Meta-In-Context Learning For Large Language Models (LLMs)
A recent study coined the term meta-in-context learning, and while the principle is clearly explained in the study, there are a number of practicalities to consider for production implementations.
TL;DR
- Demonstrations at inference acts as an excellent contextual reference.
- The study states that LLMs offer the ability to eschew fine-tuning altogether and rely solely on contextual reference information at inference.
- However, fine-tuning should not be neglected and brings other benefits to the use of LLMs.
- The study found that sequentially presenting LLMs with multiple learning problems boosts their in-context learning abilities.
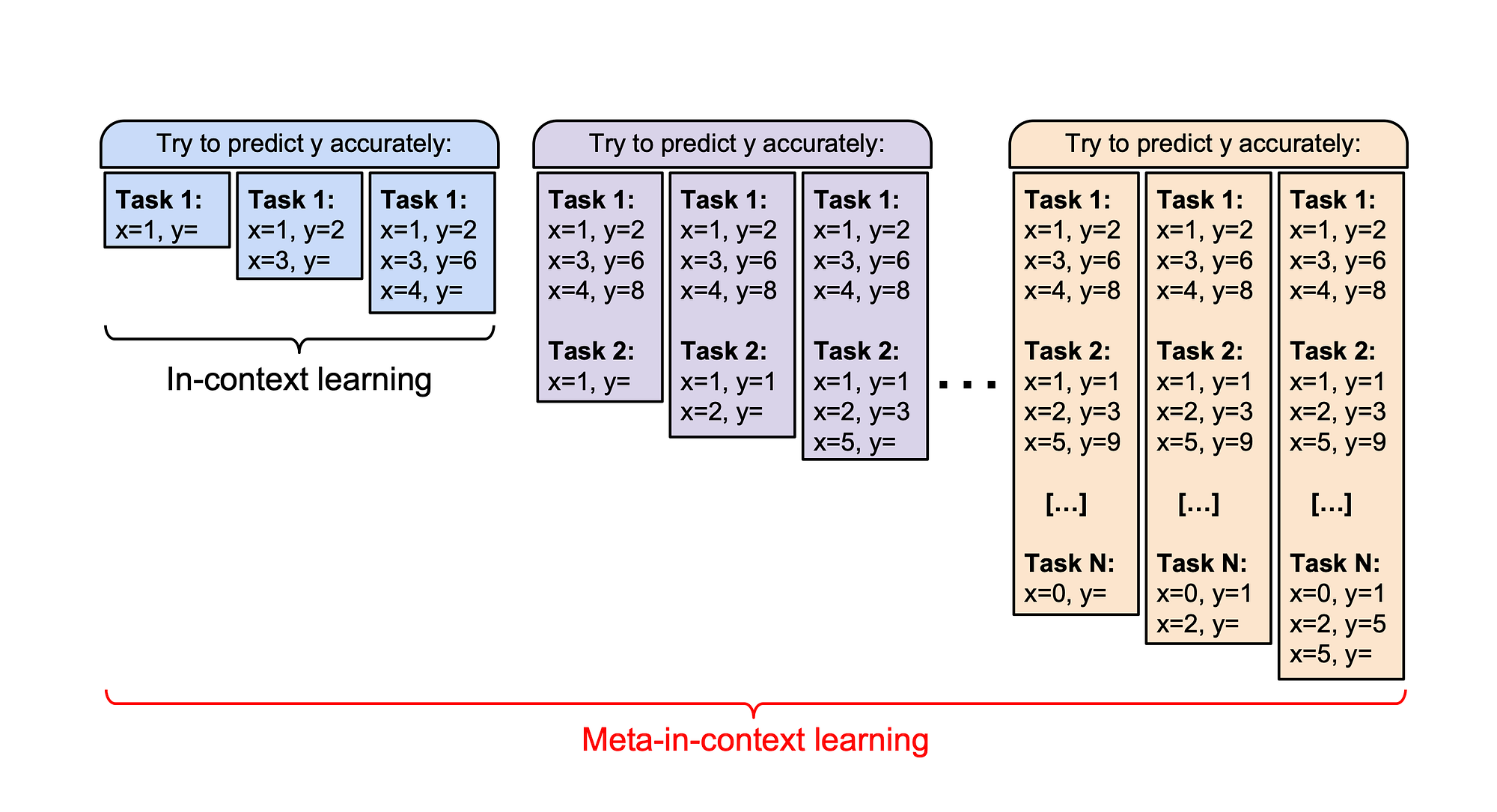
- In-context learning is the ability to improve at a task after being provided with a number of demonstrations, and
- demonstrate that the in-context learning abilities of large language models can be recursively improved via in-context learning itself.
