
A Mixed Modality Approach To Chatbots
Often Users Want Unstructured Input But Highly Structured Output
Introduction
“The Medium Is The Message” ~ Marshall McLuhan
A modality is a particular way of doing or experiencing something. That something can be a chatbot, voicebot or conversational interface.
The modality can be voice or text…the modality can also be graphic, visual and structured.
However, this is highly dependent on device you are using. Think of an Echo Dot opposed to an Echo Show, for instance. So there is this tendency of an ideal environment for a user: highly unstructured input, very conversational like. Hence the user input is pure text or voice.
The output again is very structured, graphic and leverage all the possible affordances of the modality.

This is the fastest and most convenient input for the user, free speech which is compounded. But the output is structured, not ephemeral but lasting; and easy to digest visually and audibly.
This approach is heavily reliant on the device you are using. And also reliant on the medium you are making use of. Examples of mediums are WhatsApp, Messenger, Web Chat etc.
A medium like Messenger has more option to present and structure your output compared to WhatsApp for instance.
This brings us to the idea of Conversational Components.
Conversational Components
Firstly we need to think of any conversation, be it in voice or text, of being presented to the user by means of conversational components…
Conversational Components are the different elements (or affordances if you like) available within a specific medium.
For instance, within Facebook Messenger there are buttons, carousels, menus, quick replies and the like.

These allow the developer to leverage these conversational components to the maximum hence negating any notion of a pure natural language conversational interface.
It is merely a graphic interface living within a conversational medium. Or, if you like, a graphic user interface made available within a conversational container.
Is this wrong…no.
It is taking the interface to the user’s medium of choice. Hence making it more accessible and removing the friction apps present.
The problem with such an approach is that you are heavily dependent on the affordances of the medium.
Should you want to roll your chatbot out on WhatsApp, the same conversational components will obviously not be available, and you will have to lean more on NLU, keyword spotting or a menu driven solution. With a even more basic medium like SMS are are really dependent on NLU or a number/key word driven menu.
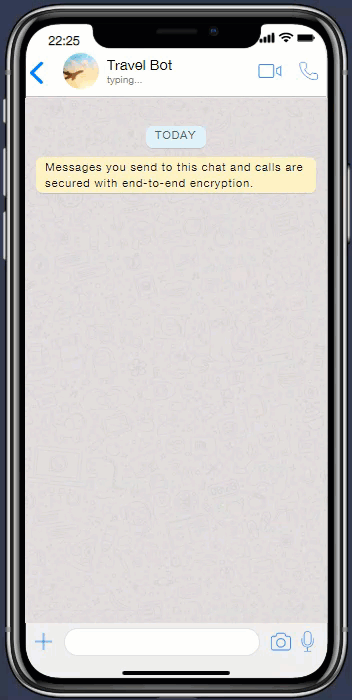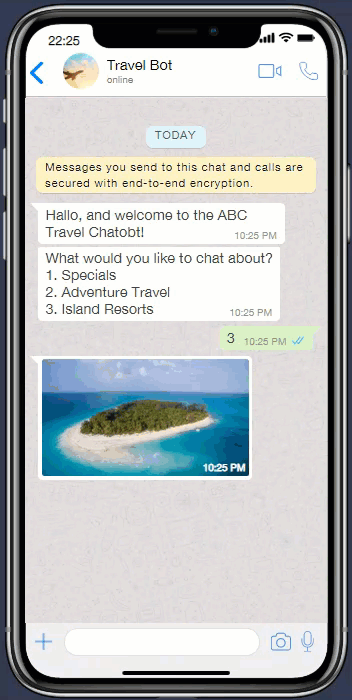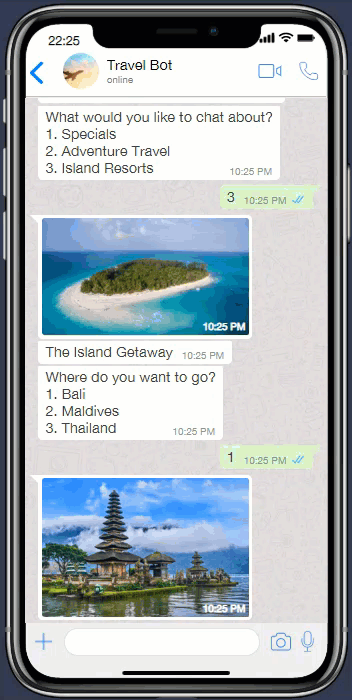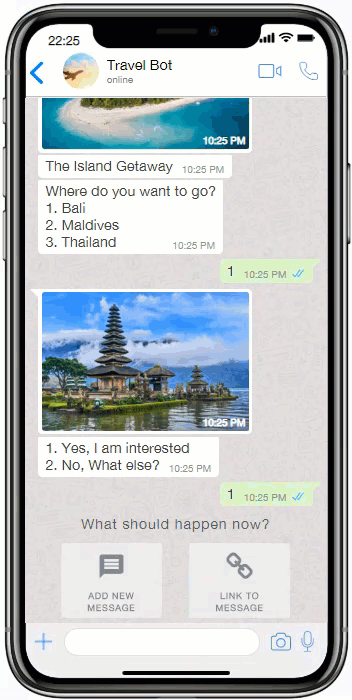
Where the menu is constituted by keywords or numbers, the menu will have to be a key word or number the user need to input to navigate the UI.
Is it a chatbot?
Technically, yes; as it lives in a multi-threaded asynchronous conversational medium.
But is it conversational in nature? One would have to argue no.
So in the second example a rudimentary approach needs to be followed for one single reason, the medium does not afford the rich functionality and is primarily text based.
With Voice, these components disappear completely. With only the natural language component available within the Voice User Interface (VUI) environment there are no components to leverage with the affordances are invisible.
Voice Search
One trend showing people’s propensity for a mixed modality approach is voice search. The trend where we speak into our browser and have our usual search results return.
Think of Google as the biggest single dialog turn chatbot in the world.
Somewhere we migrated from searching with key words and cryptic phrases to a point where we search in natural language. Structuring our query to Google in a natural language sentence.
There are various statistics reporting on this, with most stating that 80% of searches are in natural language. It was widely predicted that 50% of all searches in 2020 will be via voice.
Example: Responses With Cards
There are messages which simply consist of plain text and there are also richer message content such as cards.
Bot Framework Composer supports responses which are graphic cards.
Through this the chatbot’s design can be improved and the data presented can be easier digested.
Conclusion
There are purists arguing for the use of only natural language…
Seemingly we are heading for a world where it’s a mixed modality. Natural language input in the form of free speech. But where possible and environment allowing, a structured multi-modal output.
