intelligence (AI) Agent is a software system designed to autonomously carry out tasks or make decisions based on specific goals and data inputs. These agents can interpret user inputs, reason and plan actions, and execute tasks without human intervention.
Introduction
The security challenges associated with AI Agents remain largely under-explored and unresolved.
A recent survey investigated the emerging security threats confronting AI Agents, and categorising these threats into four key areas: the unpredictability of multi-step user inputs, the complexity of internal processes, the variability of operational environments together with interactions with untrusted external entities.

AI Agent security refers to the measures and practices aimed at protecting AI Agents from vulnerabilities and threats that could compromise their functionality, integrity & safety.

Four Identified Vulnerabilities
Below, four vulnerabilities identified in the study…
1. Unpredictability of Multi-Step User Inputs
Users play a key role in guiding AI Agents by providing instructions and feedback during task execution.
AI Agents need to be more judicious with regards to user input, ensuring the correct amount of context and information is given.
Considering that the input for AI Agents are predominantly unstructured and conversational in nature, traditional conversational design principles can be applied.
For instance design elements like disambiguation and digression can be made use of. Digression detection can help with the AI Agent being alerted when the user digresses from the original context of the conversation.
Added to this, the AI Agent can also go through a process of establishing context prior to executing a task or a sequence of tasks.
These inputs, which reflect a wide range of user experiences, help AI Agents complete various tasks. But, multi-step inputs can create challenges when they are unclear or incomplete, potentially leading to unintended actions and security risks.
Poorly defined inputs can trigger a chain of unwanted responses, sometimes with serious consequences. Additionally, malicious users may deliberately prompt AI Agents to perform unsafe actions or execute harmful code.
Hence, ensuring clear, secure, and well-specified user inputs is essential, highlighting the need for flexible AI systems that can handle diverse and potentially risky interactions effectively.
2. Complexity in Internal Executions
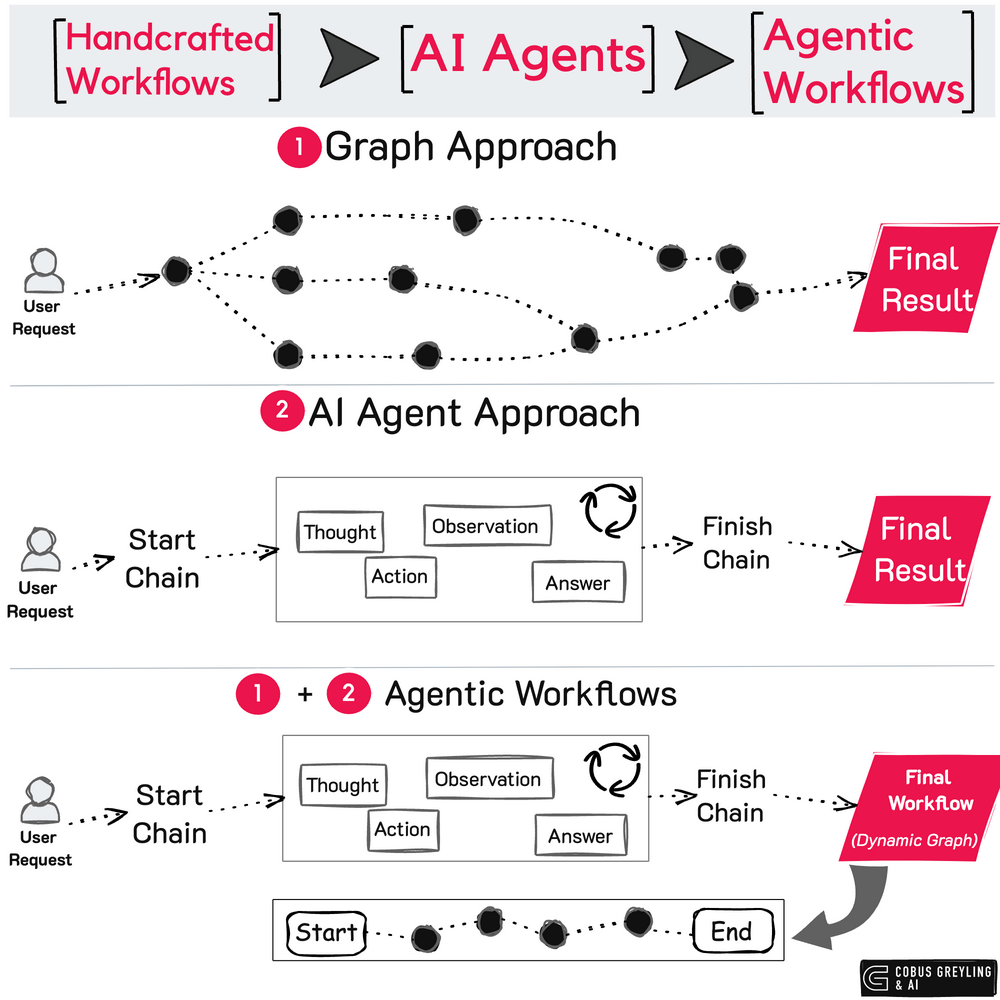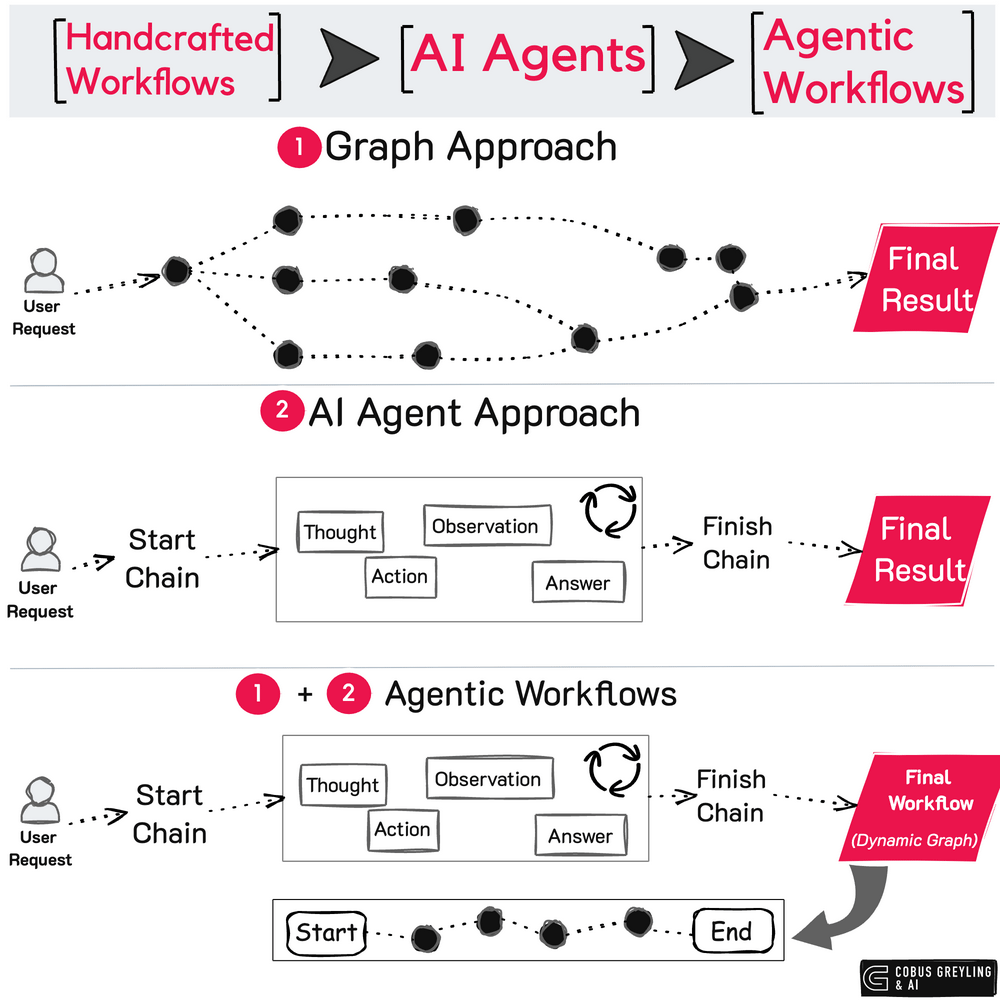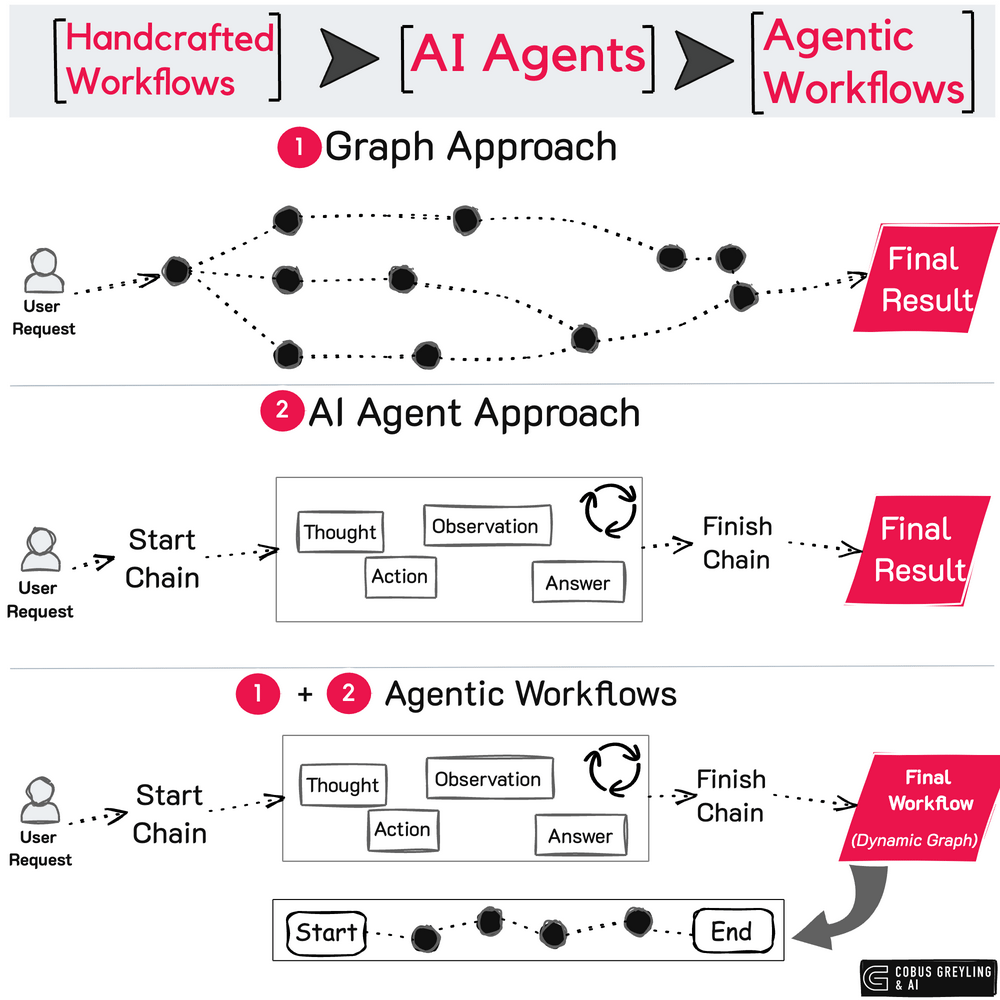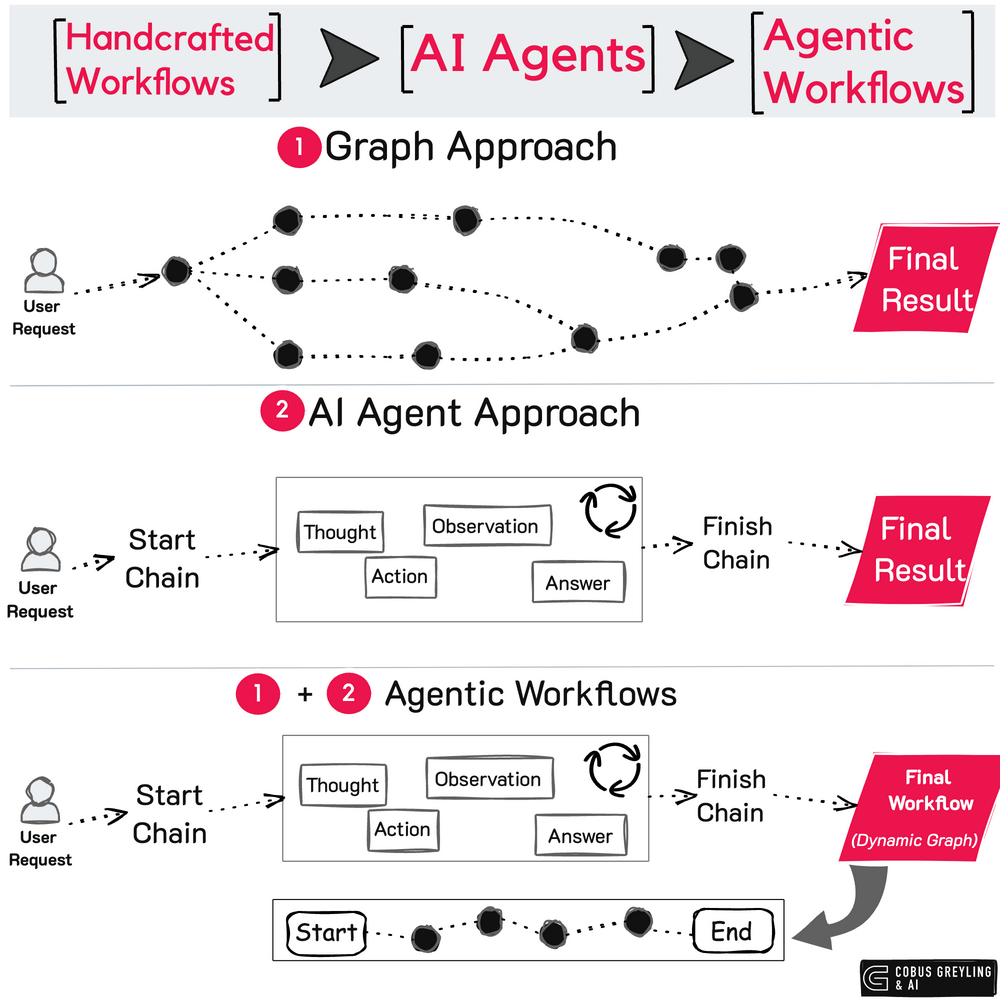
The internal execution state of an AI Agent involves a complex sequence of processes, including prompt reformatting, task planning by Large Language Models (LLMs) and the use of various tools.
Much of this internal execution is implicit and not readily observable, making it challenging to track these operations in real time.
Often with AI Agent frameworks, the elements of observability, inspectability and discoverability are not present. Hence increasing the risk of security vulnerabilities going undetected.
