
8 Steps To Using Both NLP & NLU In Your Chatbot
Improve Chatbot Resilience With An Initial High-Pass NLP Layer

Introduction
Generally conversational resilience is lacking in most chatbot interfaces…
This lack of resilience is exacerbated by multiple language environments and long compound user input.

For example, language detection is a technology which is generally available.
Detection is even available for smaller languages; like Afrikaans. Yet it is not implemented.
Another impediment to conversational resilience is long user input.
Why can the chatbot not execute sentence boundary detection. Thus informing the user accordingly and handling the utterance per sentence. And by implication, per intent.
Or, at least try and find the named entities from the conversation in an attempt to make sense of the user input.
There is nothing wrong with a chatbot asking for clarity on user input. For instance, the chatbot stating: “You just sent me what looks like 5 sentences on your experience at our Seattle branch. Please tell me what action do you want me to take in approximately 10 words”.
This informs the user that the basic gist of their utterance is not lost, and they need to articulate differently.
Many of the elements mentioned in this article is not catered for in general NLU, or incorporated in Chatbot environments.
A Different Approach
Introduce a first, high-pass Natural Language Processing (NLP) layer. This layer will analyze the text of the user input.

This being the dialog or utterance sent through from the user. This layer will perform pre-processing on the text and from here make the dialog digestible for the chatbot NLU layer.
Allowing the chatbot to answer a long compound question we as humans will answer the question.
We as humans take the question from the top down and answer different aspects of the question.
Step 1: Automatic Language Detection
The chatbot can only accommodate a finite number of languages; usually it is a single language. The last thing you want is your user rambling on in a language your chatbot does not accommodate.
Consider the scenario where your chatbot keeps on replying with a “I do not understand” dialog, while the user tweak their utterances in an attempt to get a suitable response from the chatbot. All the while the language used by the chatbot is not provisioned in the bot.
Especially for multinational organizations this can be a pain-point.
It is such an easy implemented solution to to a first-pass language check on user input to determine the language, and subsequently respond to the user advising on the languages available.
The nice part is, you don’t have to always identify which of the 6,500 languages in the world your user speaks. You just need to know the user is not using one of the languages your chatbot can speak.
It is however, a nice feature to have, where your chatbot advises the user that currently they are speaking French, but the chatbot only makes provision for English and Spanish. This can be implemented in a limited fashion though.
Step 2: Grammar Correction
There are existing grammar and spelling correcting API’s.

But, often these mechanisms do not suffice. In cases where an intent and entities cannot be detected, the user utterance can be run through the Grammar correction API. As you can see from the examples above, the sentences provided are corrected to a large degree.
Step 3: Sentence Boundary Detection
An initial process can be to extract reasonable sentences, especially when the format and domain of the input text are unknown. The size of the input and the number of intents can be loosely gauged by the amount of sentences.
This also allows for parsing the user input separately and responding to the user accordingly.

Irrelevant sentences can be ignored, and sentences with a good intent and entity match can be given special attention in reverting to the user.
Step 4: Find All Named Entities
But first, what is an entity?
Entities are the information in the user input that is relevant to the user’s intentions.
Intents can be seen as verbs (the action a user wants to execute), entities represent nouns (for example; the city, the date, the time, the brand, the product.).
Consider this, when the intent is to get a weather forecast, the relevant location and date entities are required before the application can return an accurate forecast.
Recognizing entities in the user’s input helps you to craft more useful, targeted responses.
For example, You might have a #buy_something intent. When a user makes a request that triggers the #buy_something intent, the assistant’s response should reflect an understanding of what the something is that the customer wants to buy. You can add a product entity, and then use it to extract information from the user input about the product that the customer is interested in.

