
Create A Question Answering Chatbot Using NVIDIA Riva
With Wikipedia API Integration To Generate Answers

Introduction
NVIDIA Riva brings deep learning to the masses. The multimodal aspect of Riva is best understood in the context of where NVIDIA wants to take Riva in terms of functionality.

What is exciting about this collection of functionality, is that Riva is poised to become a true Conversational Agent. We communicate as humans not only in voice, but by detecting the gaze of the speaker, lip activity etc.
Another key focus are of Riva is transfer learning. There is significant cost saving when it comes to taking the advanced base models of Riva and repurposing them for specific uses.
The functionality which is currently available in Riva includes ASR, STT and NLU. Edge installation is a huge benefit.

Setting Up Your Environment
Access to NVIDA software, Jupyter Notebooks and demo applications are easy and resources are abundant. The only impediment is access to a NVIDIA GPU based on the Turing or Volta architecture.
In this article I look at one of the more cost effective ways to access such infrastructure via an AWS EC2 instance.
After spinning up the NVIDIA Deep Learning AMI, install NVIDIA GPU Cloud.

To install NVIDIA GPU Cloud (NGC), run the four commands below. During this process you will also be asked for your NGC API Key. The NGC CLI binary for ARM64 is supported on Ubuntu 18.04 and later distributions..
wget -O ngccli_linux.zip https://ngc.nvidia.com/downloads/ngccli_linux.zip && unzip -o ngccli_linux.zip && chmod u+x ngcmd5sum -c ngc.md5echo "export PATH=\"\$PATH:$(pwd)\"" >> ~/.bash_profile && source ~/.bash_profilengc config set
When installing NVIDIA Riva, run this list of commands:
ngc registry resource download-version
nvidia/riva/riva_quickstart:1.4.0-betacd riva_quickstart_v1.4.0-betabash riva_init.shbash riva_start.shbash riva_start_client.shjupyter notebook --ip=0.0.0.0 --allow-root --notebook-dir=/work/notebooks
On executing the last command, you will be presented with an:
- URL
- Port (8888)
- and a token.

NVIDIA Riva Notebooks
To get you started, NVIDIA has quite a few Jupyter Notebook examples available which you can use to step through. These comprise of different speech implementations, including speech to text, text to speech, named entities, intent & slot detection and more.
Read more about this functionality here…

Wikipedia Question Answer Functionality
On to the Wikipedia Question and Answer notebook example…
First, you need to cd into the installation directory of Riva…
cd riva_quickstart_v1.4.0-betaThen, to launch the Riva services, run this command…
bash riva_start.shStart a container with sample clients for each service…
bash riva_start_client.shLastly, from the command line, start a Jupyter Notebook instance and access it from your local machine.
jupyter notebook --ip=0.0.0.0 --allow-root --notebook-dir=/work/notebooksYou will need to make use of SSH tunneling to access the notebook instance from your browser remotely.
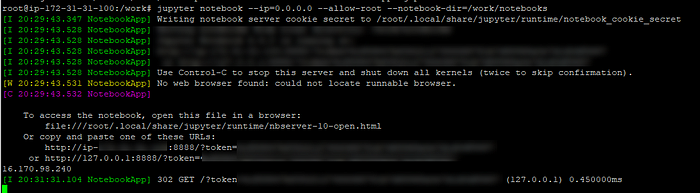
Seeing this screen means you have successfully accessed the Jupyter Notebook. Enter the token which was presented when you launched the notebook from the command line.
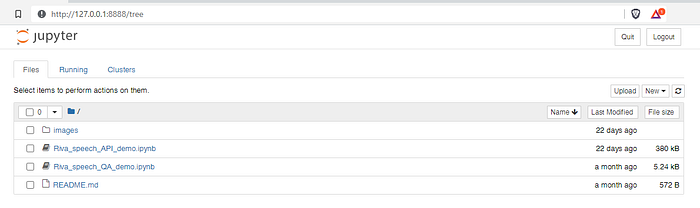
And navigate to the Riva Speech QA demo folder…
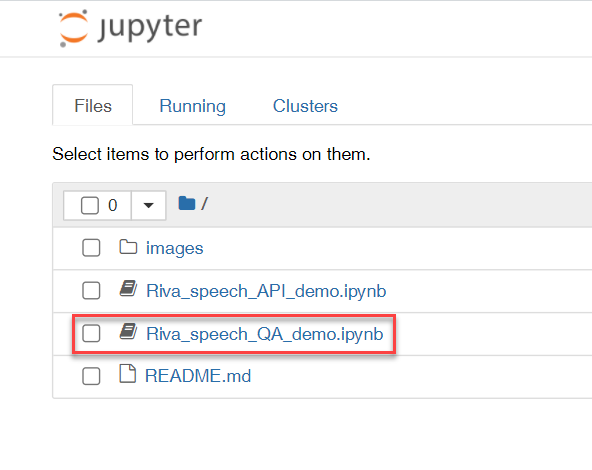
You will see there are more demo applications available, click on Speech QA.
This is the start of the Wikipedia Question Answering notebook. You can click on Run and step through the application without making any changes or configuration updates.

The input and output of this note book is text based. Here is an example of a query and answer.
Query: What is speech recognition?Answer: an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by computers.


Looking At Some Details
This shows how you can update the Jupyter notebook to ask Wikipedia a different question and where the answer or output is printed. Just take note that if your question is too ambiguous, the answer will not be presented as neatly, and the disambiguation options will be shown.
I also experimented with the max_articles_combine parameter by setting it to “1” instead of the default “3”.

This shows where you can change your question, re-run the code and get a different output.
The last example is where the input query is changed to “What is Cape Town?”, and a summary is returned from Wikipedia for the named entity Cape Town.

Speed of execution is impressive and the possible implementations of such functionality is limitless.

Conclusion
My first thought was that getting past the point of an own installation and running the demos would be very daunting…seeing this is a NVIDA and deep learning environment.
But on the contrary, getting to grips with Riva on a demo application level was straight forward when following the documentation. After running this basic demo voicebot, what are the next steps?
The voicebot where Rasa integration to Riva is performed is a step up in complexity and a logic next step. Also perusing the Jupyter Notebooks provide good examples on how to interact with API’s.