If these internal processes cannot be monitored effectively, potential issues or threats may only be identified after they cause harm. Therefore, improving AI Agent security requires comprehensive auditing mechanisms that can inspect and analyse the intricate internal workflows of individual AI agents to ensure safe and reliable operations.

3. Variability of Operational Environments
In real-world scenarios, AI Agents often operate across different environments during development, deployment, and execution phases.
The number and complexity of these environments will increase as with the proliferation of AI Agent use.
For example, consider for a moment the recent implementations of Computer GUI Use AI Agents, where the agent has access to the PC GUI to the same extent as an human would.
The operational environments will continue to become more variable and challenging.
These environments will vary significantly in the near future, leading to possible inconsistent behaviour and outcomes.
This variability makes it challenging to ensure that AI Agents complete tasks securely, especially when handling sensitive or critical operations.
As a result, maintaining consistent, secure performance across multiple environments requires robust safeguards and thorough testing to mitigate potential risks and vulnerabilities.
4. Interactions with Untrusted External Entities
A key function of AI Agents is their ability to instruct Language Models how to use tools and interact with other agents or external systems like the internet.

However, this process typically assumes that external entities are trusted, creating vulnerabilities and exposing AI Agents to various attack vectors, such as indirect prompt injection attacks.
These attacks occur when untrusted entities manipulate prompts to exploit the system. This assumption of trust poses a significant security risk, as often AI Agents lack mechanisms to verify or securely interact with untrusted external sources.
Developing methods for secure interaction with potentially hostile entities is a major challenge, requiring more resilient frameworks to protect agents from such threats.
The Future
The capabilities of AI Agents will continue to grow and diversify, especially in areas like computer and mobile UI usage.
As AI Agents gain the ability to access and interact with screens and applications, new security vulnerabilities will emerge.
For example, a recent study highlighted the risks of pop-up attacks, where malicious pop-ups appear while an AI Agent navigates the web, potentially misleading the AI Agent into making harmful decisions.
Just as it took time for humans to recognise phishing and similar threats, AI Agents will need to develop the ability to detect and avoid such attacks.
This highlights the increasing importance of building secure, resilient AI systems as they take on more complex tasks in the future.
Chief Evangelist @ Kore.ai | I’m passionate about exploring the intersection of AI and language. From Language Models, AI Agents to Agentic Applications, Development Frameworks & Data-Centric Productivity Tools, I share insights and ideas on how these technologies are shaping the future.