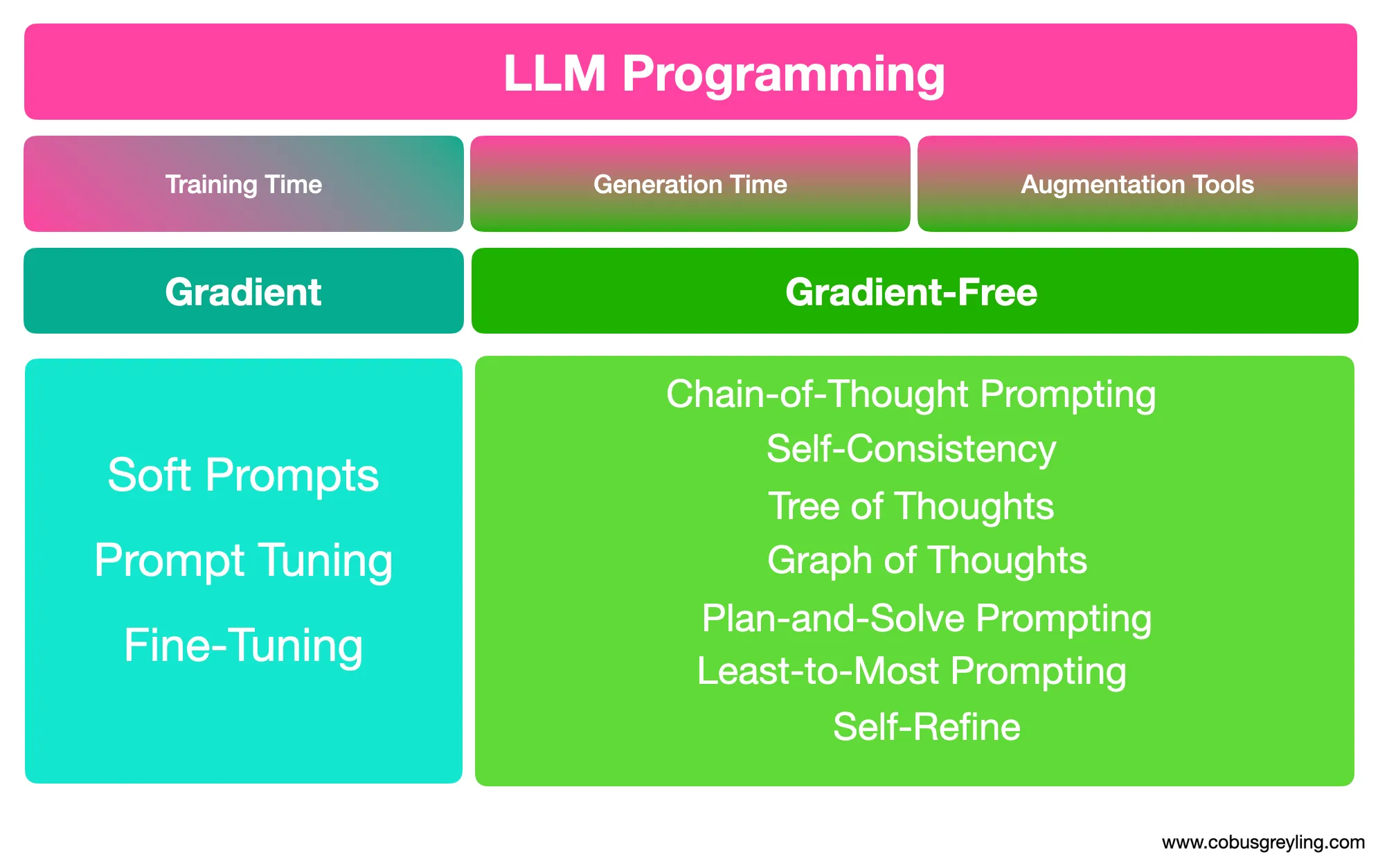
- Implementations can solely rely on a few-shot learning approach to some degree, specially when task-specific data and contextual information are available. However, as stated before, model-fine tuning and prompt engineering approaches should be used in concert.
In-context learning is also referred to as few-shot learning or few-shot prompting.
Considerations
- In a production setting response times and latency efficiencies are very important, especially for a conversational UI implementations.
- Inference cost (the amount of input tokens used) is also a consideration when longer input is given to the LLM.
- Constituting (putting together) the meta-in-context learning reference and injecting it into a prompt at production will demand speed and contextual accuracy at a greater scale than traditional RAG implementations.
- The available LLM Context Window will become increasingly important as more few-shot training data submitted to the LLM at inference.
- The study states the following: “Meta-in-context learning was not only able to overwrite an LLM’s priors but also changed its learning strategies, as demonstrated in two artificial domains.” I’m curious to understand how the learning strategies of the LLM changed, this is surely when the LLM is presented with the Meta-In-Context Learning approach at inference only. But the line from the study seems to imply more.
Final Thoughts
In-context few-shot learning is the practise of injecting a prompt with contextual reference data which can include a number of demonstrations.
This paper demonstrates that the in-context learning abilities of large language models can be recursively improved via in-context learning itself.
If anything, this study underlines the importance of context, context can be introduced via fine-tuning, and/or at inference via contextually rich prompts.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.