spaCy has a very efficient entity detection system which also assigns labels. The default model identifies a host of named and numeric entities. This can include places, companies, products and the like.
- Text: The original entity text.
- Start: Index of start of entity in the doc
- End: Index of end of entity in the doc
- Label: Entity label, i.e. type
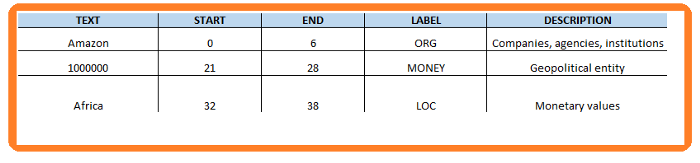
In NLP, a named entity is a real-world object, such as people, places, companies, products etc.
These named entities can be abstract or have a physical existence. Below are examples of named entities being detected by Riva NLU.
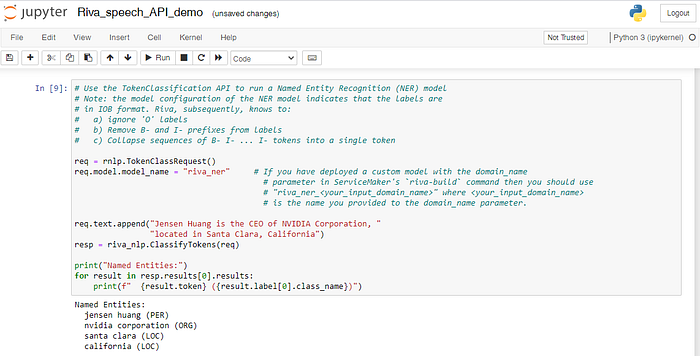
Named Entities code block in the Jupyter Notebook from a NVIDIA Riva implementation.
Example Input:
Jensen Huang is the CEO of NVIDIA Corporation, located in Santa Clara, California.Example Output:
Named Entities:
jensen huang (PER)
nvidia corporation (ORG)
santa clara (LOC)
california (LOC)Step 5: Parse Unstructured Data
Create tables from long form text by specifying a structure and supplying some examples.

Here you can see the first entry is directly related to the sentence. The subsequent entries are somehow related and still relevant and applicable.
Classification
Classify items into categories via example inputs. Companies are named with categories defined. A new company can be mentioned and auto classified.

With limited training data a new company can be mentioned and auto classified.
Step 6: Determine Dependencies
Words can often have different meanings depending on the how it is used within a sentence. Hence analyzing how a sentence is constructed can help us determine how single worlds relate to each other.
If we look at the sentence, “Mary rows the boat.”. There are two nouns, being Mary and boat. There is also a single verb, being rows. To understand the sentence correctly, the word order is important, we cannot only look at the words and their part of speech.
Now this will be an arduous task, but within spaCy we can use noun chunks. According to the spaCy documentation, You can think of noun chunks as a noun plus the words describing the noun — for example, “the lavish green grass” or “the world’s largest tech fund”. To get the noun chunks in a document, simply iterate over Doc.noun_chunks.

The sentence “Smart phones pose a problem for insurance companies in terms of fraudulent claims”, returns the following data:
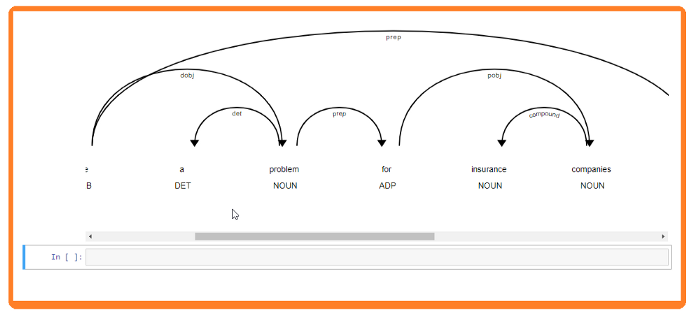

Text is the original noun chunk text. Root text is the original text of the word connecting the noun chunk to the rest o the phrase. Root dep: Dependency relation connecting the root to its head. Root head text: The text of the root token’s head.
- NSUBJ denotes Nominal subject.
- DOBJ is a direct object.
- POBJ is Object of preposition.
Step 7: Clean Text From Any Possible Markup
You can use a Python package for converting raw text in to clean, readable text and extracting metadata from that text. Functionalities include transforming raw text into readable text by removing HTML tags and extracting metadata such as the number of words and named entities from the text.

Step 8: Tokens
Tokenization is the task of splitting a text into meaningful segments, referred to as tokens. The example below is self-explanatory.

Keywords
Also, keywords can be extracted from a block of text. You can configure the environment to be conservative and select only keywords from the text. Or a higher temperature can be set to where related words or keywords are generated.

This is very helpful to categorize text and create a search index. In the image above a extract on soccer was taken from Wikipedia. GPT-3 converted this quite large paragraph into six key words or themes.
Conclusion
There is no magic remedy to make a conversational interface just that; conversational.
It will take time and effort.
But it is important to note that commercially available chatbot solutions should not be seen as a completed and isolated framework by which you need to abide. Additional layers can be introduced to advise the user and inform the chatbot’s basic NLU.
A chatbot must be seen within an organization as a Conversational AI interface and the aim is to further the conversation and give the user guidelines to take the conversation forward.
If the user utterances just bounce off the the chatbot and the user needs to figure out how to approach the conversation, without any guidance, the conversation is bound to be abandoned.
