Chain-Of-Thought Prompting & LLM Reasoning
When we as humans are faced with a complicated reasoning task, such as a multi-step math word problem, we segment our thought process. We typically divide the problem into smaller steps and solve each of those before providing an answer.

I’m currently the Chief Evangelist @ HumanFirst. I explore & write about all things at the intersection of AI and language. Including NLU design, evaluation & optimisation. Data-centric prompt tuning & LLM observability, evaluation & fine-tuning.
Intuitively we as humans break a larger task or problem into sub-tasks, and then we chain these sub-tasks together. Using the output of one sub-task as the input for the next sub-test.
By using chain-of-thought prompting within the OpenAI Playground, a method wherein specific examples of chain of thought are provided as guidance, it is possible to showcase how large language models can develop sophisticated reasoning capabilities.
Research has shown that sufficiently large language models can enable the emergence of reasoning abilities when prompted in this way.
A chain of thought is a series of intermediate natural language reasoning steps that lead to the final output, and we refer to this approach as chain-of-thought prompting. ~ Source
The utilisation of chain-of-thought reasoning is particularly evident when examining LLM-based agents.
LLM based Agents have the ability to decompose a question into a chain-of-thought and answer the question in a piecemeal fashion. Considering each of the steps.
⭐️ Please follow me on LinkedIn for updates on LLMs ⭐️
Within a playground setting, the principle behind chain-of-thought prompting can be illustrated by following a few-shot learning approach.
A LLM is given a few examples on how to decompose a complex and ambiguous question. And by doing so, establish a chain-of-thought process.
For instance, the question Who is regarded as the father of the iPhone and what is the square root of his year of birth? can only be correctly answered by decomposing the question in sequential chain-of-thought steps.
Below is the decomposed chain-of-thought reasoning of the Agent based on the aforementioned question. The decomposition was performed completely autonomously by the Agent.

As seen in the image above, Chain-of-thought prompting enables large language models to address challenging arithmetic, common sense, and symbolic reasoning challenges.
Rather than adjusting a distinct language model checkpoint for each new task, one can simply provide the model with several input-output examples to demonstrate the task.
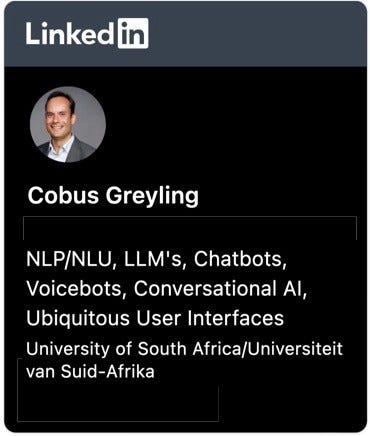
Consider the image below, with two OpenAI playground examples. The top example is a few-shot training prompt, providing text_davinci-003 with one question and answer pair, followed by a question to be answered by the LLM.
The top example does not contain a chain-of-thought reasoning example, hence the LLM only provides the answer.
The bottom playground example has a simple chain-of-thought reasoning prompt, giving the LLM a reference as how to answer the question.
You can see the answer given by the LLM is expanded, showing the chain-of-thought reasoning used by the LLM.
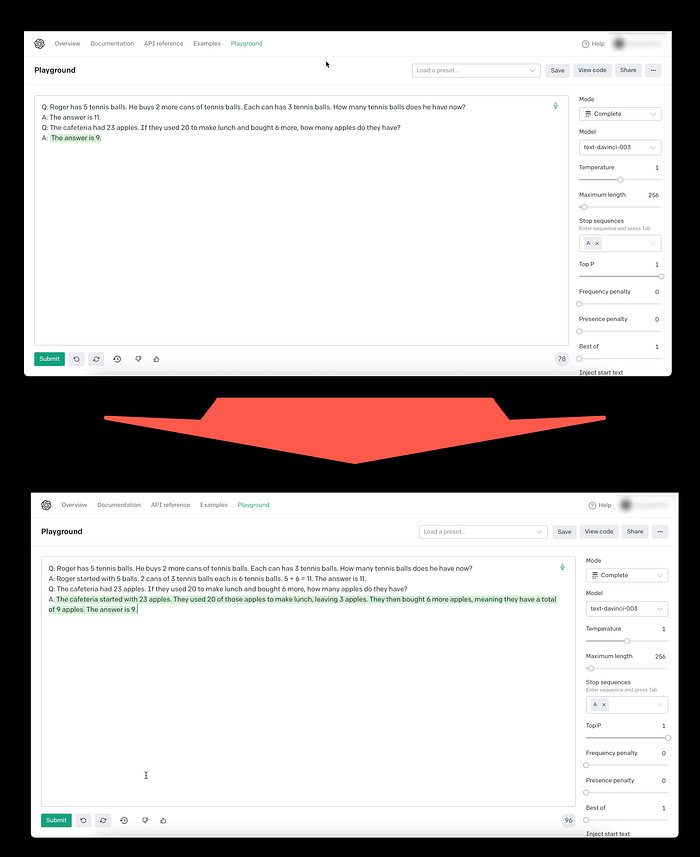
Additionally, benefits of this approach is improved accuracy with the model illustrating how it reach a conclusion or answer. The augmented answer makes for a more conversational and informative response.
⭐️ Please follow me on LinkedIn for updates on LLMs ⭐️
I’m currently the Chief Evangelist @ HumanFirst. I explore and write about all things at the intersection of AI and language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces and more.